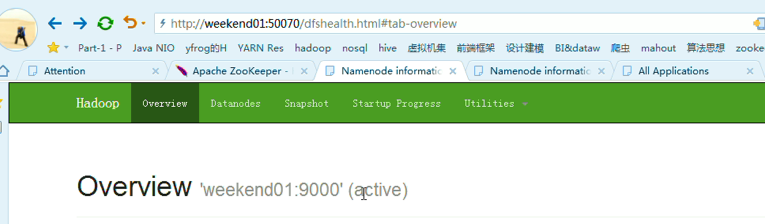
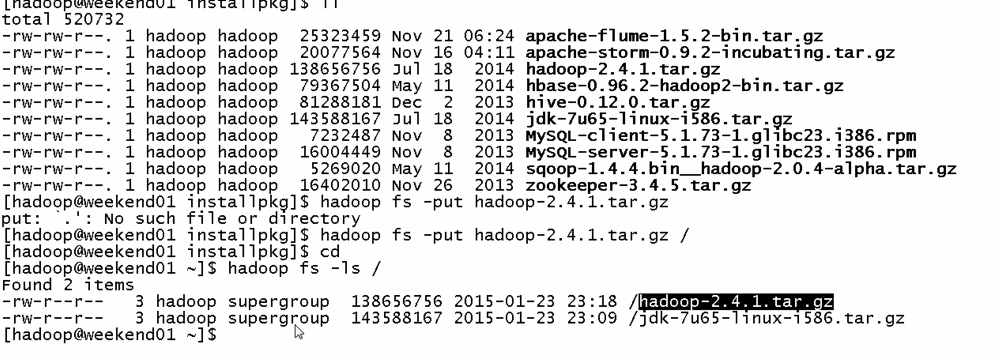
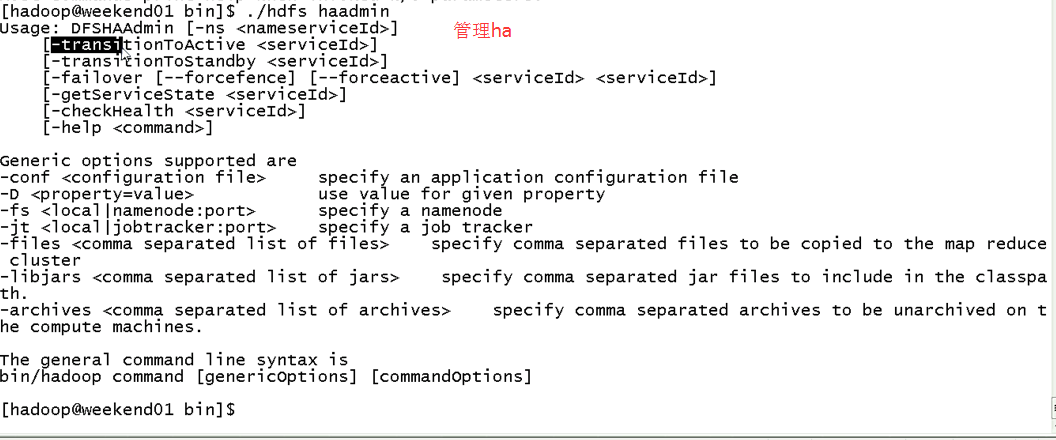
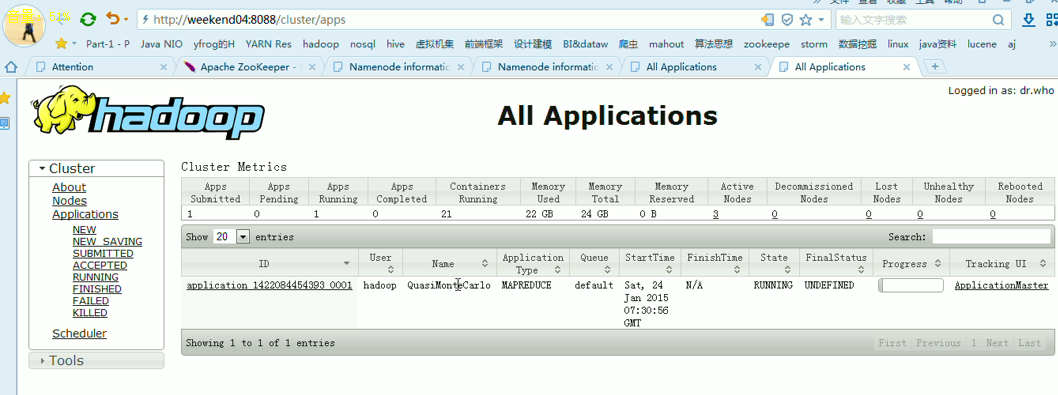
eekend01、02、03、04、05、06、07的分布式集群的HA测试
1) weekend01、02的hdfs的HA测试
2) weekend03、04的yarn的HA测试
1) weekend01、02的hdfs的HA测试
![]()
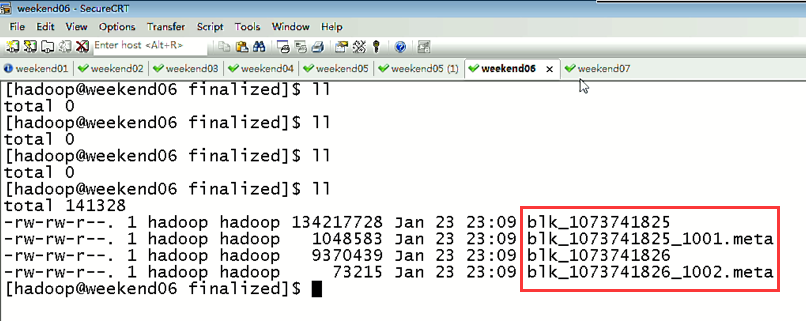
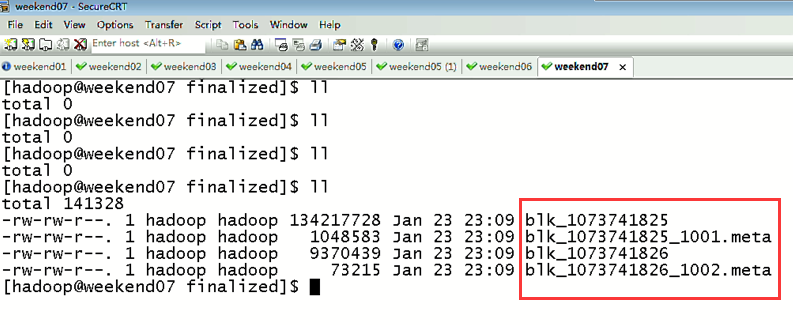
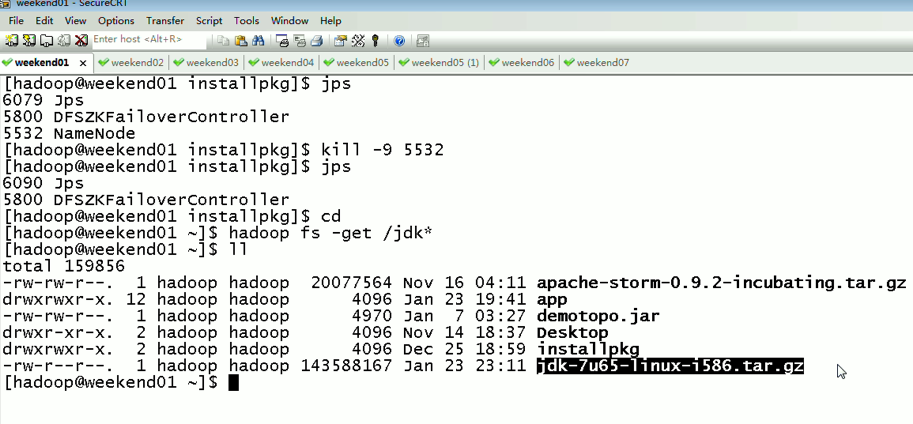
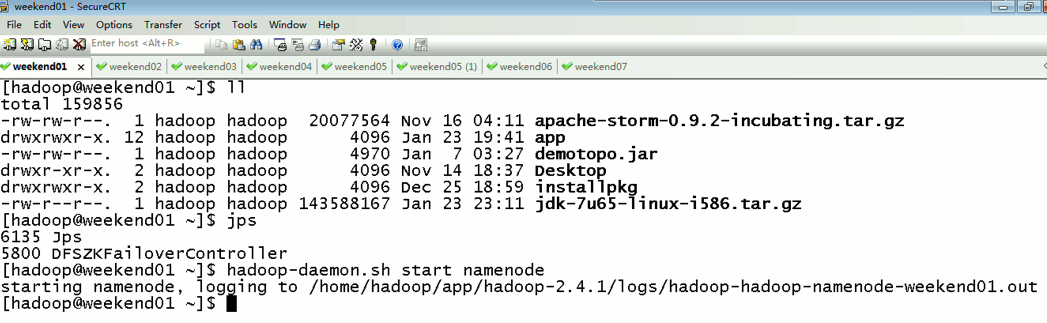
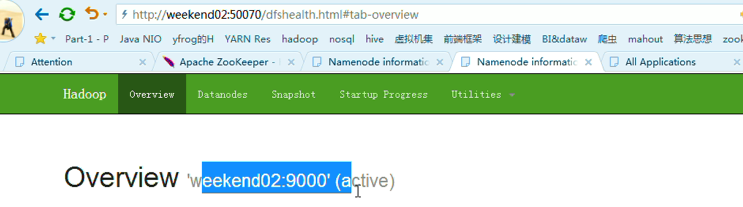
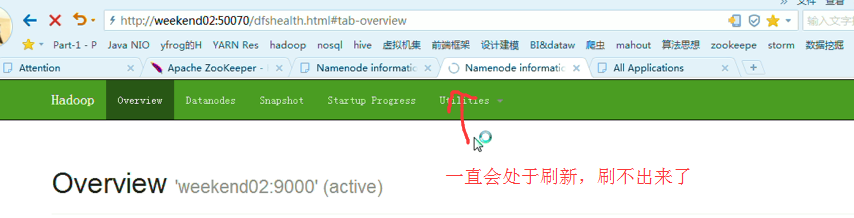
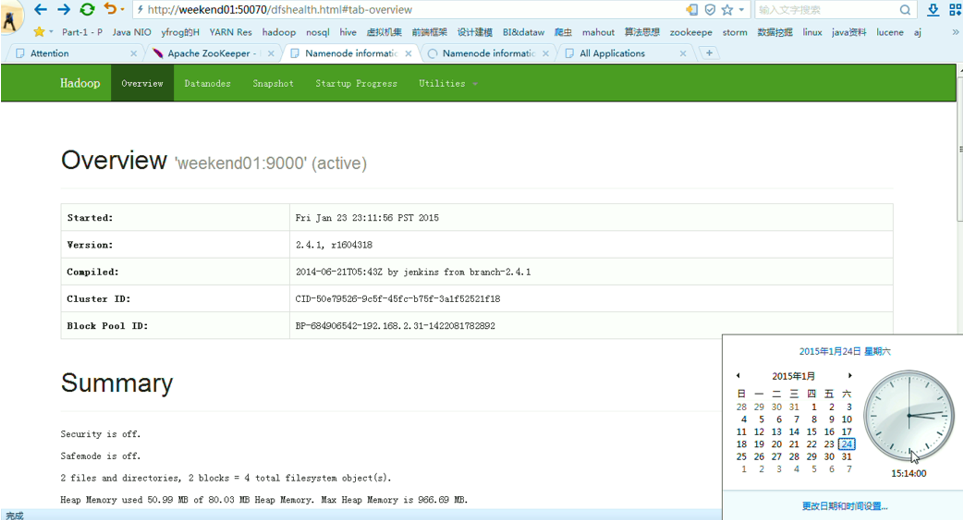
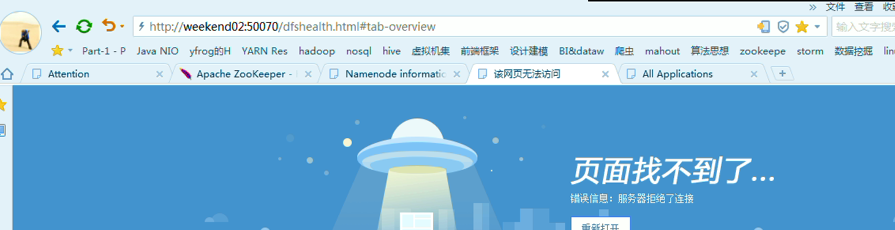
首先,分布式集群都是正常的,且工作的
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
然后呢,
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
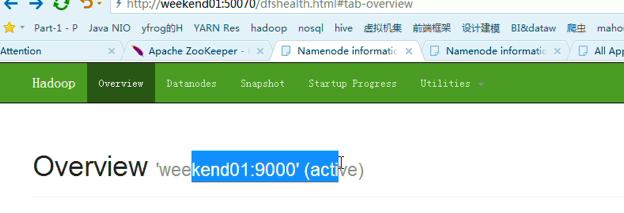
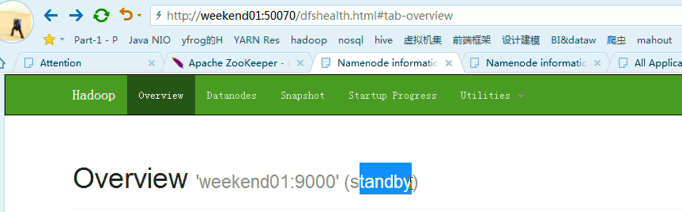
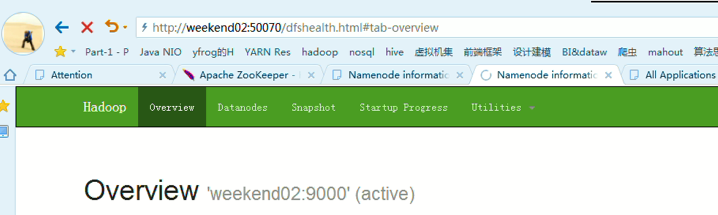
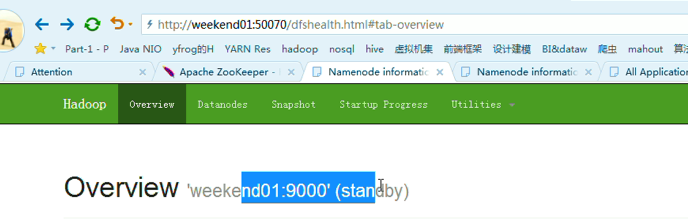
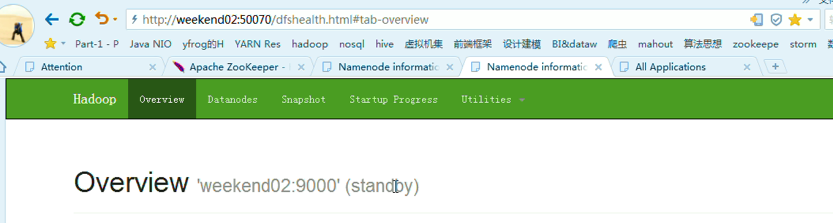
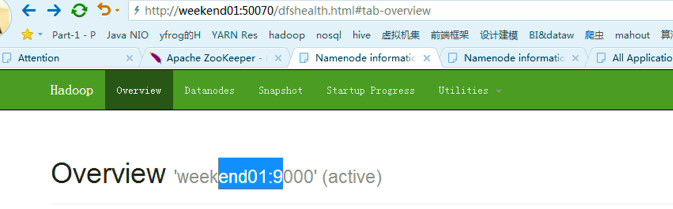
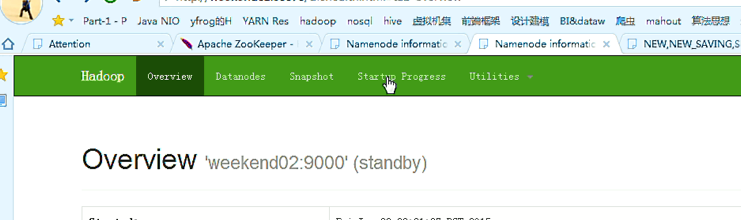
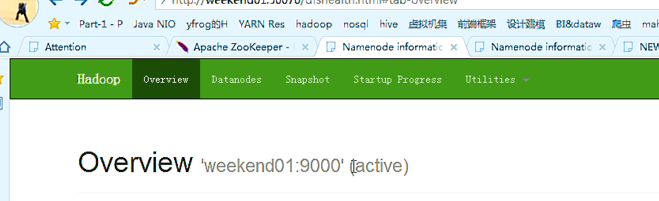
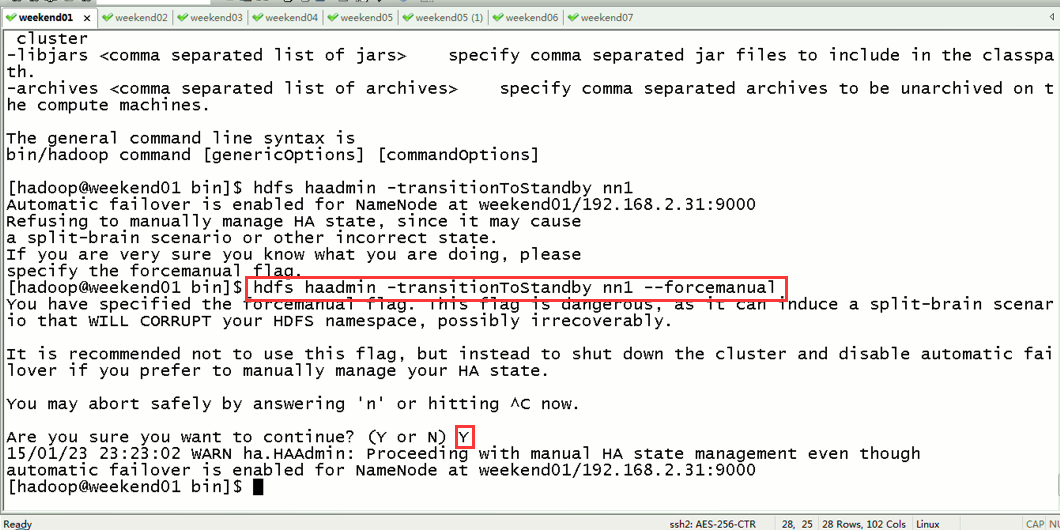
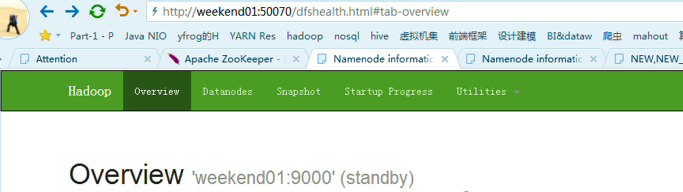
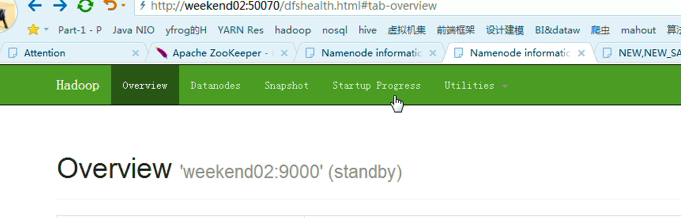
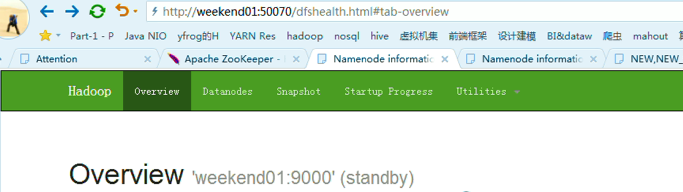
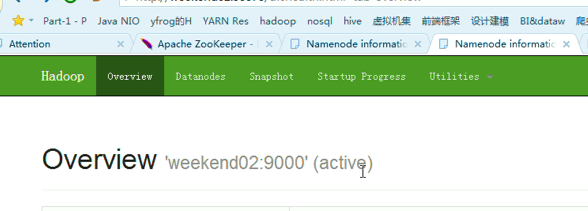
以上是,weekend01(active)、weekend02(standby)
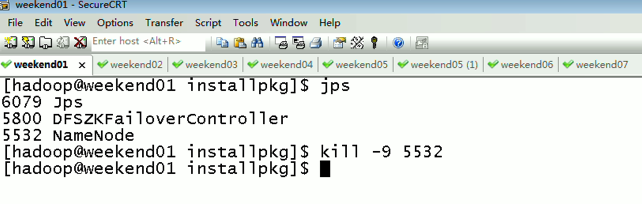
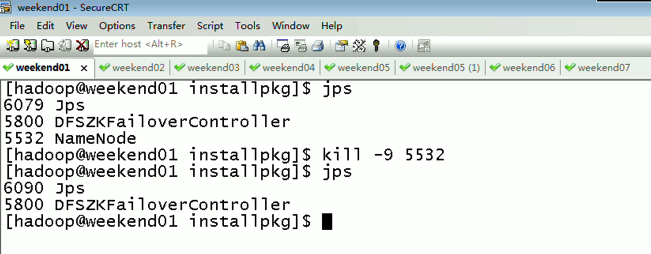
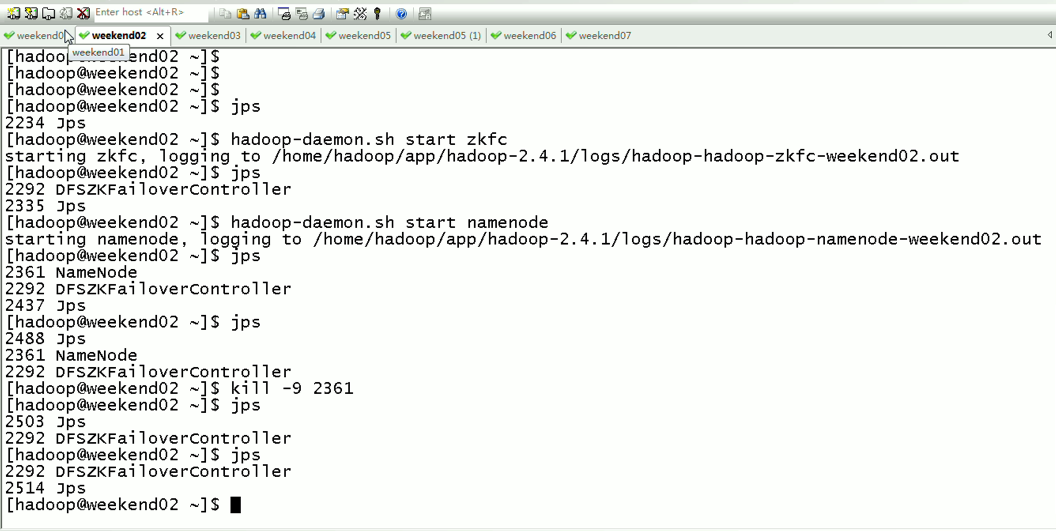
当weekend01给kill,
变成weekend01(standby)、weekend02(active)
![]()
![]()
![]()
![]()
模拟weekend02断电
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
以上是weekend01(standby)、weekend02(active)
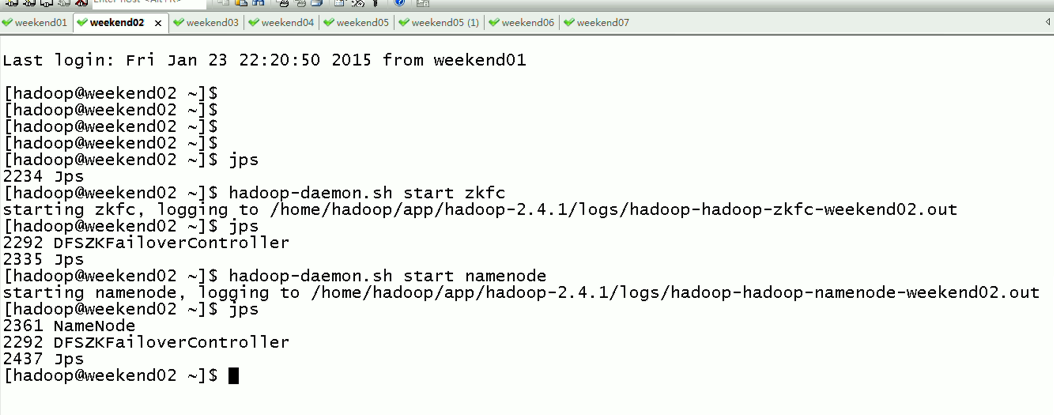
当weekend02断电后,再启动
weekend01(active)、weekend02(standby)
![]()
![]()
![]()
![]()
![]()
![]()
以上是weekend01(active)、weekend02(standby)
当weekend01在传文件时,weekend02杀掉namenode进程,
依然还是weekend01(active)、weekend02(standby)
以上是weekend01、02的hdfs的HA测试
下面,
![]()
![]()
![]()
![]()
![]()
![]()
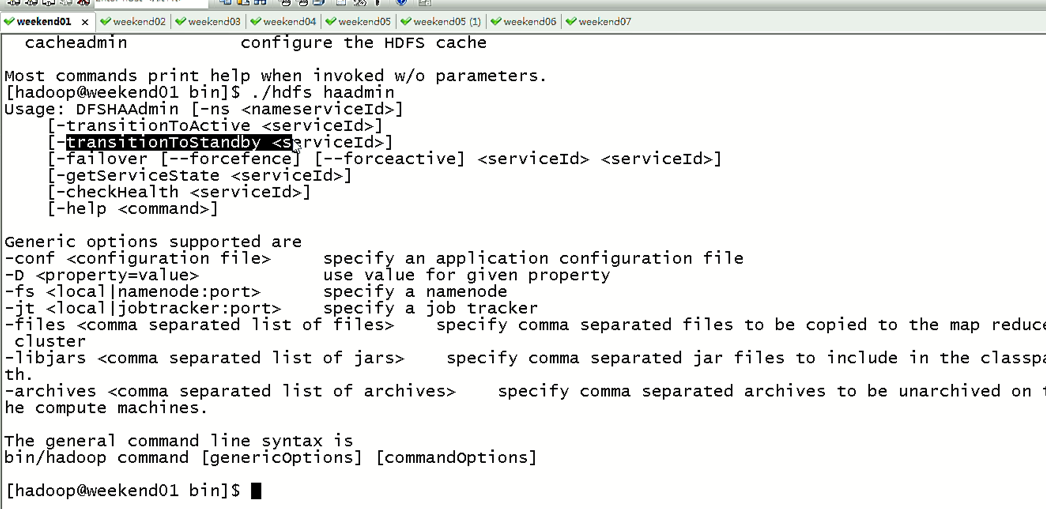
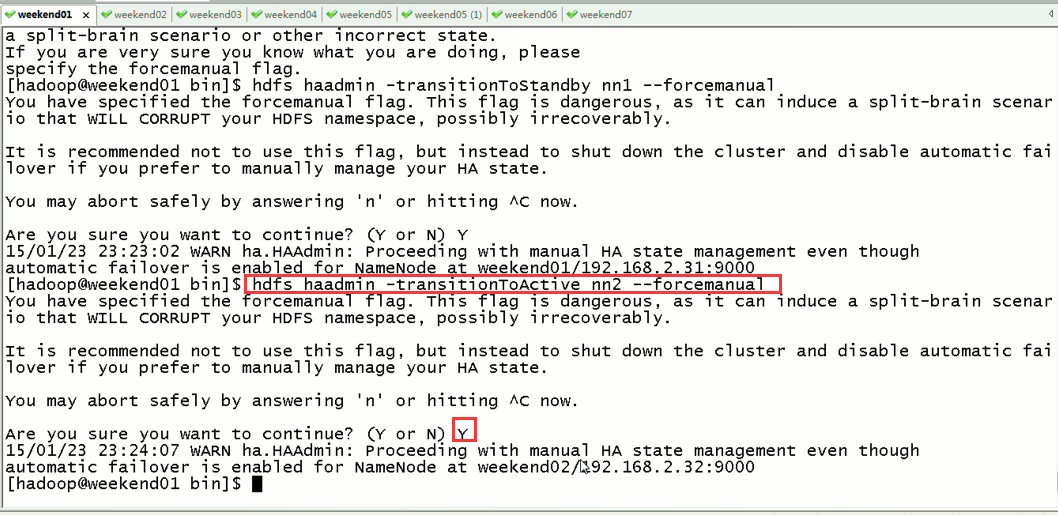
现在,用指令来切换
![]()
![]()
![]()
![]()
这样,是告诉我们,有时候会碰到,如weekend01、02都是standby时,来命令将其中一个切换成active
![]()
![]()
![]()
![]()
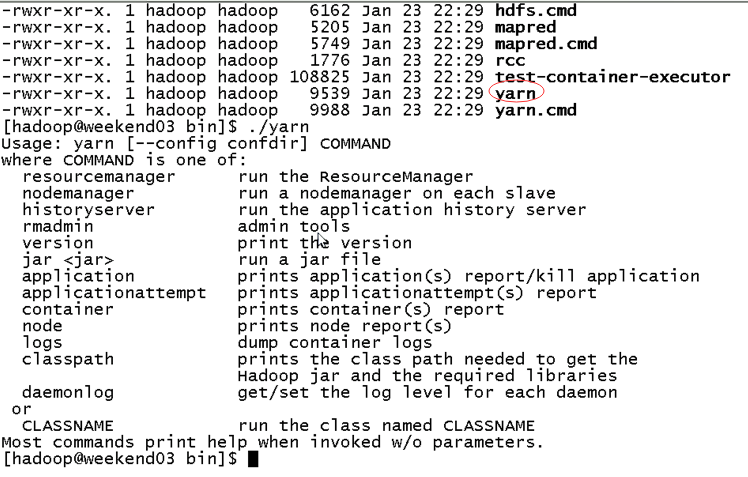
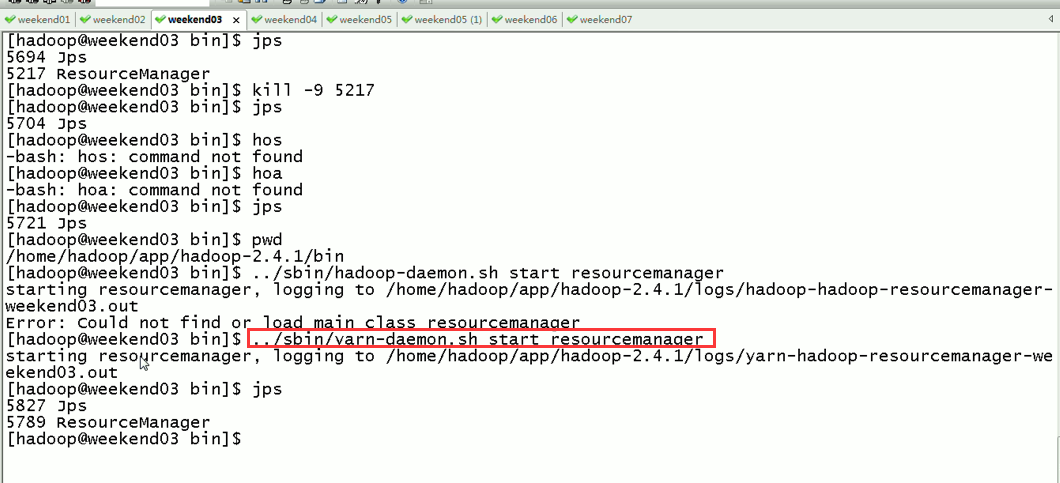
2) weekend03、04的resourcemanger的HA测试
![]()
![]()
![]()
![]()
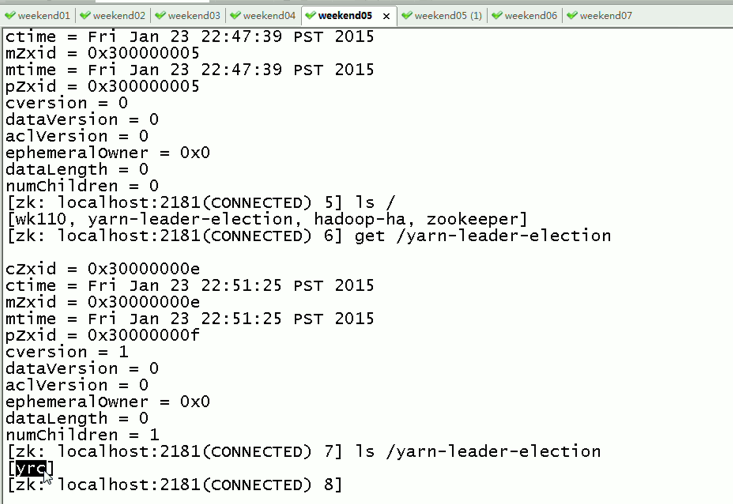
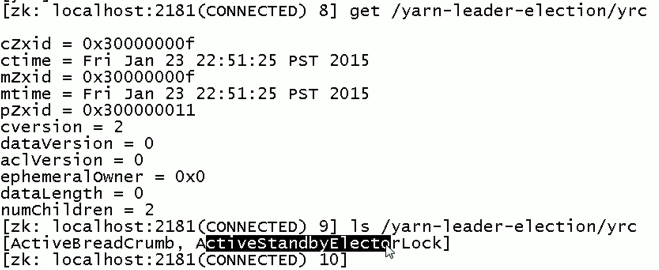
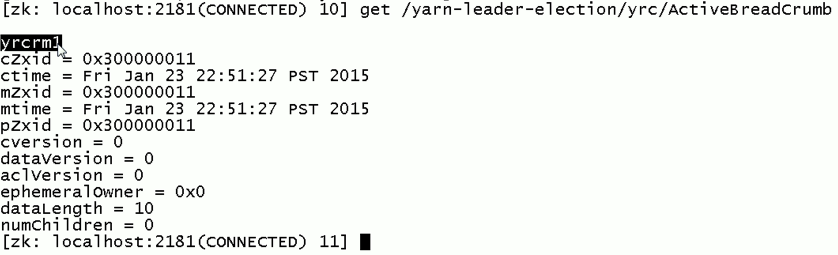
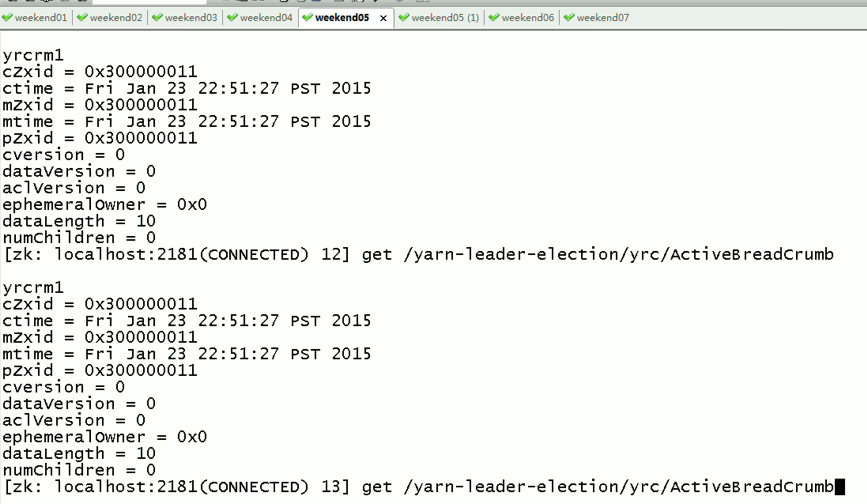
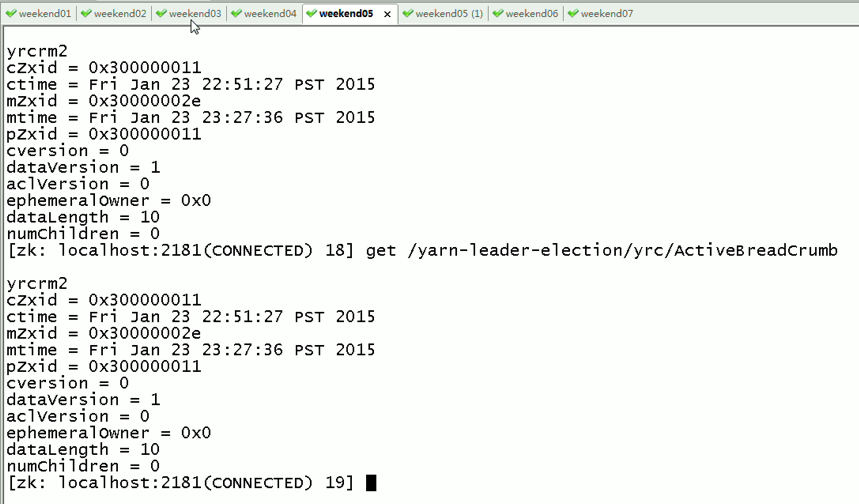
现在,来测试
![]()
会发现,yrcrm1 变成 yrcrm2
![]()
![]()
只是,resourcemanger的HA仅限于此,跟hdfs的HA不一样,
如weekend01(active)在上传文件,突然中断,weekend02(standby)
![]()
![]()
对于,weekend03、04的resourcemanager的HA,
现在是,weekend03(standby)提交作业,weekend04(active)
![]()
![]()
![]()
![]()
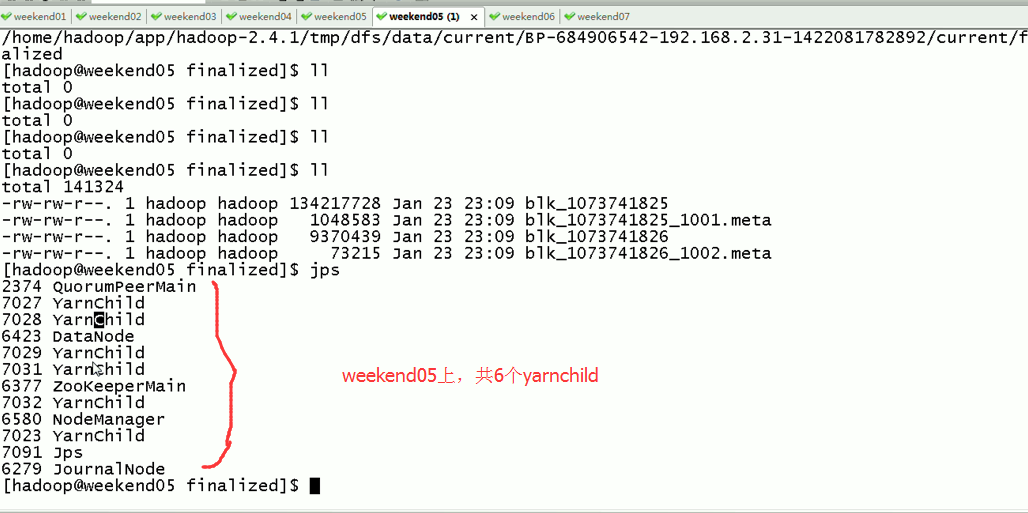
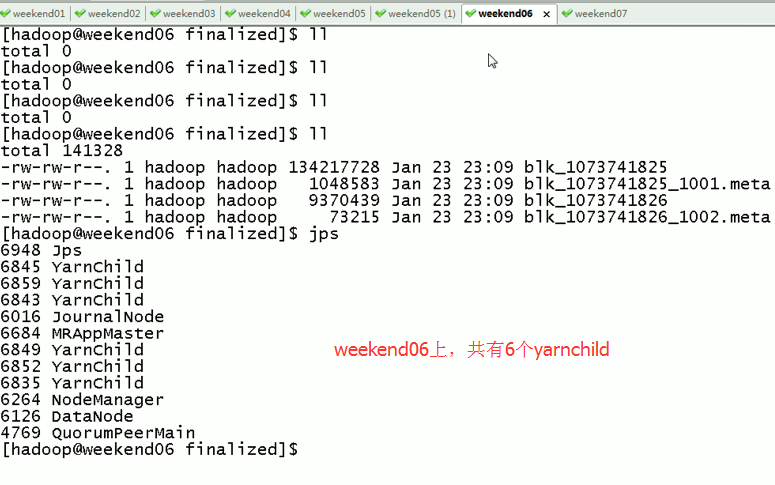
weekend07上,共有8个yarnchild,
![]()
![]()
Weekend05、06、07一起,是20个yarnchild,跑作业的节点。
![]()
![]()
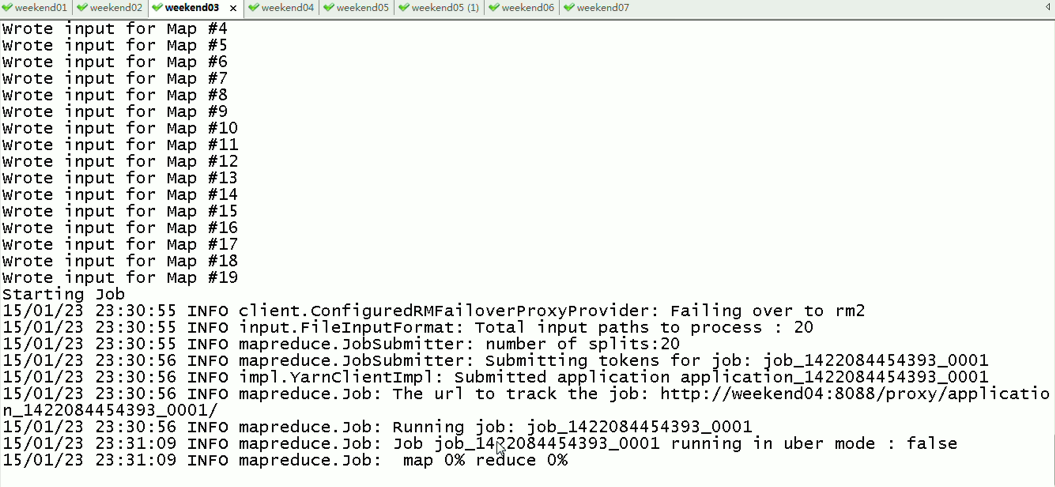
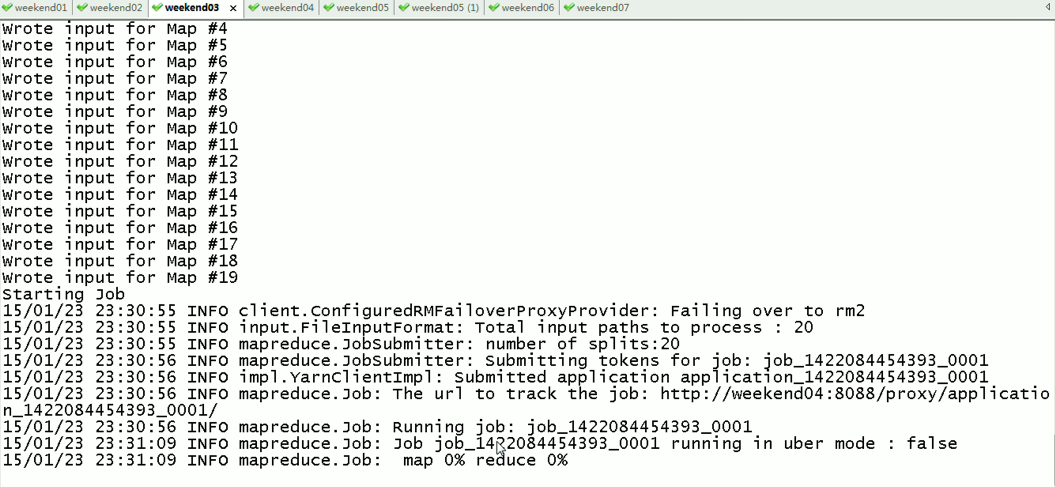
对于,weekend03、04的yarn的HA,
现在是,weekend03(standby)提交作业,weekend04(active)
现在依然还是,weekend03(standby)提交作业,weekend04(active)
以上是Weekend03、4的yarn的HA测试
总结:
以上是weekend01、02的hdfs的HA测试
Weekend03、4的yarn的HA测试
Weekend05、06、07是用来跑作业的,
![]()
关于hdfs的动态增加节点和副本数量管理,在视频里….
暂时,不赘述。
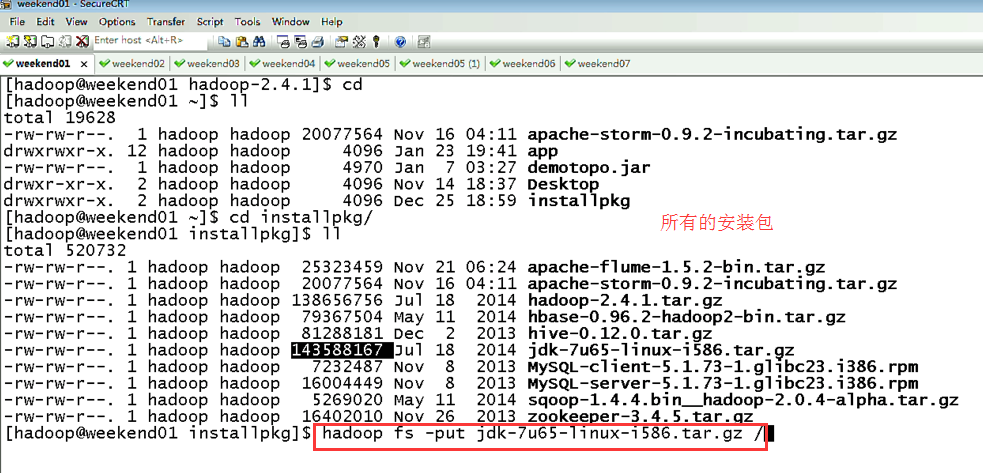
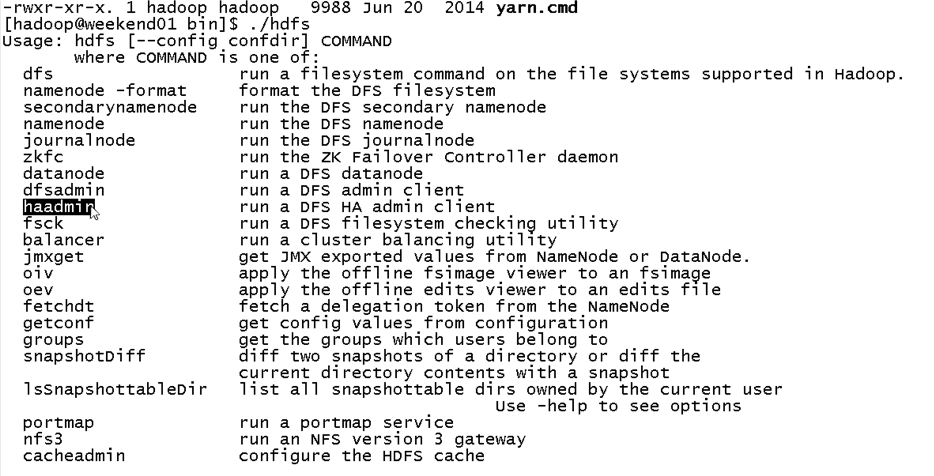
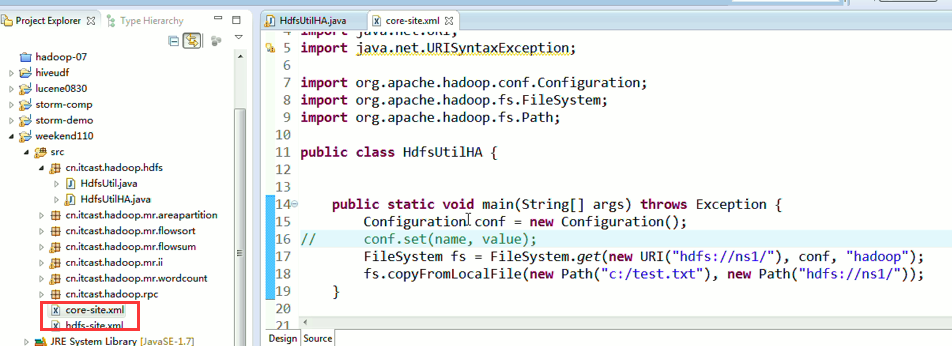
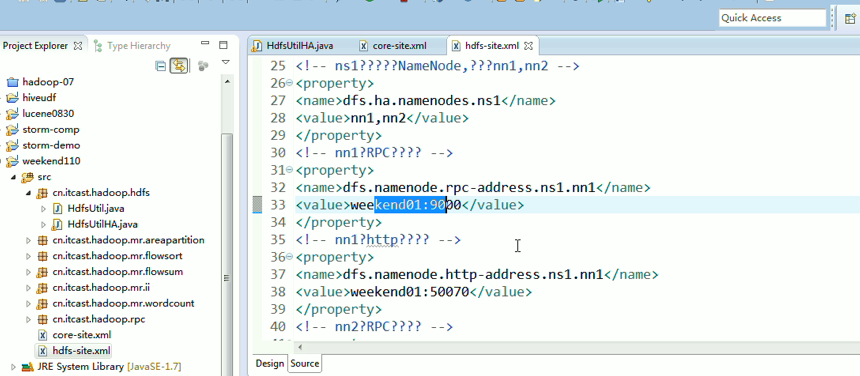
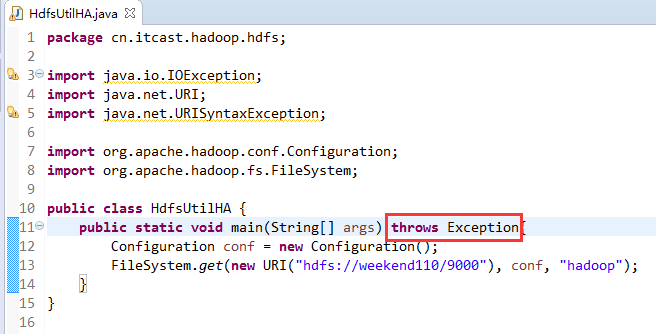
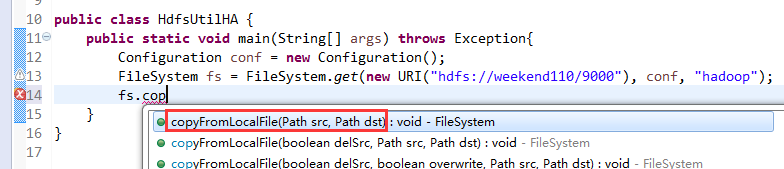
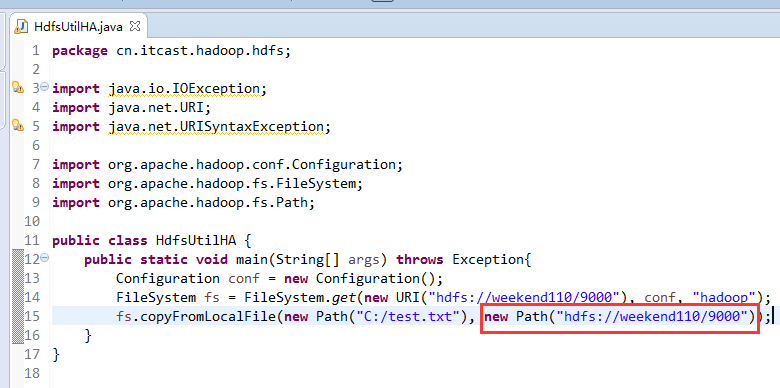
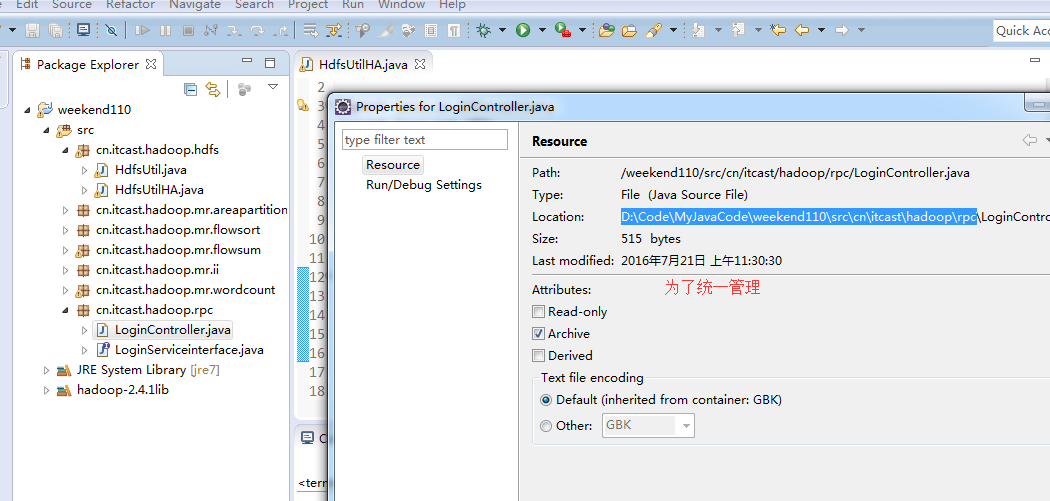
说明,下面是HA的java API访问,
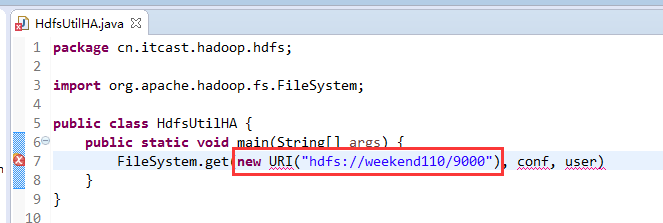
所以,ns1和ns2,这里,是用ns1来访问。
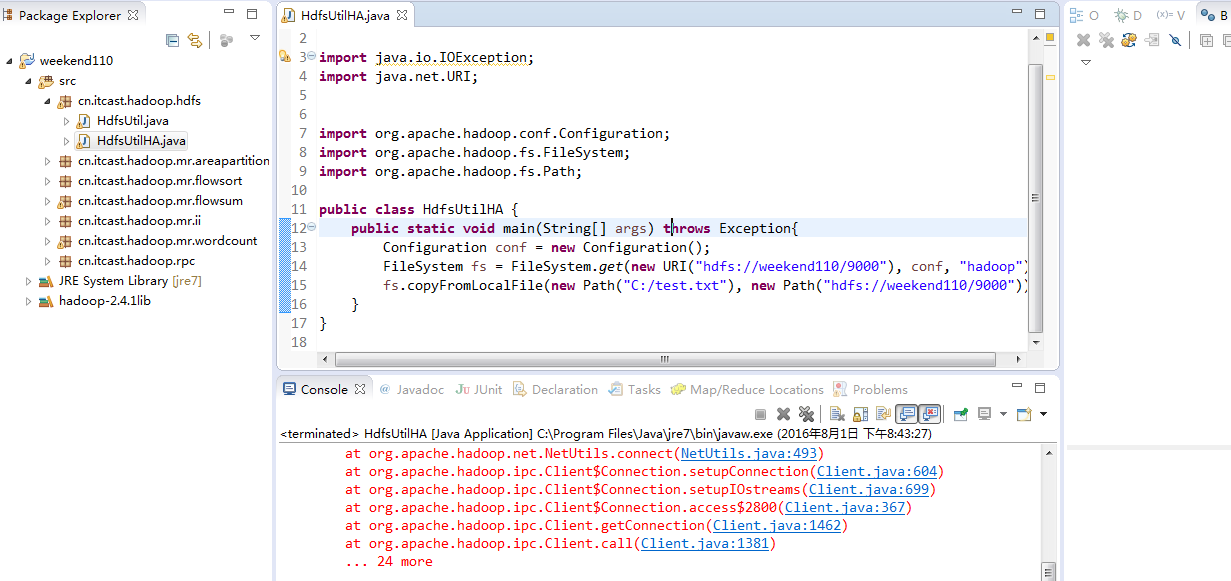
而我,自己当时想在weekend110里玩玩,出现了有错误。还没解决。
当然,这知识点,是要在ns1里的。
如果是视频里的话,则
![]()
![]()
![]()
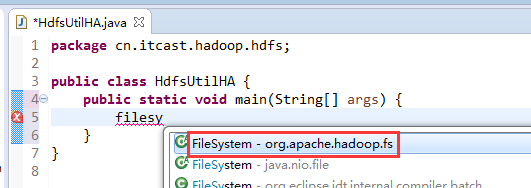
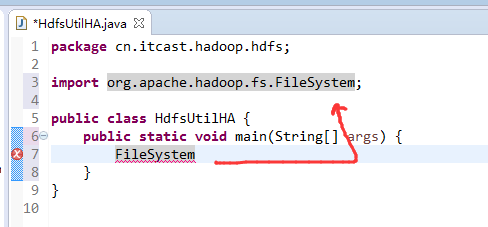
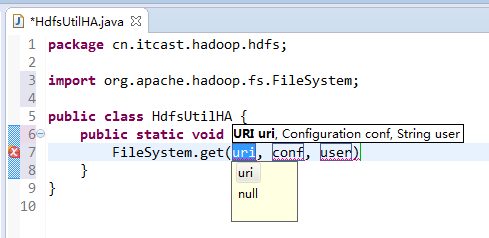
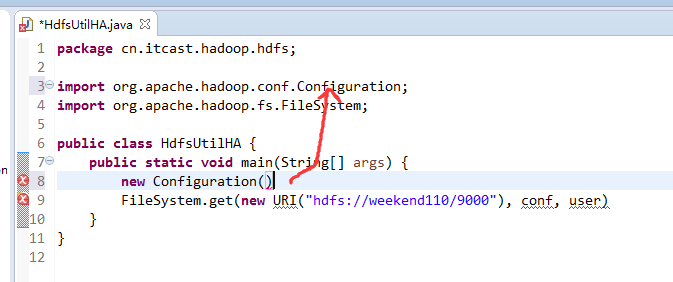
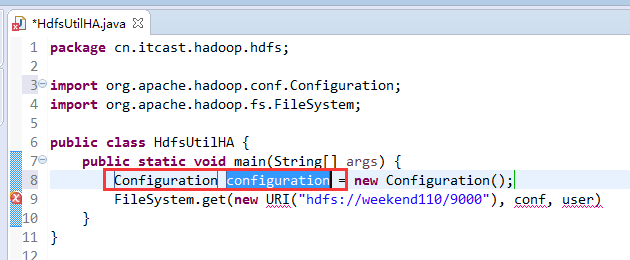
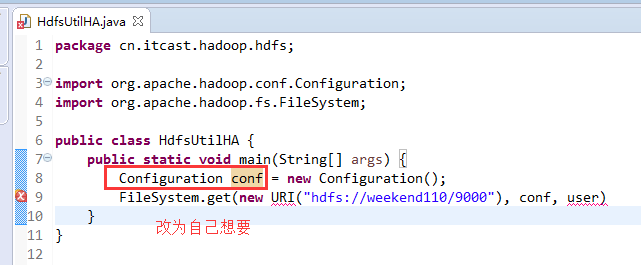
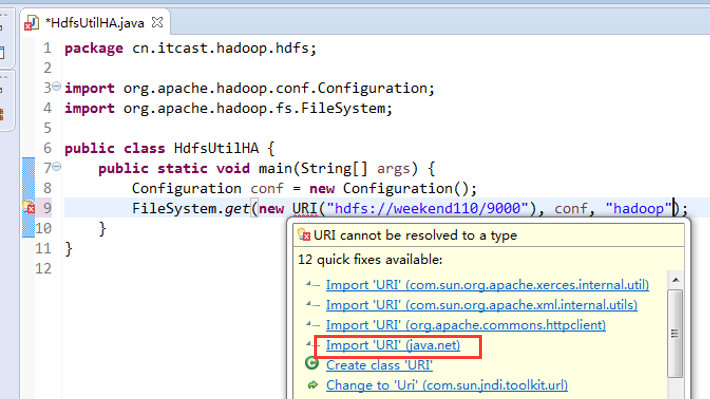
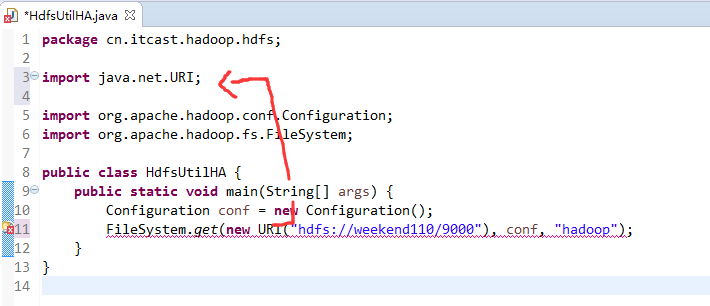
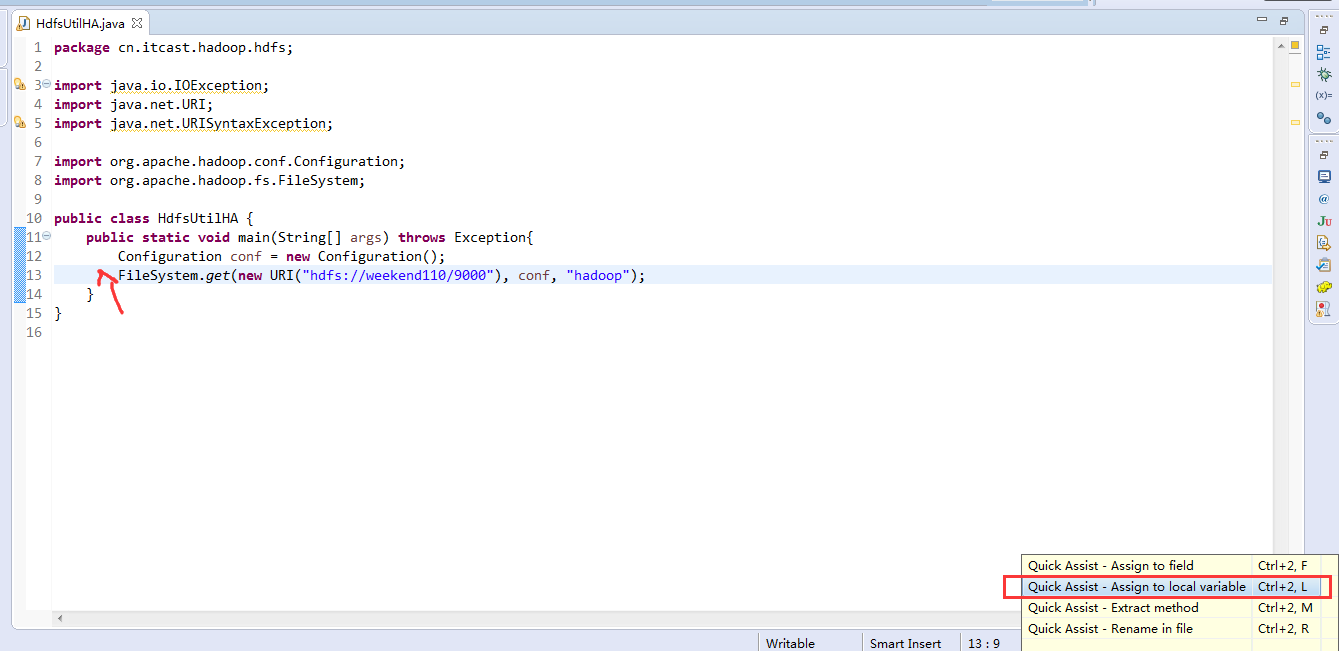
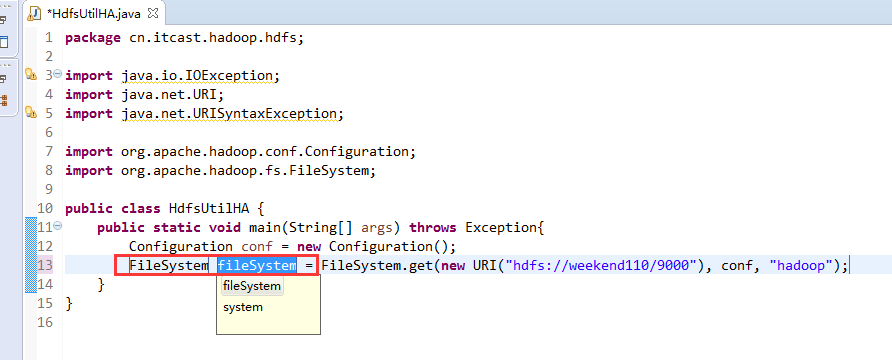
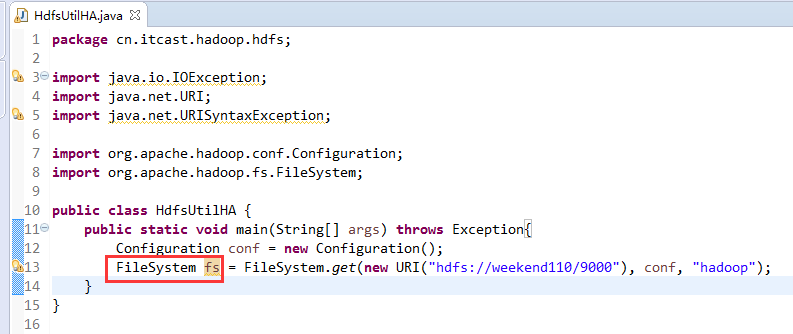
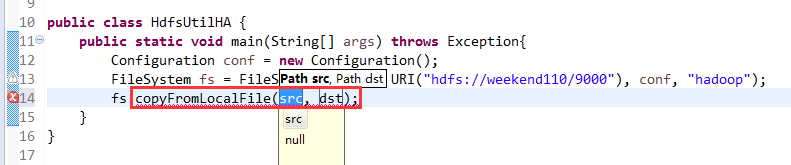
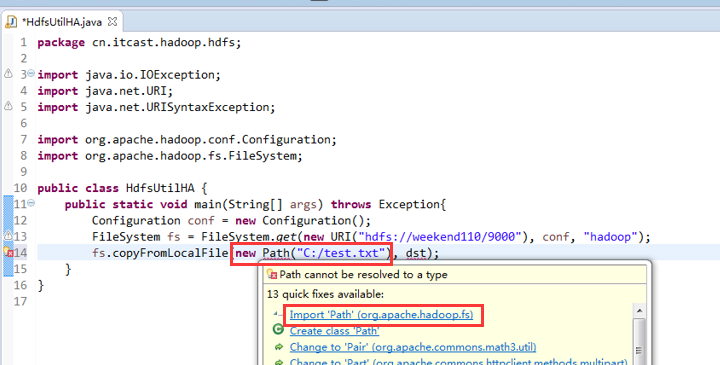
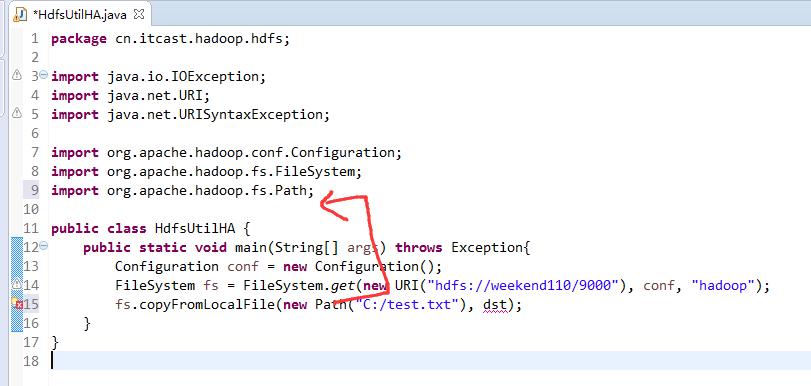
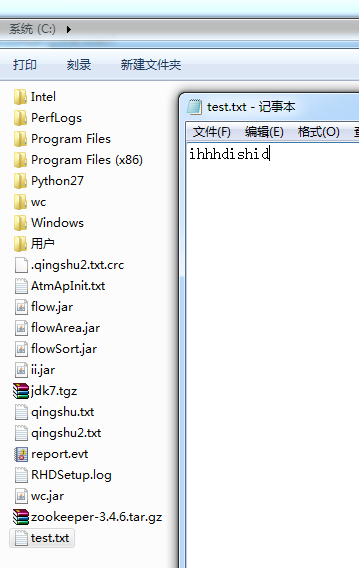
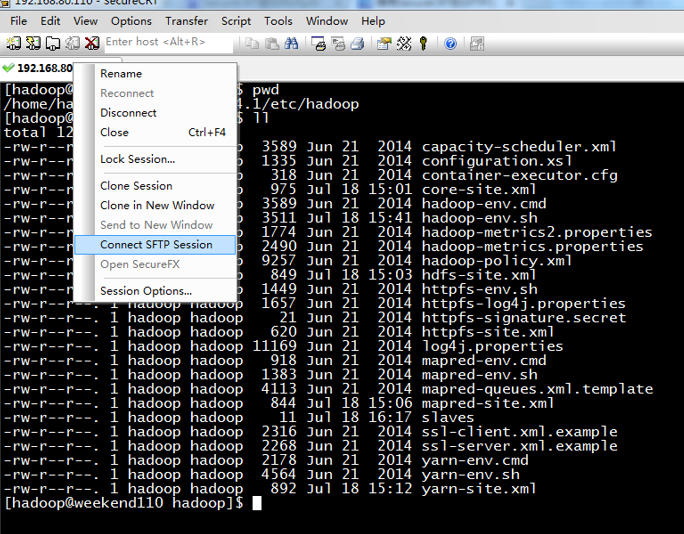
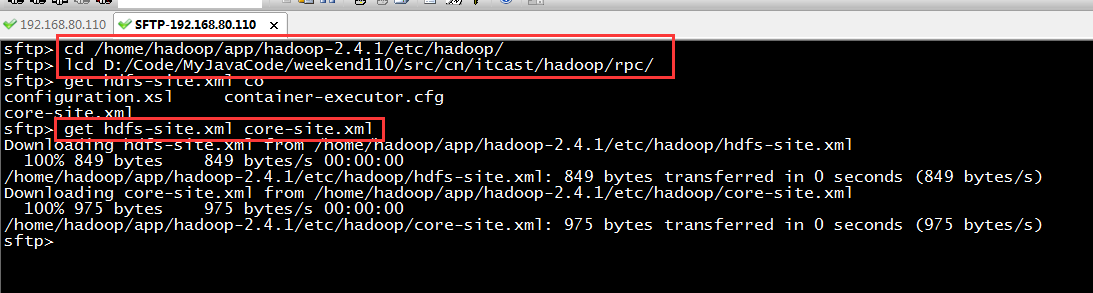
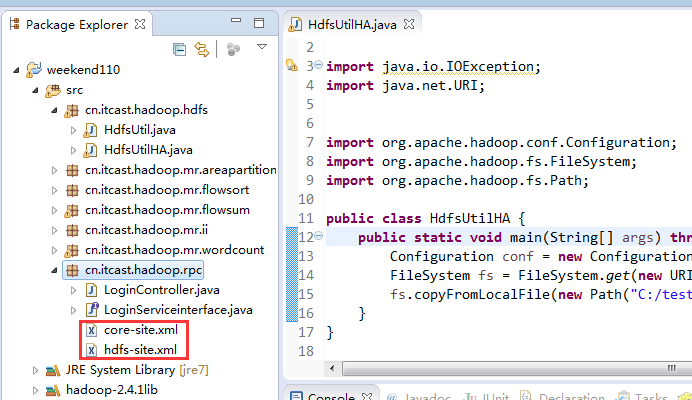
如果是自己玩玩的话,则
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Exception in thread "main" java.net.ConnectException: Call From WIN-BQOBV63OBNM/192.168.56.1 to weekend110:8020 failed on connection exception: java.net.ConnectException: Connection refused: no further information; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(Unknown Source)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(Unknown Source)
at java.lang.reflect.Constructor.newInstance(Unknown Source)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:783)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:730)
at org.apache.hadoop.ipc.Client.call(Client.java:1414)
at org.apache.hadoop.ipc.Client.call(Client.java:1363)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:206)
at com.sun.proxy.$Proxy14.getFileInfo(Unknown Source)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(Unknown Source)
at java.lang.reflect.Method.invoke(Unknown Source)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:190)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:103)
at com.sun.proxy.$Proxy14.getFileInfo(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getFileInfo(ClientNamenodeProtocolTranslatorPB.java:699)
at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:1762)
at org.apache.hadoop.hdfs.DistributedFileSystem$17.doCall(DistributedFileSystem.java:1124)
at org.apache.hadoop.hdfs.DistributedFileSystem$17.doCall(DistributedFileSystem.java:1120)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1120)
at org.apache.hadoop.fs.FileSystem.exists(FileSystem.java:1398)
at org.apache.hadoop.fs.FileUtil.checkDest(FileUtil.java:496)
at org.apache.hadoop.fs.FileUtil.copy(FileUtil.java:348)
at org.apache.hadoop.fs.FileUtil.copy(FileUtil.java:338)
at org.apache.hadoop.fs.FileSystem.copyFromLocalFile(FileSystem.java:1903)
at org.apache.hadoop.fs.FileSystem.copyFromLocalFile(FileSystem.java:1871)
at org.apache.hadoop.fs.FileSystem.copyFromLocalFile(FileSystem.java:1836)
at cn.itcast.hadoop.hdfs.HdfsUtilHA.main(HdfsUtilHA.java:15)
Caused by: java.net.ConnectException: Connection refused: no further information
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(Unknown Source)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:529)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:493)
at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:604)
at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:699)
at org.apache.hadoop.ipc.Client$Connection.access$2800(Client.java:367)
at org.apache.hadoop.ipc.Client.getConnection(Client.java:1462)
at org.apache.hadoop.ipc.Client.call(Client.java:1381)
... 24 more
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/5902871.html,如需转载请自行联系原作者