

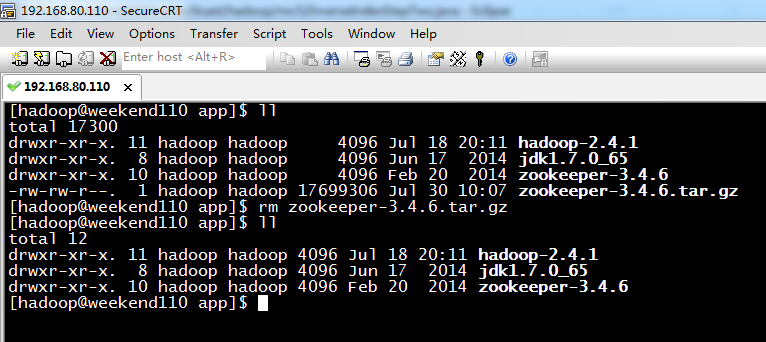
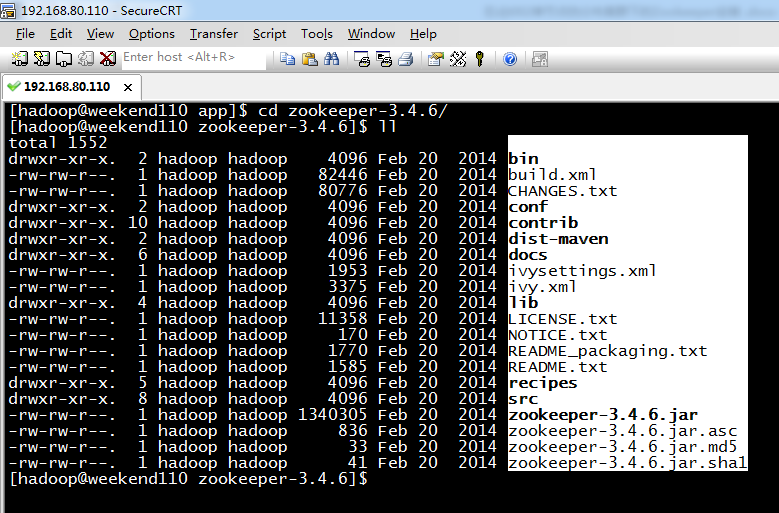
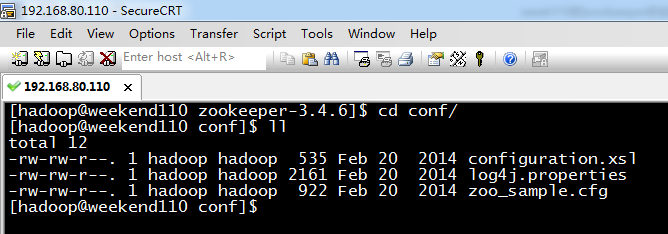
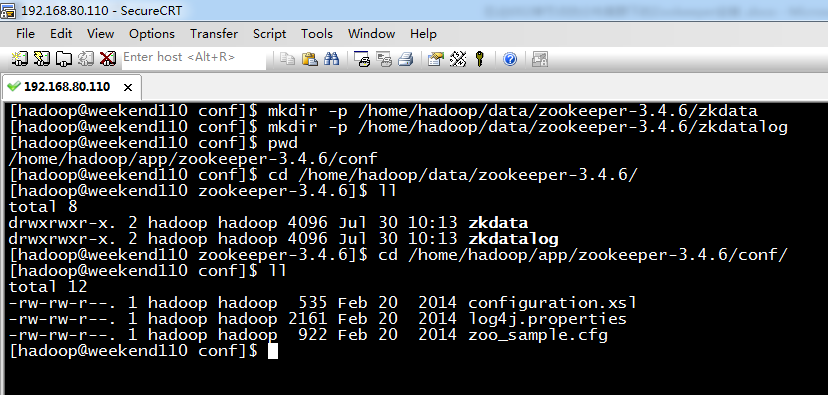
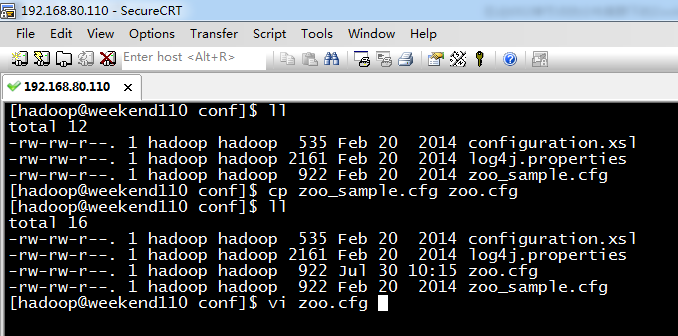
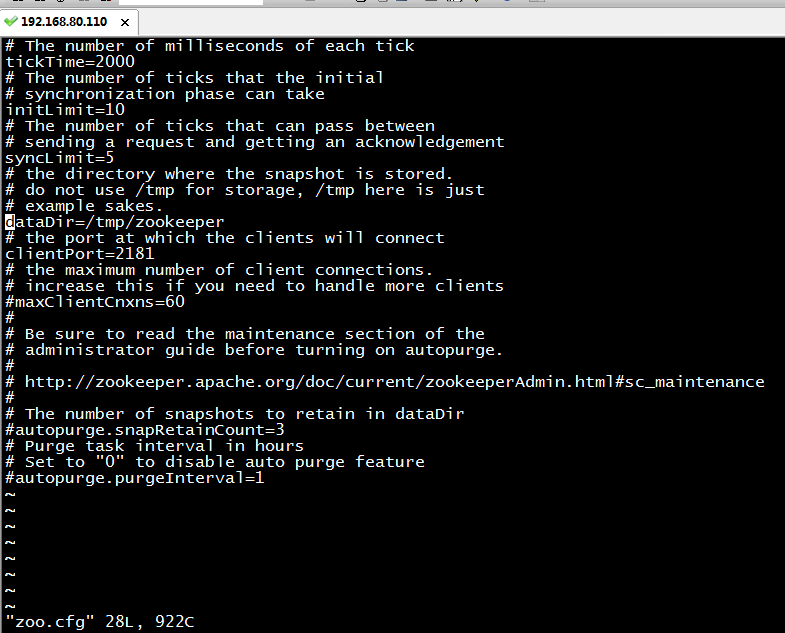
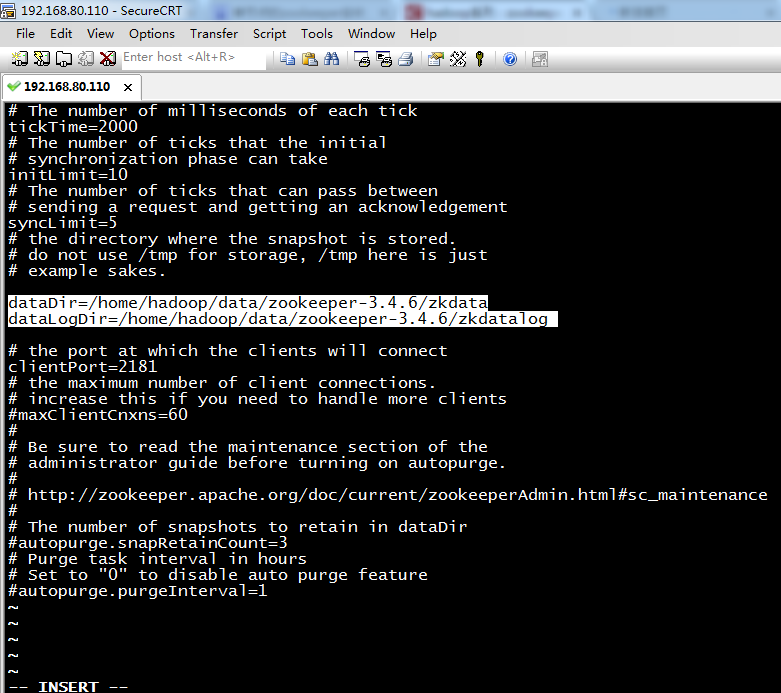
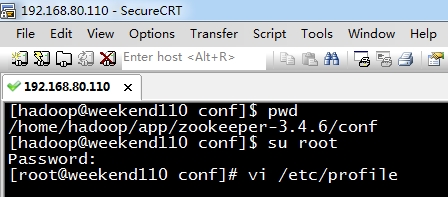

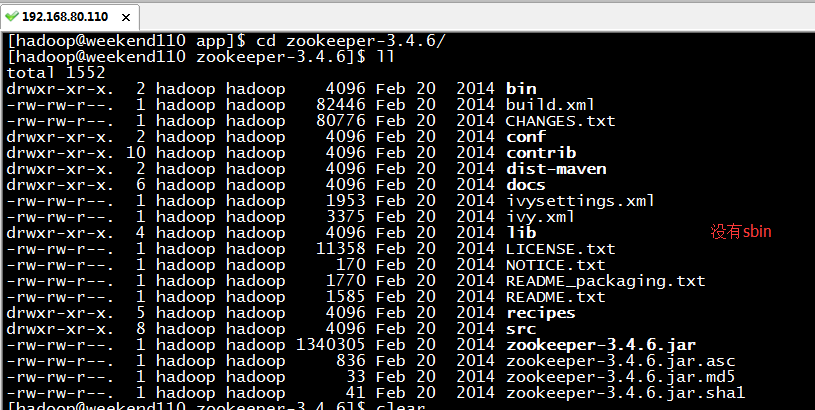

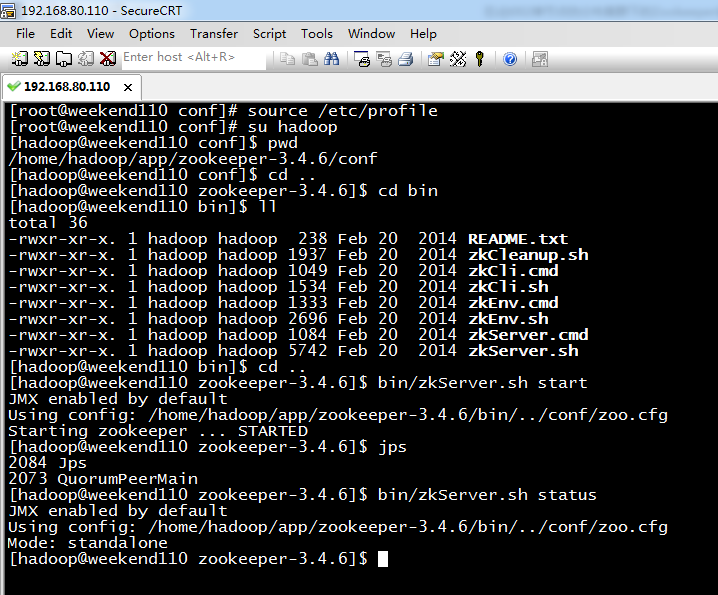
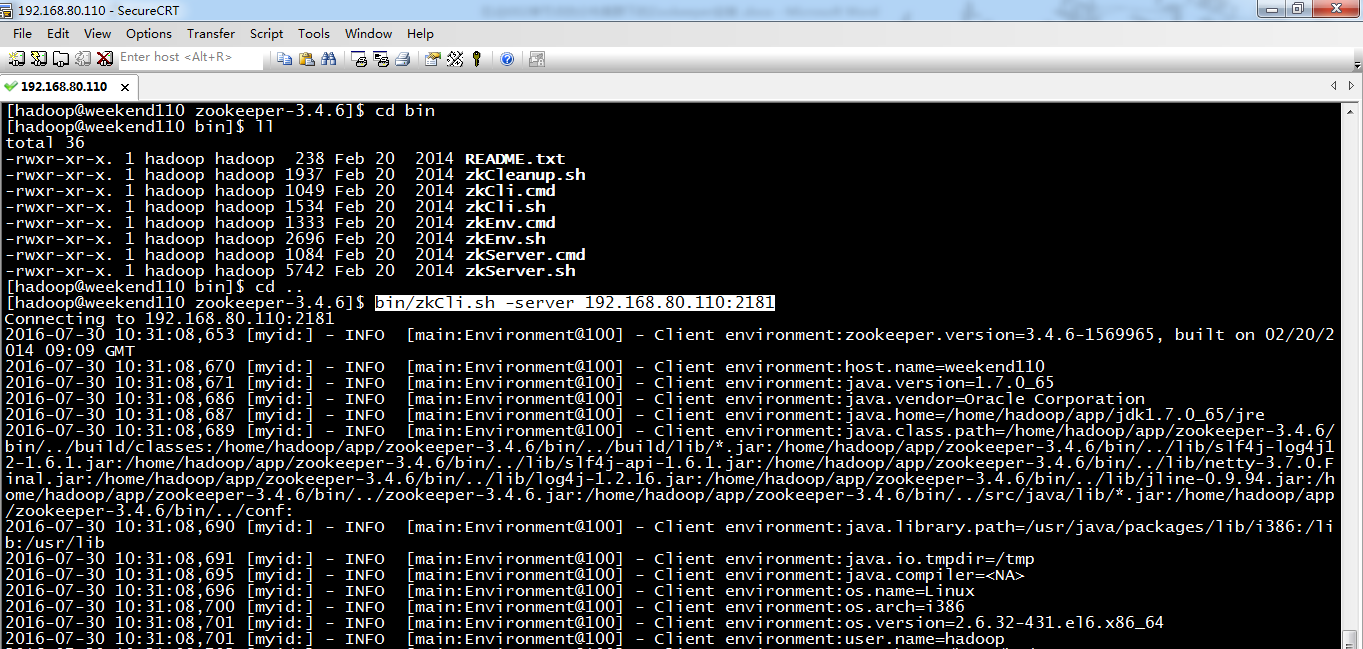
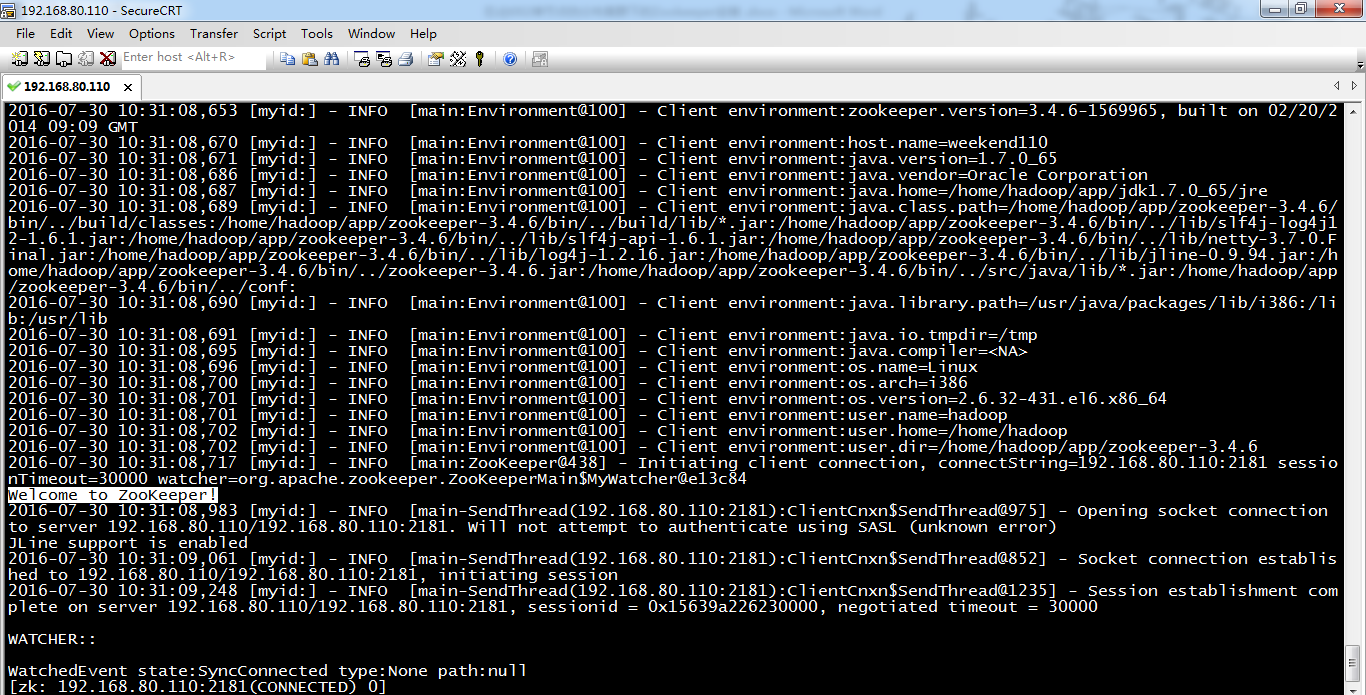



5 weekend01、02、03、04、05、06、07的分布式集群的HA测试 + hdfs--动态增加节点和副本数量管理 + HA的ja...
eekend01、02、03、04、05、06、07的分布式集群的HA测试 1) weekend01、02的hdfs的HA测试 2) weekend03、04的yarn的HA测试 1) weekend01、02的hdfs的HA测试 首先,分布式集群都是正常的,且工作的 然后呢, 以上是,weekend01(active)、weekend02(standby) 当weekend01给kill, 变成weekend01(standby)、weekend02(active) 模拟weekend02断电 以上是weekend01(standby)、weekend02(active) 当weekend02断电后,再启动 weekend01(active)、weekend02(standby) 以上是weekend01(active)、weekend02(standby) 当weekend01在传文件时,weekend02杀掉namenode进程, 依然还是weekend01(active)、weekend02(standby) 以上是weekend01、02的hdfs...