Rook是基于的Ceph的分布式存储系统,可以使用kubectl命令部署,也可以使用 Helm进行管理和部署。
Rook是专用于Cloud-Native环境的文件、块、对象存储服务。它实现了一个自我管理的、自我扩容的、自我修复的分布式存储服务。内容包括:
- 安装Rook Operator。
- 安装Rook Cluster。
- 创建PV。
- 请求PVC。
- 创建StorageClass。
- 使用PVC和StorageClass。
Rook支持自动部署、启动、配置、分配(provisioning)、扩容/缩容、升级、迁移、灾难恢复、监控,以及资源管理。 为了实现所有这些功能,Rook依赖底层的容器编排平台。
目前Rook仍然处于Alpha版本,初期专注于Kubernetes+Ceph。Ceph是一个分布式存储系统,支持文件、块、对象存储,在生产环境中被广泛应用。
Rook架构
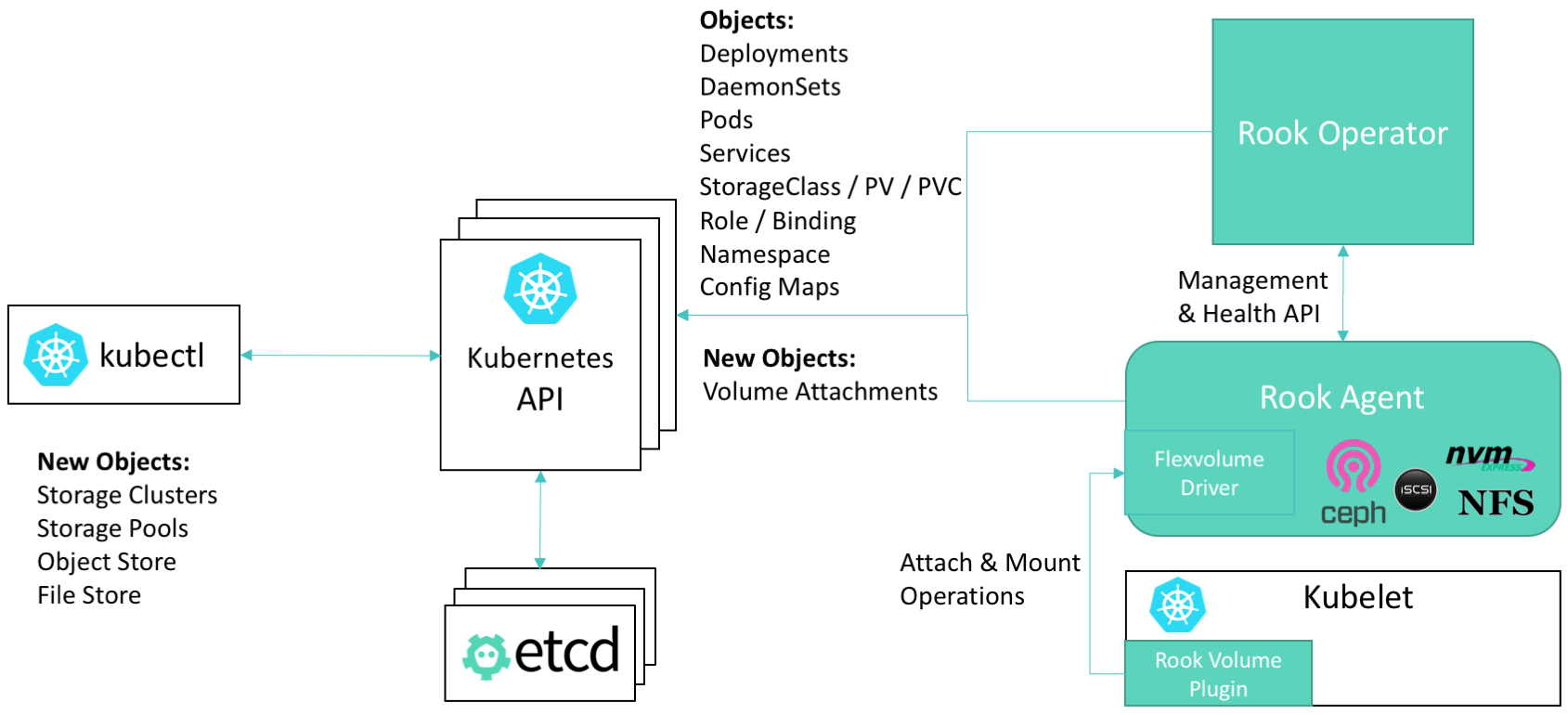
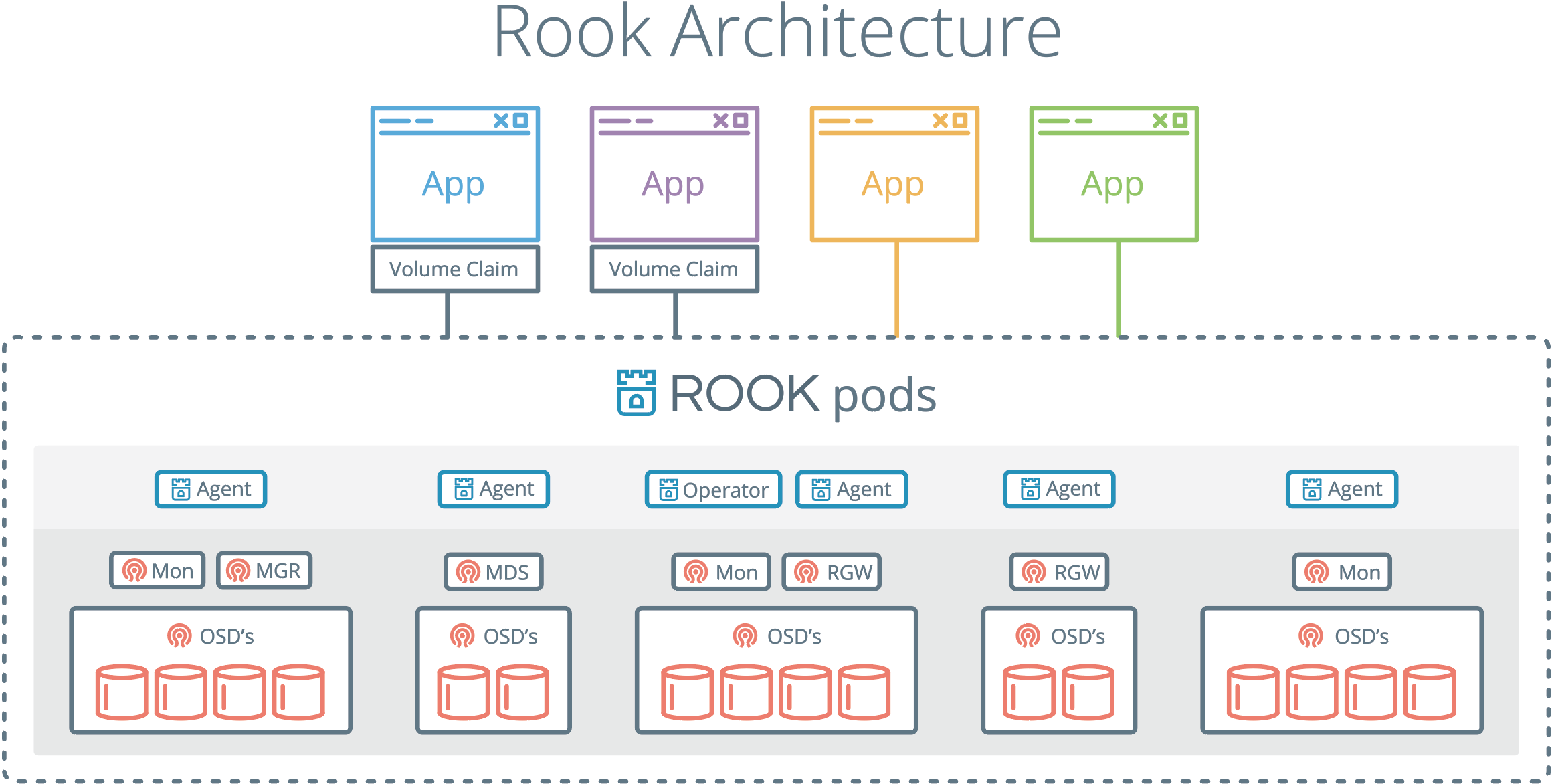
Rook和K8S的交互关系如下图:
![rook-architecture-0]()
![rook-architecture-2]()
说明如下:
- Kubelet是K8S节点上运行的代理程序,负责挂载当前节点的Pod所需要的卷
- Rook提供了一种卷插件,扩展了K8S的存储系统。Pod可以挂载Rook管理的块设备或者文件系统
- Operator启动并监控:监控Ceph的Pods、OSD(提供基本的RADOS存储)的Daemonset。Operator还管理CRD、对象存储(S3/Swift)、文件系统。Operator通过监控存储守护程序,来保障集群的健康运行。Ceph监控Pod会自动启动和Failover。集群扩缩容时Operator会进行相应的调整
- Operator还负责创建Rook Agent。这些代理是部署在所有K8S节点上的Pod。每个代理都配置一个Flexvolume驱动,此驱动和K8S的卷控制框架集成。节点上的所有存储相关操作(例如添加网络存储设备、挂载卷、格式化文件系统)都Agent负责
Rook守护程序(Mons, OSDs, MGR, RGW, MDS)被编译到单体的程序rook中,并打包到一个很小的容器中。该容器还包含Ceph守护程序,以及管理、存储数据所需的工具。
Rook隐藏了Ceph的很多细节,而向它的用户暴露物理资源、池、卷、文件系统、Bucket等概念。
1、部署基础服务
K8S版本要求1.6+,Rook需要管理K8S存储的权限,此外你需要允许K8S加载Rook存储插件。
注意:K8S 1.10已经通过CSI接口支持容器存储,不需要下面的插件加载操作。
加载存储插件
Rook基于FlexVolume来集成K8S卷控制框架,基于FlexVolume实现的存储驱动,必须存放到所有K8S节点的存储插件专用目录中。
此目录的默认值是/usr/libexec/kubernetes/kubelet-plugins/volume/exec/。但是某些OS下部署K8S时此目录是只读的,例如CoreOS。你可以指定Kubelet的启动参数,修改为其它目录:
--volume-plugin-dir=/var/lib/kubelet/volumeplugins
使用下文的YAML来创建Rook相关资源后,存储插件Rook会自动加载到所有K8S节点的存储插件目录中:
ls /usr/libexec/kubernetes/kubelet-plugins/volume/exec/rook.io~rook/
# 输出(一个可执行文件) # rook
在K8S 1.9.x中,需要同时修改rook-operator配置文件中的环境变量:
- name: FLEXVOLUME_DIR_PATH
value: "/var/lib/kubelet/volumeplugins"
下载Rook源代码
Rook官方提供了资源配置文件样例,到这里下载:
git clone https://github.com/rook/rook.git
部署Rook Operator
执行下面的命令部署:
kubectl apply -f /home/alex/Go/src/rook/cluster/examples/kubernetes/rook-operator.yaml
or
等待rook-operator和所有rook-agent变为Running状态:
kubectl -n rook-system get pod
# NAME READY STATUS RESTARTS AGE # rook-agent-5ttnt 1/1 Running 0 39m # rook-agent-bmnwn 1/1 Running 0 39m # rook-agent-n8nwd 1/1 Running 0 39m # rook-agent-s6b7r 1/1 Running 0 39m # rook-agent-x5p5n 1/1 Running 0 39m # rook-agent-x6mnj 1/1 Running 0 39m # rook-operator-6f8bbf9b8-4fd29 1/1 Running 0 22m
2、创建Rook Cluster
到这里,Rook Operator以及所有节点的Agent应该已经正常运行了。现在可以创建一个Rook Cluster。你必须正确配置dataDirHostPath,才能保证重启后集群配置信息不丢失。
执行下面的命令部署:
kubectl apply -f /home/alex/Go/src/rook/cluster/examples/kubernetes/rook-cluster.yaml
等待rook名字空间的所有Pod变为Running状态:
kubectl -n rook get pod
# NAME READY STATUS RESTARTS AGE # rook-api-848df956bf-blskc 1/1 Running 0 39m # rook-ceph-mgr0-cfccfd6b8-x597n 1/1 Running 0 39m # rook-ceph-mon0-fj4mx 1/1 Running 0 39m # rook-ceph-mon1-7gjjq 1/1 Running 0 39m # rook-ceph-mon2-tc4t4 1/1 Running 0 39m # rook-ceph-osd-6rkbt 1/1 Running 0 39m # rook-ceph-osd-f6x62 1/1 Running 1 39m # rook-ceph-osd-k4rmm 1/1 Running 0 39m # rook-ceph-osd-mtfv5 1/1 Running 1 39m # rook-ceph-osd-sllbh 1/1 Running 2 39m # rook-ceph-osd-wttj4 1/1 Running 2 39m
3、块存储
块存储(Block Storage)可以挂载到单个Pod的文件系统中。
在提供(Provisioning)块存储之前,需要先创建StorageClass和存储池。K8S需要这两类资源,才能和Rook交互,进而分配持久卷(PV)。
执行下面的命令创建StorageClass和存储池:
kubectl apply -f /home/alex/Go/src/rook/cluster/examples/kubernetes/rook-storageclass.yaml
确认K8S资源的状态:
kubectl get storageclass
# NAME PROVISIONER AGE # rook-block rook.io/block 5m
kubectl get pool --all-namespaces
# NAMESPACE NAME AGE # rook replicapool 5m
首先声明一个PVC,创建部署文件 pvc-test.yml:
apiVersion: v1 kind: PersistentVolumeClaim metadata:
name: test-pvc
namespace: dev
spec:
storageClassName: rook-block
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 128Mi
保存,然后进行部署:
kubectl create -f pvc-test.yml
确定PV被成功提供:
kubectl -n dev get pvc
# 已经绑定到PV # NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE # pvc/test-pvc Bound pvc-e0 128Mi RWO rook-block 10s
kubectl -n dev get pv
# 已经绑定到PVC # NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE # pv/pvc-e0 128Mi RWO Delete Bound dev/test-pvc rook-block 10s
然后,创建一个Pod配置文件pv-consumer.yml,使用PV:
apiVersion: v1
kind: Pod
metadata:
name: test
namespace: dev
spec:
restartPolicy: OnFailure
containers:
- name: test-container
image: busybox
volumeMounts:
- name: test-pv
mountPath: /var/test command: ['sh', '-c', 'echo Hello > /var/test/data; exit 0']
volumes:
- name: test-pv
persistentVolumeClaim:
claimName: test-pvc
部署该pv-consumer.yml:
kubectl apply -f pv-consumer.yml
此Pod应该很快就执行完毕:
kubectl -n dev get pod test
# NAME READY STATUS RESTARTS AGE # test 0/1 Completed 0 17s
删除此Pod: kubectl -n dev delete pod test。
可以发现持久卷仍然存在。把PV挂载到另外一个Pod(pv-consumer2.yml):
apiVersion: v1
kind: Pod
metadata:
name: test
namespace: dev
spec:
restartPolicy: OnFailure
containers:
- name: test-container
image: busybox
volumeMounts:
- name: test-pv
mountPath: /var/test command: ['sh', '-c', 'cat /var/test/data; exit 0']
volumes:
- name: test-pv
persistentVolumeClaim:
claimName: test-pvc
部署该Pod,如下:
kubectl apply -f pv-consumer2.yml
查看第二个Pod的日志输出:
kubectl -n dev logs test test-container
# Hello
可以看到,针对PV的读写操作正常。
4、清理系统
执行下面的命令,解除对块存储的支持:
kubectl delete -n rook pool replicapool
kubectl delete storageclass rook-block
如果不再使用Rook,或者希望重新搭建Rook集群,你需要:
- 清理名字空间rook-system,其中包含Rook Operator和Rook Agent
- 清理名字空间rook,其中包含Rook存储集群(集群CRD)
- 各节点的/var/lib/rook目录,Ceph mons和Osds的配置信息缓存于此
命令示例:
kubectl delete -n rook pool replicapool
kubectl delete storageclass rook-block
kubectl delete -n kube-system secret rook-admin
kubectl delete -f kube-registry.yaml
# 删除Cluster CRD
kubectl delete -n rook cluster rook
# 当Cluster CRD被删除后,删除Rook Operator和Agent
kubectl delete thirdpartyresources cluster.rook.io pool.rook.io objectstore.rook.io filesystem.rook.io volumeattachment.rook.io # ignore errors if on K8s 1.7+
kubectl delete crd clusters.rook.io pools.rook.io objectstores.rook.io filesystems.rook.io volumeattachments.rook.io # ignore errors if on K8s 1.5 and 1.6
kubectl delete -n rook-system daemonset rook-agent
kubectl delete -f rook-operator.yaml
kubectl delete clusterroles rook-agent
kubectl delete clusterrolebindings rook-agent
# 删除名字空间
kubectl delete namespace rook
# 清理所有节点的dataDirHostPath目录(默认/var/lib/rook)
5、配置文件
Namespace
通常会把Rook相关的K8S资源存放在以下名字空间:
apiVersion: v1 kind: Namespace metadata:
name: rook-system
---
apiVersion: v1 kind: Namespace metadata:
name: rook
ServiceAccount
apiVersion: v1 kind: ServiceAccount metadata:
name: rook-operator
namespace: rook-system
imagePullSecrets:
- name: gmemregsecret
ClusterRole
定义一个访问权限的集合。
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: rook-operator
rules:
- apiGroups:
- ""
resources:
- namespaces
- serviceaccounts
- secrets
- pods
- services
- nodes
- nodes/proxy
- configmaps
- events
- persistentvolumes
- persistentvolumeclaims
verbs:
- get
- list
- watch
- patch
- create
- update
- delete
- apiGroups:
- extensions
resources:
- thirdpartyresources
- deployments
- daemonsets
- replicasets
verbs:
- get
- list
- watch
- create
- update
- delete
- apiGroups:
- apiextensions.k8s.io
resources:
- customresourcedefinitions
verbs:
- get
- list
- watch
- create
- delete
- apiGroups:
- rbac.authorization.k8s.io
resources:
- clusterroles
- clusterrolebindings
- roles
- rolebindings
verbs:
- get
- list
- watch
- create
- update
- delete
- apiGroups:
- storage.k8s.io
resources:
- storageclasses
verbs:
- get
- list
- watch
- delete
- apiGroups:
- rook.io
resources:
- "*"
verbs:
- "*"
ClusterRoleBinding
为账号rook-operator授予上述角色。
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: rook-operator namespace: rook-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: rook-operator
subjects:
- kind: ServiceAccount
name: rook-operator namespace: rook-system
Rook Operator
这是一个Deployment,它在容器中部署Rook Operator。后者启动后会自动部署Rook Agent,Operator和Agent使用的是同一镜像。
对于下面这样的配置,使用私有镜像的,不但需要为rook-operator配置imagePullSecrets,还要为运行Rook Agent的服务账户rook-agent配置imagePullSecrets:
kubectl --namespace=rook-system create secret docker-registry gmemregsecret \
--docker-server=docker.gmem.cc --docker-username=alex \
--docker-password=lavender --docker-email=k8s@gmem.cc
kubectl --namespace=rook-system patch serviceaccount default -p '{"imagePullSecrets": [{"name": "gmemregsecret"}]}'
kubectl --namespace=rook-system patch serviceaccount rook-agent -p '{"imagePullSecrets": [{"name": "gmemregsecret"}]}'
配置文件示例:
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: rook-operator namespace: rook-system
spec:
replicas: 1 template:
metadata:
labels:
app: rook-operator
spec:
serviceAccountName: rook-operator
containers:
- name: rook-operator
image: docker.gmem.cc/rook/rook:master
args: ["operator"]
env:
- name: ROOK_MON_HEALTHCHECK_INTERVAL
value: "45s"
- name: ROOK_MON_OUT_TIMEOUT
value: "300s"
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
CRD
定制资源定义(Custom Resources Definition,CRD)即Rook相关的资源的配置规格,每种类型的资源具有自己的CRD 。
Cluster
这种资源对应了基于Rook的存储集群。
apiVersion: rook.io/v1alpha1 kind: Cluster metadata:
name: rook
namespace: rook
spec: # 存储后端,当前仅支持Ceph
backend: ceph
# 配置文件在宿主机的存放目录
dataDirHostPath: /var/lib/rook
# 如果设置为true则使用宿主机的网络,而非容器的SDN(软件定义网络)
hostNetwork: false
# 启动mon的数量,必须奇数,1-9之间
monCount: 3
# 控制Rook的各种服务如何被K8S调度
placement:
# 总体规则,具体服务(api, mgr, mon, osd)的规则覆盖总体规则
all:
# Rook的Pod能够被调用到什么节点上
nodeAffinity:
# 硬限制 配置变更后已经运行的Pod不被影响
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
# 节点必须具有role=storage-node
- matchExpressions:
- key: role
operator: In
values:
- storage-node
# Rook能够调用到运行了怎样的其它Pod的拓扑域上
podAffinity:
podAntiAffinity:
# 可以容忍具有哪些taint的节点
tolerations:
- key: storage-node
operator: Exists
api:
nodeAffinity:
podAffinity:
podAntiAffinity:
tolerations:
mgr:
nodeAffinity:
podAffinity:
podAntiAffinity:
tolerations:
mon:
nodeAffinity:
tolerations:
osd:
nodeAffinity:
podAffinity:
podAntiAffinity:
tolerations:
# 配置各种服务的资源需求
resources:
api:
limits:
cpu: "500m"
memory: "1024Mi"
requests:
cpu: "500m"
memory: "1024Mi"
mgr:
mon:
osd:
# 集群级别的存储配置,每个节点都可以覆盖
storage:
# 是否所有节点都用于存储。如果指定nodes配置,则必须设置为false
useAllNodes: true
# 是否在节点上发现的所有设备,都自动的被OSD消费
useAllDevices: false
# 正则式,指定哪些设备可以被OSD消费,示例: # sdb 仅仅使用设备/dev/sdb # ^sd. 使用所有/dev/sd*设备 # ^sd[a-d] 使用sda sdb sdc sdd # 可以指定裸设备,Rook会自动分区但不挂载
deviceFilter: ^vd[b-c]
# 每个节点上用于存储OSD元数据的设备。使用低读取延迟的设备,例如SSD/NVMe存储元数据可以提升性能
metadataDevice:
# 集群的位置信息,例如Region或数据中心,被直接传递给Ceph CRUSH map
location:
# OSD的存储格式的配置信息
storeConfig:
# 可选filestore或bluestore,默认后者,它是Ceph的一个新的存储引擎 # bluestore直接管理裸设备,抛弃了ext4/xfs等本地文件系统。在用户态下使用Linux AIO直接对裸设备IO
storeType: bluestore
# bluestore数据库容量 正常尺寸的磁盘可以去掉此参数,例如100GB+
databaseSizeMB: 1024
# filestore日志容量 正常尺寸的磁盘可以去掉此参数,例如20GB+
journalSizeMB: 1024
# 用于存储的节点目录。在一个物理设备上使用两个目录,会对性能有负面影响
directories:
- path: /rook/storage-dir
# 可以针对每个节点进行配置
nodes:
# 节点A的配置
- name: "172.17.4.101"
directories:
- path: "/rook/storage-dir"
resources:
limits:
cpu: "500m"
memory: "1024Mi"
requests:
cpu: "500m"
memory: "1024Mi" # 节点B的配置
- name: "172.17.4.201"
- name: "sdb"
- name: "sdc"
storeConfig:
storeType: bluestore
- name: "172.17.4.301"
deviceFilter: "^sd."
Pool
apiVersion: rook.io/v1alpha1 kind: Pool metadata:
name: ecpool
namespace: rook
spec: # 存储池中的每份数据是否是复制的
replicated:
# 副本的份数
size: 3
# Ceph的Erasure-coded存储池消耗更少的存储空间,必须禁用replicated
erasureCoded:
# 每个对象的数据块数量
dataChunks: 2
# 每个对象的代码块数量
codingChunks: 1
crushRoot: default
ObjectStore
apiVersion: rook.io/v1alpha1 kind: ObjectStore metadata:
name: my-store
namespace: rook
spec: # 元数据池,仅支持replication
metadataPool:
replicated:
size: 3
# 数据池,支持replication或erasure codin
dataPool:
erasureCoded:
dataChunks: 2
codingChunks: 1
# RGW守护程序设置
gateway:
# 支持S3
type: s3
# 指向K8S的secret,包含数字证书信息
sslCertificateRef:
# RGW Pod和服务监听的端口
port: 80
securePort:
# 为此对象存储提供负载均衡的RGW Pod数量
instances: 1
# 是否在所有节点上启动RGW。如果为false则必须设置instances
allNodes: false
placement:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: role
operator: In
values:
- rgw-node
tolerations:
- key: rgw-node
operator: Exists
podAffinity:
podAntiAffinity:
resources:
limits:
cpu: "500m"
memory: "1024Mi"
requests:
cpu: "500m"
memory: "1024Mi"
Filesystem
apiVersion: rook.io/v1alpha1 kind: Filesystem metadata:
name: myfs
namespace: rook
spec: # 元数据池
metadataPool:
replicated:
size: 3
# 数据池
dataPools:
- erasureCoded:
dataChunks: 2
codingChunks: 1
# MDS守护程序的设置
metadataServer:
# MDS活动实例数量
activeCount: 1
# 如果设置为true,则额外的MDS实例处于主动Standby状态,维持文件系统元数据的热缓存 # 如果设置为false,则额外MDS实例处于被动Standby状态
activeStandby: true
placement:
resources:
Rook工具箱
Rook提供了一个工具箱容器,该容器中的命令可以用来调试、测试Rook(rook-tools.yaml):
apiVersion: v1 kind: Pod metadata:
name: rook-tools
namespace: rook
spec:
dnsPolicy: ClusterFirstWithHostNet
containers:
- name: rook-tools
image: rook/toolbox:master
imagePullPolicy: IfNotPresent
env:
- name: ROOK_ADMIN_SECRET
valueFrom:
secretKeyRef:
name: rook-ceph-mon
key: admin-secret
securityContext:
privileged: true
volumeMounts:
- mountPath: /dev
name: dev
- mountPath: /sys/bus
name: sysbus
- mountPath: /lib/modules
name: libmodules
- name: mon-endpoint-volume
mountPath: /etc/rook
hostNetwork: false
volumes:
- name: dev
# 将宿主机目录作为Pod的卷
hostPath:
path: /dev
- name: sysbus
hostPath:
path: /sys/bus
- name: libmodules
hostPath:
path: /lib/modules
- name: mon-endpoint-volume
configMap:
# 此ConfigMap已经存在
name: rook-ceph-mon-endpoints
items:
- key: data
path: mon-endpoints
创建好上面的Pod后,执行以下命令连接到它:
kubectl -n rook exec -it rook-tools bash
rookctl开箱即用的命令包括rookctl、ceph、rados,你也可以安装任何其它工具。
注意:此命令已经被弃用,如果需要配置集群,请使用CRD。
Rook的客户端工具rookctl可以用来管理集群的块、对象、文件存储。
| 子命令 |
说明 |
| block |
管理集群中的块设备和镜像: # rookctl block list # RBD即 RADOS Block Devices # RADOS 即 Reliable, Autonomic Distributed Object Store 可靠原子分布式对象存储 # RADOS是Ceph的核心之一,能够在动态变化和异质结构的存储设备集群之上提供一种稳定、可扩展、高性能的 # 单一逻辑对象存储接口和能够实现节点的自适应和自管理的存储系统
NAME POOL SIZE DEVICE MOUNT
pvc-006bea14-23bd-11e8-9763-deadbeef00a0 replicapool 256.00 MiB rbd
pvc-145bc143-23bf-11e8-9763-deadbeef00a0 replicapool 256.00 MiB rbd
pvc-274e4a9c-23c1-11e8-9763-deadbeef00a0 replicapool 256.00 MiB rbd
pvc-2aaaf126-23bf-11e8-9763-deadbeef00a0 replicapool 256.00 MiB rbd
pvc-3b70adcb-23bf-11e8-9763-deadbeef00a0 replicapool 256.00 MiB rbd
pvc-9e6bb98a-23be-11e8-9763-deadbeef00a0 replicapool 256.00 MiB rbd
pvc-c0d5e89b-23be-11e8-9763-deadbeef00a0 replicapool 256.00 MiB rbd
pvc-d6f4938d-23be-11e8-9763-deadbeef00a0 replicapool 256.00 MiB rbd
pvc-e643cf67-23be-11e8-9763-deadbeef00a0 replicapool 256.00 MiB rbd
pvc-f9a64409-23be-11e8-9763-deadbeef00a0 replicapool 256.00 MiB rbd
|
| filesystem |
管理集群中的共享文件系统 |
| object |
管理集群中的对象存储 |
| node |
管理集群中的节点 |
| pool |
管理集群中的存储池 |
| status |
输出集群状态:# rookctl status # 整体状态报告 OVERALL STATUS: WARNING
SUMMARY:
SEVERITY NAME MESSAGE
WARNING TOO_FEW_PGS too few PGs per OSD (8 < min 30)
WARNING MON_CLOCK_SKEW clock skew detected on mon.rook-ceph-mon1, mon.rook-ceph-mon3
# 总存储空间,及其用量
USAGE:
TOTAL USED DATA AVAILABLE
377.24 GiB 252.17 GiB 105.11 MiB 125.07 GiB
MONITORS:
NAME ADDRESS IN QUORUM STATUS
rook-ceph-mon18 10.96.33.35:6790/0 true OK
rook-ceph-mon1 10.97.38.247:6790/0 true WARNING
rook-ceph-mon3 10.105.193.133:6790/0 true WARNING
MGRs:
NAME STATUS
rook-ceph-mgr0 Active
# OSD,即Object Storage Daemon,是Ceph的对象存储守护进程
OSDs:
TOTAL UP IN FULL NEAR FULL
12 12 12 false false
PLACEMENT GROUPS (100 total):
STATE COUNT
active+clean 100
|
常见问题
- rook-ceph-osd无法启动
- 报错信息:failed to configure devices. failed to config osd 65. failed format/partition of osd 65. failed to partion device vdc. failed to partition /dev/vdc. Failed to complete partition vdc: exit status 4
- 报错原因:在我的环境下是节点(本身是KVM虚拟机)的虚拟磁盘太小导致,分配32G的磁盘没有问题,20G则出现上述报错
本文转自开源中国-Kubernetes存储系统-云原生存储Rook部署