1.概述
大数据时代,数据的存储与挖掘至关重要。企业在追求高可用性、高扩展性及高容错性的大数据处理平台的同时还希望能够降低成本,而Hadoop为实现这些需求提供了解决方案。面对Hadoop的普及和学习热潮,笔者愿意分享自己多年的开发经验,带领读者比较轻松地掌握Hadoop数据挖掘的相关知识。这边是笔者编写本书的原因。本书使用通俗易懂的语言进行讲解,从基础部署到集群管理,再到底层设计等内容均由涉及。通过阅读本书,读者可以较为轻松地掌握Hadoop大数据挖掘与分析的相关技术。
本书目前已在网上商城上架,可以通过京东自营,当当自营,亚马逊自营等网上商城进行购买。书籍封面如下:
![]()
2.本书内容
本书采用“理论+实战”的形式编写,通过大量的实例,结合作者多年一线开发实战经验,全面的介绍了Hadoop的使用方法。全书设计秉承方便学习、易于理解、便于查询的理念,无论是刚入门的初学者系统的学习Hadoop的基础知识,还是拥有多年开发经验的开发者想学习Hadoop,都能通过本书迅速掌握Hadoop的各种基础语法和实战技巧。本书作者曾经与极客学院合作,拥有丰富的教学视频制作经验,为读者精心录制了详细的视频介绍。本书还免费提供所有案例的源码,为读者的学习和工作提供更多的便利。
本书分为13章,分别介绍Hadoop平台管理与维护、异常处理解决方案以及Hadoop的分布式文件系统等内容。最后一章对Hadoop进行了拓展,剖析了Kafka消息系统并介绍了笔者的开源监控系统Kafka Eagle。
本书结构清晰、案例丰富、通俗易懂、实用性强。特别适合初学者自学和进阶读者查询及参考。另外,本书也适合社会培训学校作为培训教材使用,还适合大中专院校的相关专业作为教学参考书。
3.本书特色
3.1 提供专业的配套教学视频,高效、直观
笔者曾接受过极客学院的专业视频制作指导,并在极客学院录制过多期Hadoop和Kafka实战教学视频课程,得到了众多学习者的青睐及好评。为了便于读者更加高效、直观地学习本书内容,笔者特意为本书实战部分的内容录制了配套教学视频,读者可以在教学视频的辅助下学习,从而更加轻松地掌握Hadoop。
3.2 来自一线的开发经验及实战例子
本书给出的代码讲解和实例大多数来自于笔者多年的教学积累和技术分享,几乎都是得到了学习者一致好评的干活。另外,笔者还是一名开源爱好者,编写了业内著名的Kafka Eagle监控系统。本书第13章介绍了该系统的使用,以帮助读者掌握如何监控大数据集群的相关知识。
3.3 浅显易懂的语言、触类旁通的对比、循序渐进的知识体系
本书在文字及目录编排上,尽量做到通俗易懂。在讲解一些常见的知识点时,将Hadoop命令与Linux命令做对比,掌握Linux命令的开发者能够迅速掌握Hadoop的操作命令。无论是初学者,还是久经沙场的老程序员都能快速通过本书学习Hadoop的精华之处。
3.4 内容全面,实用性强
本书精心挑选了多个实用性很强的例子,例如:Hadoop套件实战、Hive 编程、Hadoop平台管理与维护、ELK实战、Kafka实战等。读者既可以从例子中学习并理解Hadoop及其套件知识点,还可以将这些例子用于开发中。
4. 示例代码
本书的所有示例都封装在该项目中,读者可以下载该工程的源代码来对照书中的内容进行学习。由于本工程采用的是Maven来进行管理,所以在需要编译打包时,可以直接只用mvn命令,或者执行./build.sh脚本来实现打包。
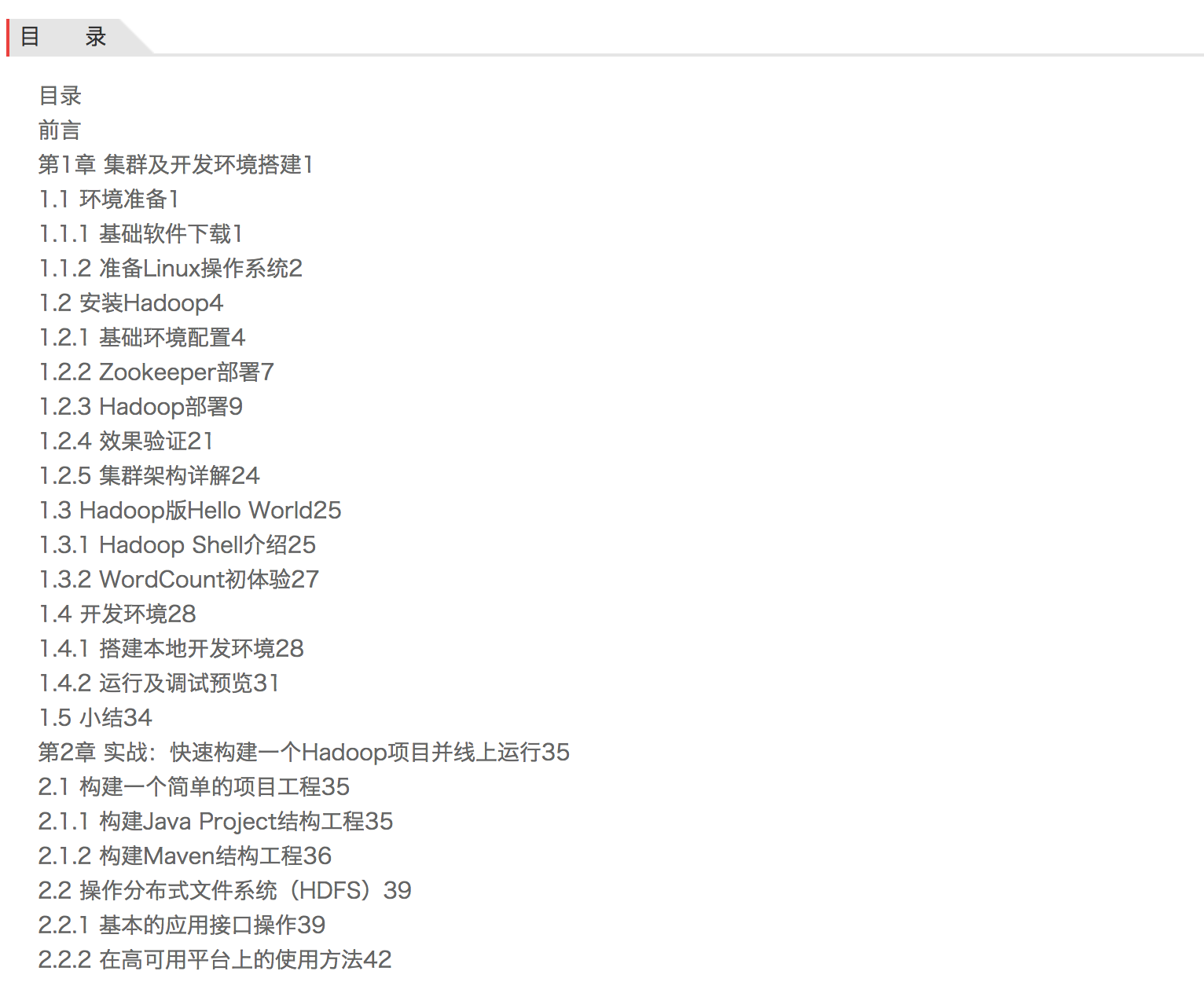
5. 书籍目录部分预览
![]()
6. 读者对象
学习Hadoop没有想象中的那么困难,本书通过将一些Hadoop难懂的知识点,通过通俗易懂的语言进行概述,来减少读者的学习成本,让读者轻轻松松地掌握Hadoop的相关知识。适用范围但不仅仅包含以下:
- Hadoop初学者
- Hadoop进阶人员
- 后端程序初学者
- 前端转后端的开发人员
- 熟悉Linux操作系统以及有编程语言基础的
- 学习Hadoop的编程爱好者
7. 总结
最后,衷心希望笔者编写的这本书能够帮助到对Hadoop感兴趣、学习Hadoop的同学。希望阅读过本书的同学能够掌握Hadoop相关知识,希望笔者书中的经验和总结能够帮助读者少走弯路,在Hadoop学习之路上游刃有余。
8.结束语
感兴趣的同学可以购买本书,如果在学习本书的内容中遇到任何疑问,可以通过下面的联系方式进行邮件留言或者加入Hadoop学习讨论群,笔者会尽我所能,帮您解答,与君共勉!
作者:哥不是小萝莉 [关于我][犒赏]
转载请注明出处,谢谢合作!