简介:
一、下载zip包。
下面有附件链接【ik-安装包.zip】,下载即可。
二、上传zip包。
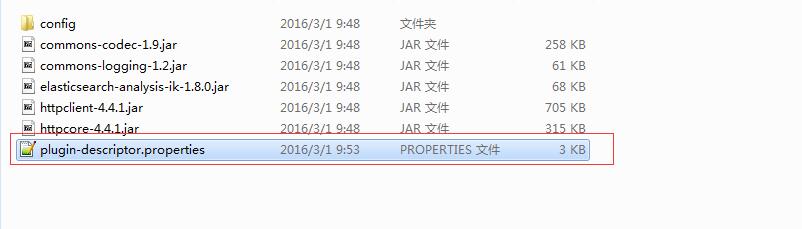
下载后解压缩,如下图。
![7386405912]()
打开修改修改好后打成zip包。
# 'elasticsearch.version' version of elasticsearch compiled against# You will have to release a new version of the plugin for each new# elasticsearch release. This version is checked when the plugin# is loaded so Elasticsearch will refuse to start in the presence of# plugins with the incorrect elasticsearch.version.#把这个版本号改成你对应的版本即可,如你的版本是2.2.0,就改成2.2.0elasticsearch.version=2.0.0
/elasticsearch-2.0.0/plugins
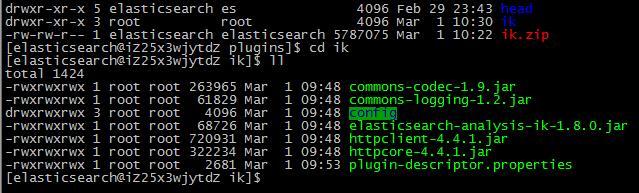
在plugins/目录下上传,并且解压缩。此处注意目录结构必须是这样,如下图:
![4693812507]()
三、启动测试
呃,我们发现报错了。
[elasticsearch@iZ25x3wjytdZ elasticsearch-2.0.0]$ ./bin/elasticsearch[2016-03-01 10:32:02,958][INFO ][node ] [Landslide] version[2.0.0], pid[11109], build[de54438/2015-10-22T08:09:48Z][2016-03-01 10:32:02,959][INFO ][node ] [Landslide] initializing ...Exception in thread "main" java.lang.IllegalStateException: Unable to initialize pluginsLikely root cause: java.nio.file.FileSystemException: /home/elasticsearch/es/elasticsearch-2.0.0/plugins/ik.zip/plugin-descriptor.properties: Not a directory at sun.nio.fs.UnixException.translateToIOException(UnixException.java:91) at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:102) at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:107) at sun.nio.fs.UnixFileSystemProvider.newByteChannel(UnixFileSystemProvider.java:214) at java.nio.file.Files.newByteChannel(Files.java:317) at java.nio.file.Files.newByteChannel(Files.java:363) at java.nio.file.spi.FileSystemProvider.newInputStream(FileSystemProvider.java:380) at java.nio.file.Files.newInputStream(Files.java:108) at org.elasticsearch.plugins.PluginInfo.readFromProperties(PluginInfo.java:86) at org.elasticsearch.plugins.PluginsService.getPluginBundles(PluginsService.java:306) at org.elasticsearch.plugins.PluginsService.(PluginsService.java:112) at org.elasticsearch.node.Node.(Node.java:144) at org.elasticsearch.node.NodeBuilder.build(NodeBuilder.java:145) at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:170) at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:270) at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:35)
一看我们就知道,他去找plugins/ik.zip 下的配置文件对吧。
解决方案是把这个ZIP包删除即可。
删除后再次启动。
[elasticsearch@iZ25x3wjytdZ elasticsearch-2.0.0]$ ./bin/elasticsearch[2016-03-01 10:32:02,958][INFO ][node ] [Landslide] version[2.0.0], pid[11109], build[de54438/2015-10-22T08:09:48Z][2016-03-01 10:32:02,959][INFO ][node ] [Landslide] initializing ...Exception in thread "main" java.lang.IllegalStateException: Unable to initialize pluginsLikely root cause: java.nio.file.FileSystemException: /home/elasticsearch/es/elasticsearch-2.0.0/plugins/ik.zip/plugin-descriptor.properties: Not a directory at sun.nio.fs.UnixException.translateToIOException(UnixException.java:91) at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:102) at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:107) at sun.nio.fs.UnixFileSystemProvider.newByteChannel(UnixFileSystemProvider.java:214) at java.nio.file.Files.newByteChannel(Files.java:317) at java.nio.file.Files.newByteChannel(Files.java:363) at java.nio.file.spi.FileSystemProvider.newInputStream(FileSystemProvider.java:380) at java.nio.file.Files.newInputStream(Files.java:108) at org.elasticsearch.plugins.PluginInfo.readFromProperties(PluginInfo.java:86) at org.elasticsearch.plugins.PluginsService.getPluginBundles(PluginsService.java:306) at org.elasticsearch.plugins.PluginsService.(PluginsService.java:112) at org.elasticsearch.node.Node.(Node.java:144) at org.elasticsearch.node.NodeBuilder.build(NodeBuilder.java:145) at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:170) at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:270) at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:35)
我们从启动就看的出来,IK分词器安装成功。
[2016-03-01 10:34:28,803][INFO ][plugins ] [Big Wheel] loaded [analysis-ik], sites [head]
测试:
http://123.57.163.79:9200/_analyze?analyzer=ik&pretty=true&text=sojson在线工具真好用
{ "tokens" : [ { "token" : "sojson", "start_offset" : 0, "end_offset" : 6, "type" : "ENGLISH", "position" : 0 }, { "token" : "在线", "start_offset" : 6, "end_offset" : 8, "type" : "CN_WORD", "position" : 1 }, { "token" : "工具", "start_offset" : 8, "end_offset" : 10, "type" : "CN_WORD", "position" : 2 }, { "token" : "真好", "start_offset" : 10, "end_offset" : 12, "type" : "CN_WORD", "position" : 3 }, { "token" : "好用", "start_offset" : 11, "end_offset" : 13, "type" : "CN_WORD", "position" : 4 } ]}
得出Over 。
分词器下载地址:http://down.51cto.com/data/2323000
本文转自yushiwh 51CTO博客,原文链接:http://blog.51cto.com/yushiwh/1942627,如需转载请自行联系原作者