Kubernetes本身具有包含了具有大量用例且功能强大的存储子系统。然而,如果我们利用Kubernetes建设关系数据库平台,就需要面临一个挑战:建立数据存储。本文用来讲述如何扩展CSI(容器存储接口)0.2.0同时整合Kubernetes,并且展示了动态扩容的重要性。
简介
随着我们对客户的关注,尤其是对金融领域的客户,我们可以发现容器编排技术具有很大的发展空间。开发者们希望能通过开源解决方案来重新设计运行在虚拟化基础设施和裸金属上的独立应用程序。
对于可扩展性和技术成熟度两方面,Kubernetes和Docker处于业内的顶端。关系数据库对于迁移至关重要,但是将独立应用程序迁移到像Kubernetes这样的分布式编配十分具有挑战性。
对于关系型数据库来说,我们应该关注其存储功能。Kubernetes本身具有强大的存储子系统,其功能强大,包含用例广泛。如果我们利用kubernetes建设关系数据库平台,就需要面临一个挑战:建立数据存储。但是Kubernetes还有一些基本的功能没有实现,尤其是动态扩容。这听起来很无聊,但是创建、删除、挂载和卸载等操作非常必要。
目前,扩容只能与存储提供程序一起使用,例如:
-
gcePersistentDisk
-
awsElasticBlockStore
-
OpenStack Cinder
-
glusterfs
-
rbd
为了启用这个特性,我们需要设置feature-gate expandpersistentvolume为True,并打开PersistentVolumeClaimResize准入插件。一旦启用了PersistentVolumeClaimResize,调整存储大小的功能将被allowVolumeExpansion设置为True的存储类开启。
不幸的是,即使底层存储提供程序具有此功能,通过容器存储接口(CSI)和Kubernetes动态扩容依然不可用。
本文将给出CSI的简化视图,然后介绍如何在现有的CSI和Kubernetes上引入一个新的扩展卷特性。最后,本文将演示如何动态地扩容。
容器存储接口(CSI)
为了更好地理解我们之后的工作,首先我们需要知道容器存储接口是什么。目前来看,Kubernetes现有的存储子系统依然存在很多问题。存储驱动程序代码维护在Kubernetes core存储库中,这一问题使测试十分不便。但除此之外,Kubernetes还需要授权存储供应商将代码签入Kubernetes核心存储库。但是理想情况下,这种需求应该在外部实现。CSI的设计目的是定义一个行业标准,该标准将使支持CSI的容器编排系统可用的存储提供者能够使用CSI。
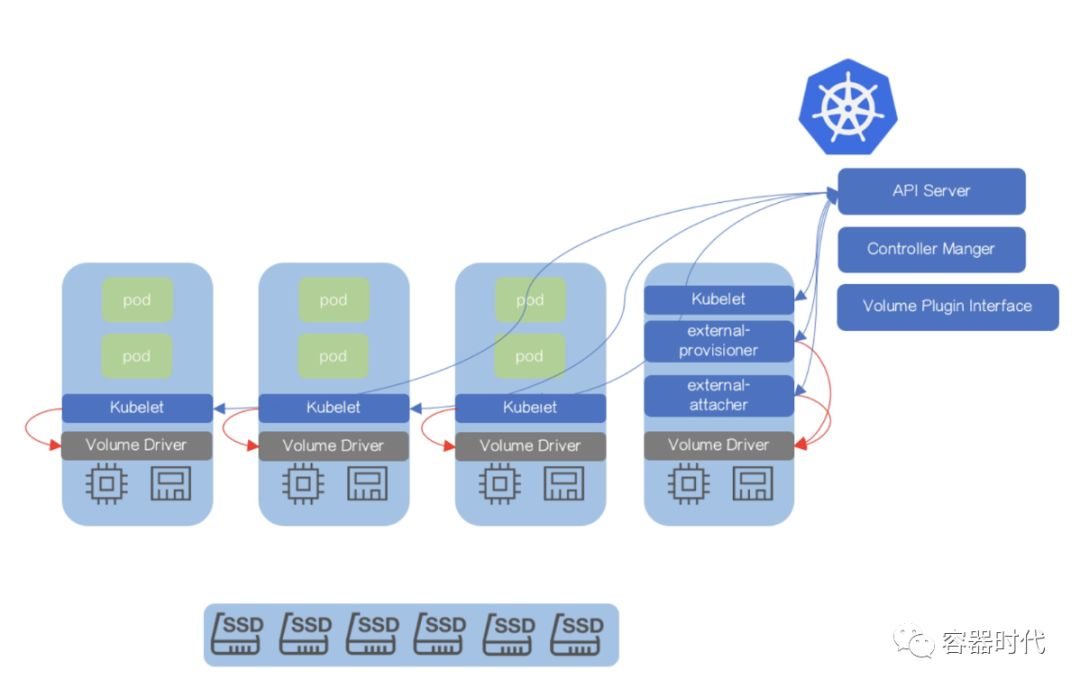
这张图描绘了一种与CSI结合的高级Kubernetes原型:
![]()
扩展CSI和Kubernetes
为了实现在Kubernetes上扩展卷的功能,我们应该扩展多个组件,包括CSI规范、“In-Tree”卷插件、外部供应器和外部连接器。
扩展CSI规范
最新的CSI 0.2.0中还没有定义扩展量的特性。应该引入新的3个rpc,包括RequiresFSResize,ControllerResizeVolume和NodeResizeVolume。
service Controller { rpc CreateVolume (CreateVolumeRequest) returns (CreateVolumeResponse) {} …… rpc RequiresFSResize (RequiresFSResizeRequest) returns (RequiresFSResizeResponse) {} rpc ControllerResizeVolume (ControllerResizeVolumeRequest) returns (ControllerResizeVolumeResponse) {} } service Node { rpc NodeStageVolume (NodeStageVolumeRequest) returns (NodeStageVolumeResponse) {} …… rpc NodeResizeVolume (NodeResizeVolumeRequest) returns (NodeResizeVolumeResponse) {} }
扩展“In-Tree”卷插件
为了扩展CSI规范,csiPlugin接口需要在Kubernetes上实现。csiPlugin接口将会扩展PersistentVolumeClaim用来代理ExpanderController。
type ExpandableVolumePlugin interface { VolumePlugin ExpandVolumeDevice(spec Spec, newSize resource.Quantity, oldSizeresource.Quantity) (resource.Quantity, error) RequiresFSResize() bool }
实现盘卷驱动
最后,为了抽象实现的复杂性,我们应该将单独的存储提供程序管理逻辑硬编码到CSI规范中定义的以下函数中:
-
CreateVolume
-
DeleteVolume
-
ControllerPublishVolume
-
ControllerUnpublishVolume
-
ValidateVolumeCapabilities
-
ListVolumes
-
GetCapacity
-
ControllerGetCapabilities
-
RequiresFSResize
-
ControllerResizeVolume
示例:
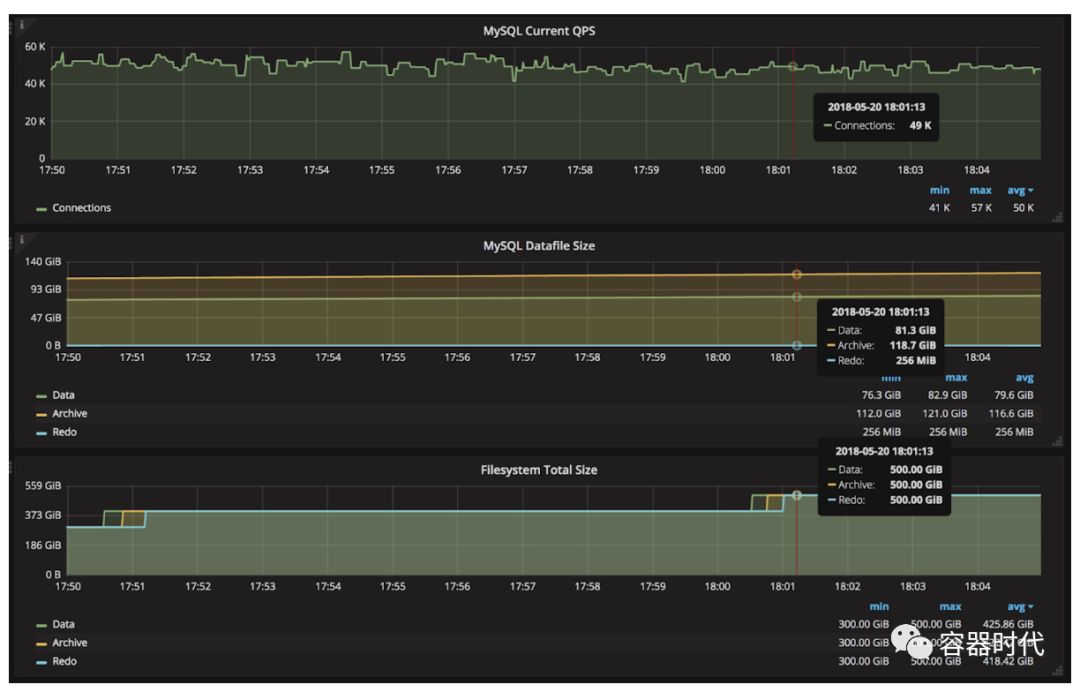
让我们用一个具体的用户案例来演示这个特性。
Prometheus和Grafana的集成使我们可视化相应的关键指标。
![]()
结论:
无论基础设施应用程序运行在何处,数据库始终是一个关键资源。用高级的存储子系统来完全支持数据库需求非常重要。这将有助于推动更广泛地采用云本地技术。
本文转自中文社区-
使用CSI和Kubernetes实现动态扩容