前言
大家都知道hbase的使用中,最重要的是rowkey的设计。而rowkey的设计中有三个关键点:
1、前缀预防读写热点
2、前缀适合查询场景
3、在满足1、2的前提下,关注索引的存储空间
关于1和2,介绍的文章很多。这篇文章主要分析一下索引的空间利用率,并试图推导出一套具有广泛应用价值的存储压缩思想。
信息的量化
我们先用世界杯的例子介绍一下信息论一个重要的概念 信息量。
2018年的世界杯在俄罗斯举办,有32个国家参赛(为了方便说明,我们将32个国家进行编号1-32)。我们要猜冠军会是哪个国家。假设现在来了一个从未来穿越过来的机器人,它已经知道比赛结果。我们可以向它提问,它可以告诉我们,我们的猜测是“对”还是“错”,不过问它一次要给它一块钱。那么我们要问多少次(花多少钱)才能知道结果呢?
很容易知道,我们问它5次就能知道结果(先猜冠军出现在1-16号,如果猜对,则继续猜1-8号;以此类推),也就是说需要花5块钱。
如果我们对当今足球的格局多一些了解,我们可以猜的更聪明一点:比如我们把巴西、德国、意大利、英格兰、法国、西班牙、葡萄牙少数几个实力强的国家放到一组,其余大多数国家放大另一组,我们可以用更少的次数猜出结果,比如说猜4次(花4元)就能知道结果。省下的一块钱就是源于我们掌握的足球知识,即信息。
信息需要量化,量化的标准不是人名币,而是比特(bit)。猜世界杯冠军的问题包含32种取值的可能性,信息量是log232 = 5 bit.
进制压缩算法
存储压缩的思路是先分析存储的数据所包含的信息量,再看数据实际占用的存储空间。也就是评估存储的空间利用率,分析压缩的理论极限值。
hbase没有字段类型,存储的是byte数组(一般会将rowkey字符串按一定的编码如utf-8进行存储)。rowkey设计中经常包含大量10进制字符组成的子串,如交易号、时间戳等。
一个10进制字符取值有10种可能性,含有的信息量是log210 = 3.3bit. 但一个10进制字符用utf-8编码后需要占用1个字节的存储。空间利用率不到50%。
如果我们能将10进制字符映射成更高的进制,映射成我们熟悉的16进制自然能提高一些空间利用率,因为一个16进制字符的信息量是log216 = 4bit, 有没有更好的方案呢?
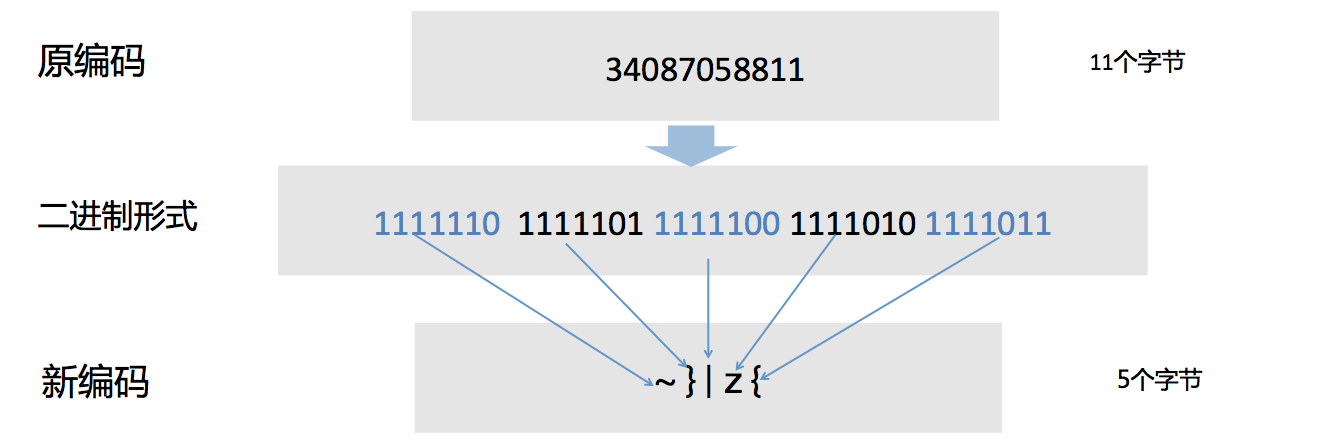
在utf-8中,单字节字符对应ASCII中128个字符,如果能将10进制字符的信息与ASCII码建立联系,就能将10进制转化成128进制,就能做到1个字节存储 log2128 = 7bit的信息。
方法是将10进制字符组成的字串对应的数字转化为2进制形式,然后每7个bit与一个ASCII码对应(ASCII码中128个字符可对应0-127)。
![]()
我们压缩的核心思想是先分析空间利用率(根据数据的信息量和实际占用的空间分析压缩的理论极限值)。然后根据数据的概率分布特征(10进制数字可以认为是0-9等概率分布,如果0-9不是等概率分布并且我们知道它们先验概率的话,可以先使用Huffman进行一次重编码)对数据进行重编码。
优化后,我们将每个字节存储3.3bit的信息提高到存储7bit的信息,空间利用率提高超过50%。
适用场景:适用于那些没有数据类型(或只能以字符串存储)的数据库(如hbase、odps),并且数据中低进制子串(如10进制,16进制)占比较高的场景。
延伸思考
更进一步,我们要问:在以utf-8编码的前提下,我们能不能做到一个字节存储8bit的信息呢?
答案是不能,原因在于utf-8为了解码,部分bit用来标记下一个字符是几个字节编码的。
若字节的bit是以0开头,则该字节会单独解码成一个字符。若字节的bit是以110开头,则该字节连同下一个字节组合解码一个字符。以此类推。
![]()
再进一步,我们要问:在hbase的rowkey中我们存储10进制的数字,为什么要用utf-8来编码,能不能直接存储10进制数字对应的二进制形式组成的byte数组呢?这样对于rowkey中的10进制字符,不是可以做到一个字节存储8bit的信息么?
如果rowkey全部由10进制数字组成,我们可以直接存0进制数字对应的二进制形式组成的byte数组,事实上绝大多数场景,组成rowkey的还有很多非10进制字符(如英文字符),对于这部分字符我们如何存储呢?是转化为unicode对应的数字,还是通过utf-8或者其他编码方式存储?不管怎么存储,解码的复杂度将会大大增加。对于不需要解码rowkey内容的场景,这是一种可选方式。
(备注:这部分的内容与hbase团队的天引同学进行过讨论,对于10进制的子串能否直接存储数字对应的二进制形式组成的byte数组,也是天引同学提出的建议。天引同学在整个优化的过程中给予了我们很大的帮助,在这里表示感谢)
核心代码
![]()
![]()