版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/beliefer/article/details/80981101
提示:阅读本文前最好先阅读《Spark2.1.0之内置RPC框架》和《spark2.1.0之源码分析——RPC配置TransportConf》。
TransportClientFactory是创建传输客户端(TransportClient)的工厂类。在说明《Spark2.1.0之内置RPC框架》文中的图1中的记号①时提到过TransportContext的createClientFactory方法可以创建TransportClientFactory的实例,其实现见代码清单1。
代码清单1 创建客户端工厂
public TransportClientFactory createClientFactory(List<TransportClientBootstrap> bootstraps) {
return new TransportClientFactory(this, bootstraps);
}
public TransportClientFactory createClientFactory() {
return createClientFactory(Lists.<TransportClientBootstrap>newArrayList());
}
可以看到TransportContext中有两个重载的createClientFactory方法,它们最终在构造TransportClientFactory时都会传递两个参数:TransportContext和TransportClientBootstrap列表。TransportClientFactory构造器的实现见代码清单2。
代码清单2 TransportClientFactory的构造器
public TransportClientFactory(
TransportContext context,
List<TransportClientBootstrap> clientBootstraps) {
this.context = Preconditions.checkNotNull(context);
this.conf = context.getConf();
this.clientBootstraps = Lists.newArrayList(Preconditions.checkNotNull(clientBootstraps));
this.connectionPool = new ConcurrentHashMap<>();
this.numConnectionsPerPeer = conf.numConnectionsPerPeer();
this.rand = new Random();
IOMode ioMode = IOMode.valueOf(conf.ioMode());
this.socketChannelClass = NettyUtils.getClientChannelClass(ioMode);
this.workerGroup = NettyUtils.createEventLoop(
ioMode,
conf.clientThreads(),
conf.getModuleName() + "-client");
this.pooledAllocator = NettyUtils.createPooledByteBufAllocator(
conf.preferDirectBufs(), false /* allowCache */, conf.clientThreads());
}
TransportClientFactory构造器中的各个变量分别为:
- context:即参数传递的TransportContext的引用;
- conf:即TransportConf,这里通过调用TransportContext的getConf获取;
- clientBootstraps:即参数传递的TransportClientBootstrap列表;
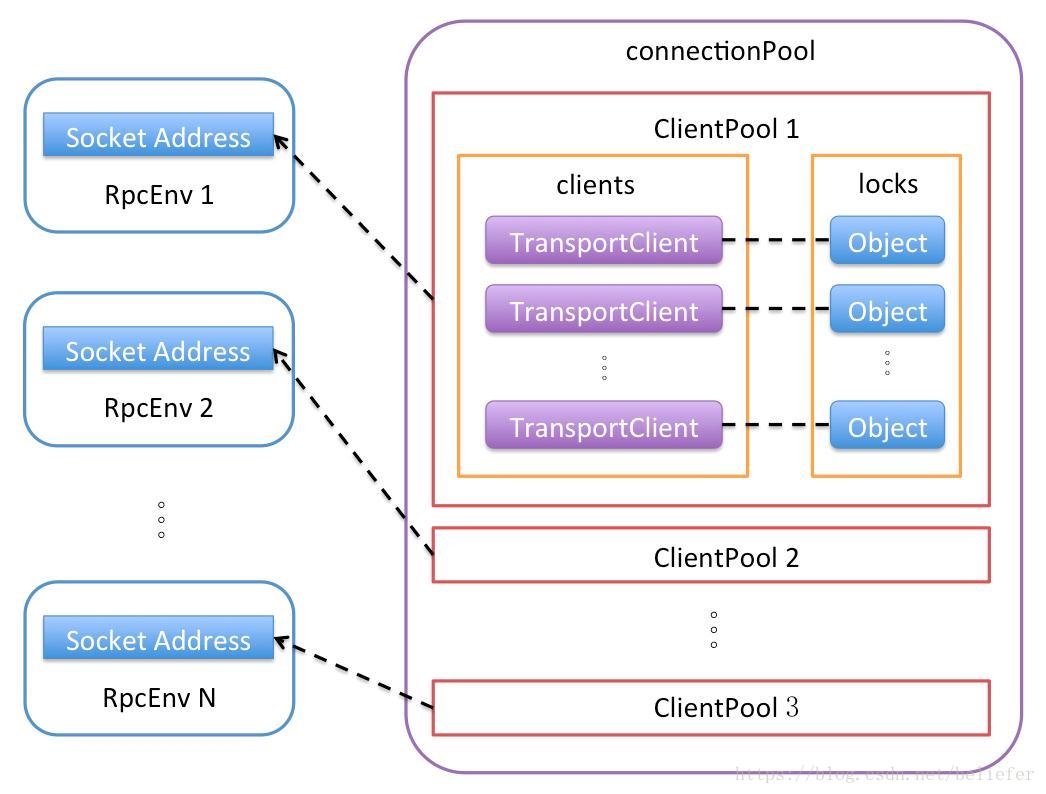
- connectionPool:即针对每个Socket地址的连接池ClientPool的缓存;connectionPool的数据结构较为复杂,为便于读者理解,这里以图1来表示connectionPool的数据结构。
![]()
图1 TransportClientFactory的connectionPool
- numConnectionsPerPeer:即从TransportConf获取的key为”spark.+模块名+.io.numConnectionsPerPeer”的属性值。此属性值用于指定对等节点间的连接数。这里的模块名实际为TransportConf的module字段,Spark的很多组件都利用RPC框架构建,它们之间按照模块名区分,例如RPC模块的key为“spark.rpc.io.numConnectionsPerPeer”;
- rand:对Socket地址对应的连接池ClientPool中缓存的TransportClient进行随机选择,对每个连接做负载均衡;
- ioMode:IO模式,即从TransportConf获取key为”spark.+模块名+.io.mode”的属性值。默认值为NIO,Spark还支持EPOLL;
- socketChannelClass:客户端Channel被创建时使用的类,通过ioMode来匹配,默认为NioSocketChannel,Spark还支持EpollEventLoopGroup;
- workerGroup:根据Netty的规范,客户端只有worker组,所以此处创建workerGroup。workerGroup的实际类型是NioEventLoopGroup;
- pooledAllocator :汇集ByteBuf但对本地线程缓存禁用的分配器。
TransportClientFactory里大量使用了NettyUtils,关于NettyUtils的具体实现,请看《附录G Netty与NettyUtils》。
提示:NIO是指Java中New IO的简称,其特点包括:为所有的原始类型提供(Buffer)缓冲支持;字符集编码解码解决方案;提供一个新的原始I/O 抽象Channel,支持锁和内存映射文件的文件访问接口;提供多路非阻塞式(non-bloking)的高伸缩性网络I/O 。其具体使用属于Java语言的范畴,本文不过多介绍。
客户端引导程序TransportClientBootstrap
TransportClientFactory的clientBootstraps属性是TransportClientBootstrap的列表。TransportClientBootstrap是在TransportClient上执行的客户端引导程序,主要对连接建立时进行一些初始化的准备(例如验证、加密)。TransportClientBootstrap所作的操作往往是昂贵的,好在建立的连接可以重用。TransportClientBootstrap的接口定义见代码清单3。
代码清单3 TransportClientBootstrap的定义
public interface TransportClientBootstrap {
void doBootstrap(TransportClient client, Channel channel) throws RuntimeException;
}
TransportClientBootstrap有两个实现类:EncryptionDisablerBootstrap和SaslClientBootstrap。为了对TransportClientBootstrap的作用能有更深的了解,这里以EncryptionDisablerBootstrap为例,EncryptionDisablerBootstrap的实现见代码清单4。
代码清单4 EncryptionDisablerBootstrap的实现
private static class EncryptionDisablerBootstrap implements TransportClientBootstrap {
@Override
public void doBootstrap(TransportClient client, Channel channel) {
channel.pipeline().remove(SaslEncryption.ENCRYPTION_HANDLER_NAME);
}
}
根据代码清单4,可以看到EncryptionDisablerBootstrap的作用是移除客户端管道中的SASL加密。
创建Rpc客户端TransportClient
有了TransportClientFactory,Spark的各个模块就可以使用它创建RPC客户端TransportClient了。每个TransportClient实例只能和一个远端的RPC服务通信,所以Spark中的组件如果想要和多个RPC服务通信,就需要持有多个TransportClient实例。创建TransportClient的方法见代码清单5(实际为从缓存中获取TransportClient)。
代码清单5 从缓存获取TransportClient
public TransportClient createClient(String remoteHost, int remotePort)
throws IOException, InterruptedException {
// 创建InetSocketAddress
final InetSocketAddress unresolvedAddress =
InetSocketAddress.createUnresolved(remoteHost, remotePort);
ClientPool clientPool = connectionPool.get(unresolvedAddress);
if (clientPool == null) {
connectionPool.putIfAbsent(unresolvedAddress, new ClientPool(numConnectionsPerPeer));
clientPool = connectionPool.get(unresolvedAddress);
}
int clientIndex = rand.nextInt(numConnectionsPerPeer); // 随机选择一个TransportClient
TransportClient cachedClient = clientPool.clients[clientIndex];
if (cachedClient != null && cachedClient.isActive()) {// 获取并返回激活的TransportClient
TransportChannelHandler handler = cachedClient.getChannel().pipeline()
.get(TransportChannelHandler.class);
synchronized (handler) {
handler.getResponseHandler().updateTimeOfLastRequest();
}
if (cachedClient.isActive()) {
logger.trace("Returning cached connection to {}: {}",
cachedClient.getSocketAddress(), cachedClient);
return cachedClient;
}
}
final long preResolveHost = System.nanoTime();
final InetSocketAddress resolvedAddress = new InetSocketAddress(remoteHost, remotePort);
final long hostResolveTimeMs = (System.nanoTime() - preResolveHost) / 1000000;
if (hostResolveTimeMs > 2000) {
logger.warn("DNS resolution for {} took {} ms", resolvedAddress, hostResolveTimeMs);
} else {
logger.trace("DNS resolution for {} took {} ms", resolvedAddress, hostResolveTimeMs);
}
// 创建并返回TransportClient对象
synchronized (clientPool.locks[clientIndex]) {
cachedClient = clientPool.clients[clientIndex];
if (cachedClient != null) {
if (cachedClient.isActive()) {
logger.trace("Returning cached connection to {}: {}", resolvedAddress, cachedClient);
return cachedClient;
} else {
logger.info("Found inactive connection to {}, creating a new one.", resolvedAddress);
}
}
clientPool.clients[clientIndex] = createClient(resolvedAddress);
return clientPool.clients[clientIndex];
}
}
从代码清单5得知,创建TransportClient的步骤如下:
- 调用InetSocketAddress的静态方法createUnresolved构建InetSocketAddress(这种方式创建InetSocketAddress,可以在缓存中已经有TransportClient时避免不必要的域名解析),然后从connectionPool中获取与此地址对应的ClientPool,如果没有则需要新建ClientPool,并放入缓存connectionPool中;
- 根据numConnectionsPerPeer的大小(使用“spark.+模块名+.io.numConnectionsPerPeer”属性配置),从ClientPool中随机选择一个TransportClient;
- 如果ClientPool的clients中在随机产生索引位置不存在TransportClient或者TransportClient没有激活,则进入第5)步,否则对此TransportClient进行第4)步的检查;
- 更新TransportClient的channel中配置的TransportChannelHandler的最后一次使用时间,确保channel没有超时,然后检查TransportClient是否是激活状态,最后返回此TransportClient给调用方;
- 由于缓存中没有TransportClient可用,于是调用InetSocketAddress的构造器创建InetSocketAddress对象(直接使用InetSocketAddress的构造器创建InetSocketAddress,会进行域名解析),在这一步骤多个线程可能会产生竞态条件(由于没有同步处理,所以多个线程极有可能同时执行到此处,都发现缓存中没有TransportClient可用,于是都使用InetSocketAddress的构造器创建InetSocketAddress);
- 第5)步中创建InetSocketAddress的过程中产生的竞态条件如果不妥善处理,会产生线程安全问题,所以到了ClientPool的locks数组发挥作用的时候了。按照随机产生的数组索引,locks数组中的锁对象可以对clients数组中的TransportClient一对一进行同步。即便之前产生了竞态条件,但是在这一步只能有一个线程进入临界区。在临界区内,先进入的线程调用重载的createClient方法创建TransportClient对象并放入ClientPool的clients数组中。当率先进入临界区的线程退出临界区后,其他线程才能进入,此时发现ClientPool的clients数组中已经存在了TransportClient对象,那么将不再创建TransportClient,而是直接使用它。
代码清单5的整个执行过程实际解决了TransportClient缓存的使用以及createClient方法的线程安全问题,并没有涉及创建TransportClient的实现。TransportClient的创建过程在重载的createClient方法(见代码清单6)中实现。
代码清单6 创建TransportClient
private TransportClient createClient(InetSocketAddress address)
throws IOException, InterruptedException {
logger.debug("Creating new connection to {}", address);
// 构建根引导器Bootstrap并对其进行配置
Bootstrap bootstrap = new Bootstrap();
bootstrap.group(workerGroup)
.channel(socketChannelClass)
.option(ChannelOption.TCP_NODELAY, true)
.option(ChannelOption.SO_KEEPALIVE, true)
.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, conf.connectionTimeoutMs())
.option(ChannelOption.ALLOCATOR, pooledAllocator);
final AtomicReference<TransportClient> clientRef = new AtomicReference<>();
final AtomicReference<Channel> channelRef = new AtomicReference<>();
// 为根引导程序设置管道初始化回调函数
bootstrap.handler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) {
TransportChannelHandler clientHandler = context.initializePipeline(ch);
clientRef.set(clientHandler.getClient());
channelRef.set(ch);
}
});
long preConnect = System.nanoTime();
ChannelFuture cf = bootstrap.connect(address);// 使用根引导程序连接远程服务器
if (!cf.await(conf.connectionTimeoutMs())) {
throw new IOException(
String.format("Connecting to %s timed out (%s ms)", address, conf.connectionTimeoutMs()));
} else if (cf.cause() != null) {
throw new IOException(String.format("Failed to connect to %s", address), cf.cause());
}
TransportClient client = clientRef.get();
Channel channel = channelRef.get();
assert client != null : "Channel future completed successfully with null client";
// Execute any client bootstraps synchronously before marking the Client as successful.
long preBootstrap = System.nanoTime();
logger.debug("Connection to {} successful, running bootstraps...", address);
try {
for (TransportClientBootstrap clientBootstrap : clientBootstraps) {
clientBootstrap.doBootstrap(client, channel);// 给TransportClient设置客户端引导程序
}
} catch (Exception e) { // catch non-RuntimeExceptions too as bootstrap may be written in Scala
long bootstrapTimeMs = (System.nanoTime() - preBootstrap) / 1000000;
logger.error("Exception while bootstrapping client after " + bootstrapTimeMs + " ms", e);
client.close();
throw Throwables.propagate(e);
}
long postBootstrap = System.nanoTime();
logger.info("Successfully created connection to {} after {} ms ({} ms spent in bootstraps)",
address, (postBootstrap - preConnect) / 1000000, (postBootstrap - preBootstrap) / 1000000);
return client;
}
从代码清单6得知,真正创建TransportClient的步骤如下:
- 构建根引导器Bootstrap并对其进行配置;
- 为根引导程序设置管道初始化回调函数,此回调函数将调用TransportContext的initializePipeline方法初始化Channel的pipeline;
- 使用根引导程序连接远程服务器,当连接成功对管道初始化时会回调初始化回调函数,将TransportClient和Channel对象分别设置到原子引用clientRef与channelRef中;
- 给TransportClient设置客户端引导程序,即设置TransportClientFactory中的TransportClientBootstrap列表;
- 最后返回此TransportClient对象。
关于《Spark内核设计的艺术 架构设计与实现》
经过近一年的准备,《
Spark内核设计的艺术 架构设计与实现》一书现已出版发行,图书如图: