BPF
BPF (Berkeley Packet Filter) 最早是用在 tcpdump 里面的,比如 tcpdump tcp and dst port 80 这样的过滤规则会单独复制 tcp 协议并且目的端口是 80 的包到用户态。整个实现是基于内核中的一个虚拟机来实现的,通过翻译 BPF 规则到字节码运行到内核中的虚拟机当中。最早的论文是这篇,这篇论文我大概翻了一下,主要讲的是原本的基于栈的过滤太重了,而 BPF 是一套能充分利用 CPU 寄存器,动态注册 filter 的虚拟机实现,相对于基于内存的实现更高效,不过那个时候的内存比较小才几十兆。bpf 会从链路层复制 pakcet 并根据 filter 的规则选择抛弃或者复制,字节码是这样的,具体语法就不介绍了,一般也不会去直接写这些字节码,然后通过内核中实现的一个虚拟机翻译这些字节码,注册过滤规则,这样不修改内核的虚拟机也能实现很多功能。
在 Linux 中对应的 API 是
socket(SOCK_RAW)
bind(iface)
setsockopt(SO_ATTACH_FILTER)
下面是一个低层级的 demo,首先 ethernet header 的十二个字节记录了 ip 的协议,ip 的第9个字节记录 tcp 的协议,如果协议编号不匹配都跳到最后 reject,然后在到 tcp 的第二个字节是 port 看看是不是 80,都满足的话就 accept。
#include <stdio.h> #include <string.h> #include <sys/types.h> #include <sys/socket.h> #include <net/if.h> #include <net/ethernet.h> #include <netinet/in.h> #include <netinet/ip.h> #include <arpa/inet.h> #include <netpacket/packet.h> #include <linux/filter.h> #define OP_LDH (BPF_LD | BPF_H | BPF_ABS) #define OP_LDB (BPF_LD | BPF_B | BPF_ABS) #define OP_JEQ (BPF_JMP | BPF_JEQ | BPF_K) #define OP_RET (BPF_RET | BPF_K) // Filter TCP segments to port 80 static struct sock_filter bpfcode[8] = { { OP_LDH, 0, 0, 12 }, // ldh [12] { OP_JEQ, 0, 5, ETH_P_IP }, // jeq #0x800, L2, L8 { OP_LDB, 0, 0, 23 }, // ldb [23] # 14 bytes of ethernet header + 9 bytes in IP header until the protocol { OP_JEQ, 0, 3, IPPROTO_TCP }, // jeq #0x6, L4, L8 { OP_LDH, 0, 0, 36 }, // ldh [36] # 14 bytes of ethernet header + 20 bytes of IP header (we assume no options) + 2 bytes of offset until the port { OP_JEQ, 0, 1, 80 }, // jeq #0x50, L6, L8 { OP_RET, 0, 0, -1, }, // ret #0xffffffff # (accept) { OP_RET, 0, 0, 0 }, // ret #0x0 # (reject) }; int main(int argc, char **argv) { int sock; int n; char buf[2000]; struct sockaddr_ll addr; struct packet_mreq mreq; struct iphdr *ip; char saddr_str[INET_ADDRSTRLEN], daddr_str[INET_ADDRSTRLEN]; char *proto_str; char *name; struct sock_fprog bpf = { 8, bpfcode }; if (argc != 2) {
printf("Usage: %s ifname\n", argv[0]); return 1; }
name = argv[1];
sock = socket(AF_PACKET, SOCK_RAW, htons(ETH_P_ALL)); if (sock < 0) {
perror("socket"); return 1; }
memset(&addr, 0, sizeof(addr));
addr.sll_ifindex = if_nametoindex(name);
addr.sll_family = AF_PACKET;
addr.sll_protocol = htons(ETH_P_ALL); if (bind(sock, (struct sockaddr *) &addr, sizeof(addr))) {
perror("bind"); return 1; } if (setsockopt(sock, SOL_SOCKET, SO_ATTACH_FILTER, &bpf, sizeof(bpf))) {
perror("setsockopt ATTACH_FILTER"); return 1; }
memset(&mreq, 0, sizeof(mreq));
mreq.mr_type = PACKET_MR_PROMISC;
mreq.mr_ifindex = if_nametoindex(name); if (setsockopt(sock, SOL_PACKET,
PACKET_ADD_MEMBERSHIP, (char *)&mreq, sizeof(mreq))) {
perror("setsockopt MR_PROMISC"); return 1; } for (;;) {
n = recv(sock, buf, sizeof(buf), 0); if (n < 1) {
perror("recv"); return 0; }
ip = (struct iphdr *)(buf + sizeof(struct ether_header));
inet_ntop(AF_INET, &ip->saddr, saddr_str, sizeof(saddr_str));
inet_ntop(AF_INET, &ip->daddr, daddr_str, sizeof(daddr_str)); switch (ip->protocol) { #define PTOSTR(_p,_str) \
case _p: proto_str = _str; break
PTOSTR(IPPROTO_ICMP, "icmp");
PTOSTR(IPPROTO_TCP, "tcp");
PTOSTR(IPPROTO_UDP, "udp"); default:
proto_str = ""; break; }
printf("IPv%d proto=%d(%s) src=%s dst=%s\n",
ip->version, ip->protocol, proto_str, saddr_str, daddr_str); } return 0; }
执行 curl “http://www.baidu.com”,结果如下:
sudo ./filter ens3
IPv4 proto=6(tcp) src=172.31.3.210 dst=220.181.112.244 IPv4 proto=6(tcp) src=172.31.3.210 dst=220.181.112.244 IPv4 proto=6(tcp) src=172.31.3.210 dst=220.181.112.244 IPv4 proto=6(tcp) src=172.31.3.210 dst=220.181.112.244 IPv4 proto=6(tcp) src=172.31.3.210 dst=220.181.112.244 IPv4 proto=6(tcp) src=172.31.3.210 dst=220.181.112.244 IPv4 proto=6(tcp) src=172.31.3.210 dst=220.181.112.244
这些低级别的操作都封装在了 libpcap 里面,一般不太会自己这么写。
eBPF
eBPF 是 extended BPF 具有更强大的功能。老的 BPF 现在叫 cBPF (classic BPF)。
首先是字节码的指令集更加丰富了,并且现在有了 64 位的寄存器(相较于上古时期的 32 位的CPU),有了 JIT mapping 技术和 LLVM 的后端。JIT 指的的是 Just In Time,实时编译。
一般的 ePBF 的工作流是编写一个 C 的子集(比如没有循环),通过 LLVM 编译到字节码,然成生成 ELF 文件,然后 JIT 编译进内核。
eBPF 一个最重要的功能是可以做到动态跟踪(dynamic tracing),可以不修改程序直接监控一个正在运行的进程。
在 eBPF 之前
在 ebpf 之前,为了实现同样的功能,要在执行的指令中嵌入 hook,并且支持跳到 inspect 函数,然后再恢复执行,这个流程和 debugger 非常相似,这是用 kprobe 来实现,kprobe 是 2007 年引入内核的。比如下面的例子,把 Instruction 3 改成跳转指令,然后再执行 Instruction 3,然后再跳转回去。
![image-20181110153643535.png]()
使用 kprobe 需要通过编译 kernel module 注册到内核当中,非常麻烦,等于是直接动内核的代码很容易引起内核 panic,而且每个内核版本都不一样,函数符号和位移是有区别的,对每个版本的内核都要编译一个对应的版本的 module。为了解决这个问题引入了一些静态的稳定的 trace point,不会因为版本而改变的地方可以插入 kprobe,但这样就限制了 kprobe 可以探测的范围。
有了 eBPF
有了 eBPF,就可以将用户态的程序插入到内核中,不用编写内核模块了,但是问题并没有改善,内核版本带来的问题还是没有解决。
eBPF 的 kprobe 一种方式时候 mapping,映射 kprobe 的数据到用户态程序,比如发包数,然后用户态程序定期检查这个映射进行统计。
另一种方式是 event (perf_events),如果 kprobe 向用户态程序发送事件来进行统计,这样不同轮询,直接异步计算就可以。
低级别的 API,这个只有 Linux 有
bpf() 系统调用
BPF_PROG_LOAD 加载 BPF 字节码
BPF_PROG_TYPE_SOCKET_FILTER
BPF_PROG_TYPE_KPROBE
BPF_MAP_* map 映射到 BPF 当中
perf_event_open() + ioctl(PERF_EVENT_IOC_SET_BPF)
高级别的接口是 bcc(BPFcompiler collection),转换 c 到 LLVM-epbf 后端,并且前端是 python 的。可以实现动态加载 eBPF 字节码到内核中。
weave scope 就是用 bcc 实现的 HTTP stats 的统计。
在这里可以看到程序的主体,这里 hook 了内核函数 skb_copy_datagram_iter,这个函数有一个 tracepoint trace_skb_copy_datagram_iovec。在内核代码里面对应的是下面这段。
/**
* skb_copy_datagram_iter - Copy a datagram to an iovec iterator.
* @skb: buffer to copy
* @offset: offset in the buffer to start copying from
* @to: iovec iterator to copy to
* @len: amount of data to copy from buffer to iovec
*/ int skb_copy_datagram_iter(const struct sk_buff *skb, int offset, struct iov_iter *to, int len) { int start = skb_headlen(skb); int i, copy = start - offset, start_off = offset, n; struct sk_buff *frag_iter;
trace_skb_copy_datagram_iovec(skb, len);
这里对这个 hook 注册了程序,具体的代码就不展示了,主要是根据协议统计这个 HTTP 的大小,方法等信息。
/* skb_copy_datagram_iter() (Kernels >= 3.19) is in charge of copying socket
* buffers from kernel to userspace.
*
* skb_copy_datagram_iter() has an associated tracepoint
* (trace_skb_copy_datagram_iovec), which would be more stable than a kprobe but
* it lacks the offset argument.
*/ int kprobe__skb_copy_datagram_iter(struct pt_regs *ctx, const struct sk_buff *skb, int offset, void *unused_iovec, int len) {
比如判断 method 是不是 DELETE 的是实现就比较蠢,是因为 eBPF 不支持循环,只能这么实现才能把 c 代码翻译成字节码。
case 'D': if ((data[1] != 'E') || (data[2] != 'L') || (data[3] != 'E') || (data[4] != 'T') || (data[5] != 'E') || (data[6] != ' ')) { return 0; } break;
除了 bcc 之外,waeve 使用了 gobpf,一个 bpf 的 go binding,并且通过建立 tcp 连接来猜测内核的数据结构,以达到内核版本无关,这个项目 tcptracer-bpf 还在开发中。
eBPF 的其他应用
还有一个比较大头的基于 eBPF 的是 cilium,一套比较完整的网络解决方案,用 eBPF 实现了 NAT,L3/L4 负载均衡,连接记录等等功能。比如访问控制,一般的 iptables 都是 drop 或者 rst,要过整个协议栈,但是 eBPF 可以在 connect 的时候就拦截然后返回 EACCESS,这样就不用过协议栈了。cilium 一个优化就是通过 XDP ,利用类似 DPDK 的加速方案,hook 到驱动层中,让 eBPF 可以直接使用 DMA 的缓冲,优化负载均衡。
BPF/XDP allows for a 10x improvement in load balancing over IPVS for L3/L4 traffic.
现在 k8s 最新的 lb 方案是基于 ipvs 的,我在 kube-proxy 分析 里面有提到过,已经比原来的 iptables 提高很多了,现在有了 eBPF 加 XDP 的硬件加速可以实现更高的提升,facebook 的 katran L4 负载均衡器的实现也是类似的。
cilium 在我看来基本上是 k8s 网络的一个大方向吧,只不过包括 eBPF 和 XDP 对硬件和内核版本都要比较新,是一个要持续关注的更新。
性能调优
在Velocity 2017: Performance Analysis Superpowers with Linux eBPF里,Brendan Gregg (Netflix 的性能调优专家) 提到,性能调优也是 eBPF 的一个大头。用于网络监控其实只是 hook 在了协议栈的函数上,如果 hook 在别的地方可以有更多的统计维度。比如 bcc 官方的例子就是统计 IO Size 的大小的分布,更多关于基于 eBPF 的性能调优可以参考他的 blog,他给出了更详细的关于 eBPF 的解释,里面有一些列 Linux 性能调优的内容。
# ./bitehist.py Tracing... Hit Ctrl-C to end. ^C
kbytes : count distribution
0 -> 1 : 3 | | 2 -> 3 : 0 | | 4 -> 7 : 211 |********** | 8 -> 15 : 0 | | 16 -> 31 : 0 | | 32 -> 63 : 0 | | 64 -> 127 : 1 | | 128 -> 255 : 800 |**************************************|
安全
在安全方面有 seccomp,可以实现限制 Linux 的系统调用,而 seccompe-bpf 则是通过 bpf 支持更强大的过滤和匹配功能,k8s pod 里面的 SecurityContext 就有 seccomp 实现的部分。
cgroup
在 cgroup 上有一个小原型,cgnet 获取 cgroup 的网络统计信息到 prometheus,也是基于 eBPF 的。
本文转自中文社区-Kubernetes 中的 eBPF
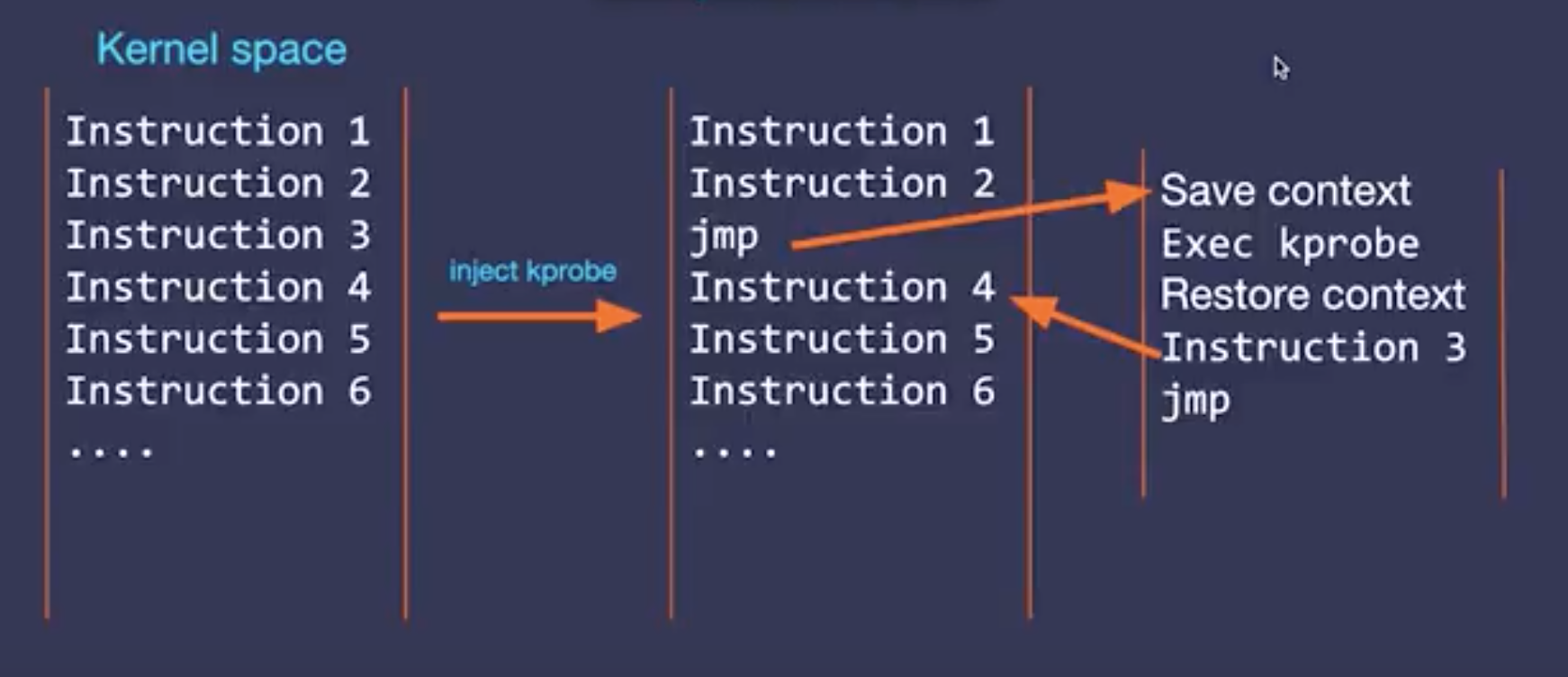 使用 kprobe 需要通过编译 kernel module 注册到内核当中,非常麻烦,等于是直接动内核的代码很容易引起内核 panic,而且每个内核版本都不一样,函数符号和位移是有区别的,对每个版本的内核都要编译一个对应的版本的 module。为了解决这个问题引入了一些静态的稳定的 trace point,不会因为版本而改变的地方可以插入 kprobe,但这样就限制了 kprobe 可以探测的范围。
使用 kprobe 需要通过编译 kernel module 注册到内核当中,非常麻烦,等于是直接动内核的代码很容易引起内核 panic,而且每个内核版本都不一样,函数符号和位移是有区别的,对每个版本的内核都要编译一个对应的版本的 module。为了解决这个问题引入了一些静态的稳定的 trace point,不会因为版本而改变的地方可以插入 kprobe,但这样就限制了 kprobe 可以探测的范围。
