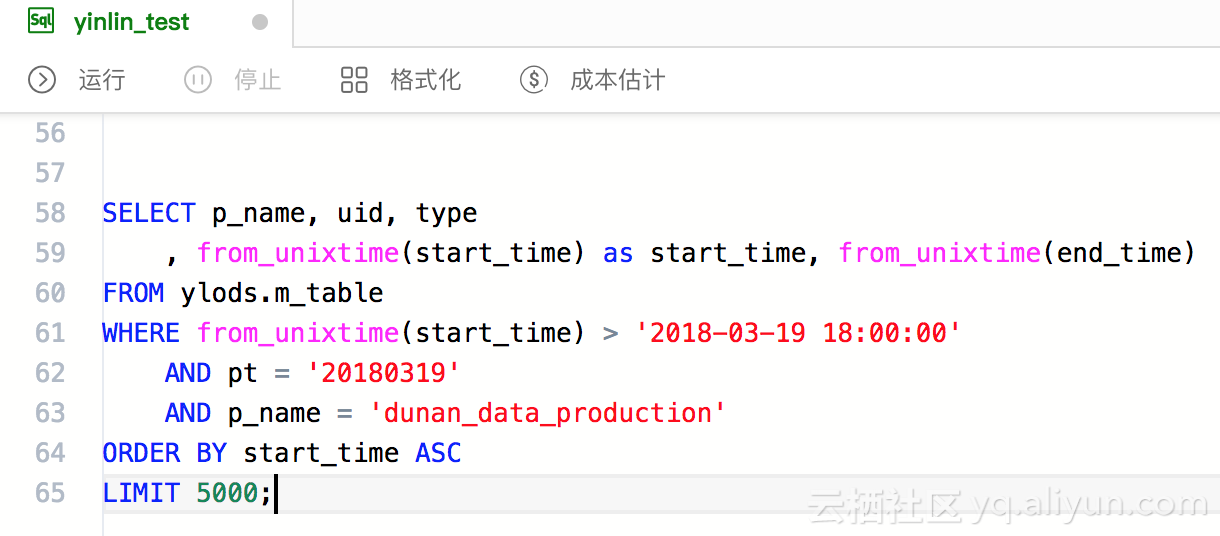
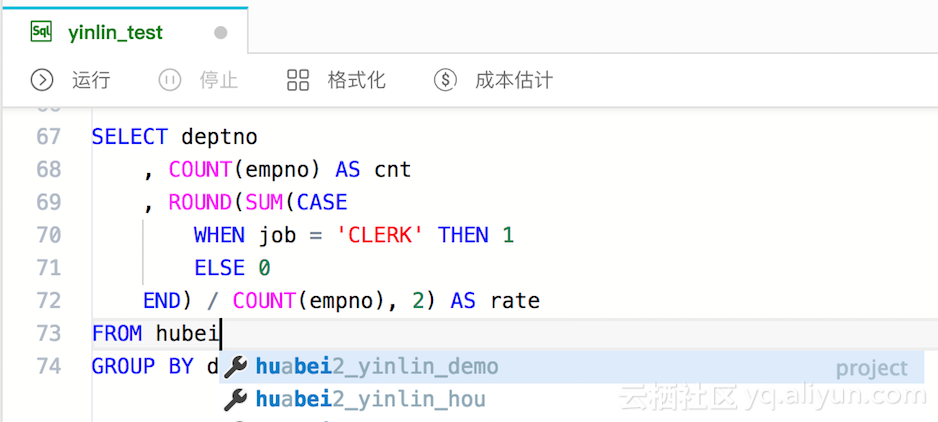
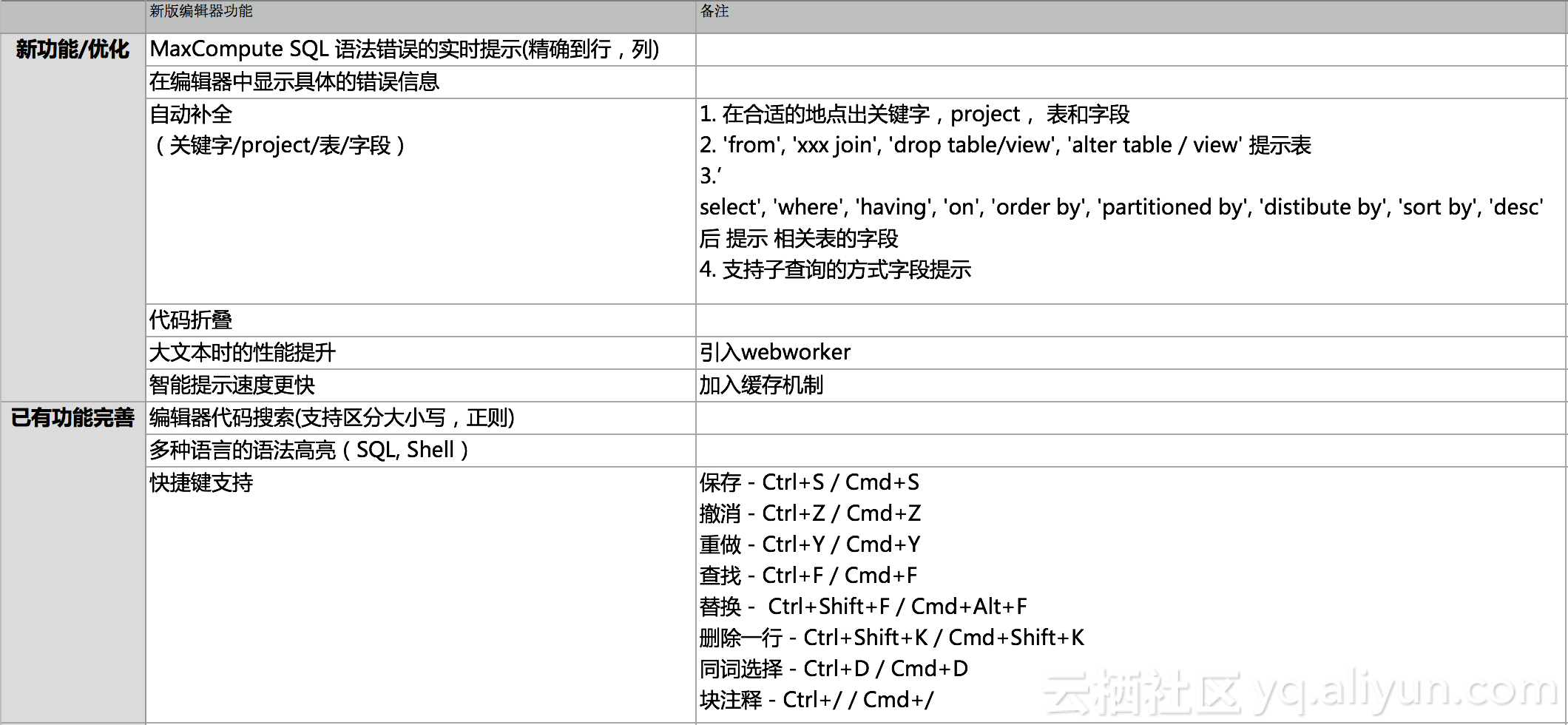

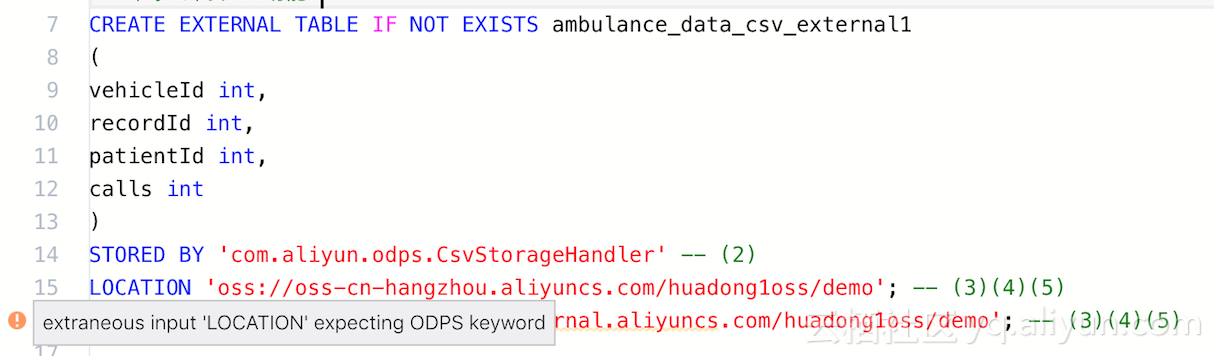

Databricks缓存提升Spark性能--为什么NVMe固态硬盘能够提升10倍缓存性能(原创翻译)
我们兴奋的宣布Databricks缓存的通用可用性,作为统一分析平台一部分的 Databricks 运行时特性,它可以将Spark工作负载的扫描速度提升10倍,并且这种改变无需任何代码修改。 1、在本博客中,我们将介绍这个新特性的两个主要特点:易用性和性能。 2、不同于Spark显示缓存,Databricks缓存能够自动地为用户缓存热输入数据,并且在集群中负载均衡。利用NVMe SSD硬件的先进性能和最先进的压缩技术,它能够将交互式和报告工作的负载性能提升10倍。更重要的是它缓存的数据量是Spark的缓存数量的30多倍。 Spark显式缓存 Spark中一个关键特性是显式缓存。它是一个多功能的工具,因为它可以用于存放任意计算结果(包括输入和中间结果),以便它们可以重复使用。例如,迭代机器学习算法的实现可以选择缓存特征化数据,并且每次迭代将从内存中读取这些数据。 一种特别重要和广泛使用的方式就是缓存扫描操作的结果。通过这种方式可以避免用户低速率地读取远程数据。因此,许多打算重复运行相同或类似工作量的用户决定花费额外的开发时间来手动优化他们的应用程序,通过指示Spark确切缓存什么文件以及...