俗话说的话,没有完整使用过ECS产品的程序员不是好的程序员(好吧,其实是我说的)。当然,控制台操作或者用OpenAPI也没有必要去写一篇文章,所以那就来点儿有意思的。我们来说说,怎么用Packer和Terraform,这两个开源基础架构自动化编排工具,来快速搭建一个即拿即用的迷你并行计算集群(当然,这里的并行计算集群的网络知识普通的以太网互联啦)。
暂时先不说Packer和Terraform这两个工具到底是干什么的,我们先来看看一个迷你并行计算集群应该具备的条件是什么,然后从这个角度出发,具体说明怎么使用这两个工具,快速构建,开箱即用。
一、迷你并行计算集群条件:
- 集群中包括一台以上的计算节点
- 集群中的任意两个节点间SSH可以免密登录且不需要远程SSH主机的公钥检查
- 所有节点之间有共享目录(如,基于NFS)
- 只有一个节点作为跳板机提供公网出口IP,其他节点不提供公网出口IP,只使私有IP互联
- 每个节点上包含一些基本的软件或者库(如用于搭建NFS服务的rpc,nfs包,以及基本的并行计算库,如openMPI库等)
只要满足了以上这五点,你就可以用这个计算机群去跑一些简单的并行计算任务啦,比如说一些简单的MPI应用,一个开箱即用,用完销毁的并行计算集群对于一个MPI应用的测试和开发都是非常方便的。
二、说说Packer与Terraform两兄弟:
Packer和Terraform是两个很流行的用于云上基础设施管理的自动化工具。更直接的说法就是“基础设施即代码(Infrastracture as Code)”,通过代码的方式来管理基础设施从构建到销毁整个生命周期。
Packer通过一个模板文件来创建基于云平台一致的自定义镜像,通过用户定义的个性化镜像,实现快速创建新的虚拟机运行实例。就和Docker中的Dockerfile类似,通过文件的方式来定义一个自定义镜像,并且Packer可以帮助用户去验证镜像可用性。
Packer的工作流程很简单:
- 先启动实例
- 上传并运行用户的脚本或者通过其他Puppet/Chef配置管理工具,定制实例的环境
- 对实例打快照
- 最后再根据快照生成镜像。
有了Packer做的镜像之后,当然就是在用这个镜像来创建可用的实例啦。
操作云服务,其中一种方法就是利用云平台提供的各类API来进行操作,这个时候Terraform出现了,他的出现帮助你省去了写大量复杂的操作云平台代码的过程,取而代之的是通过目的式的操作,通过模板编排的方法,维护了一份云服务状态的模板,而不需要在意到底用什么API命令来做到。
三、进入实战环节
关于Packer和Terraform的安装,十分简单,自行google即可。
1.创建免密登录且不需要远程SSH主机的公钥检查的基础镜像
对于MPI程序来说,比较重要的一点就是主机间需要SSH免密登录(因为MPI程序在启动的时候需要主机间的免密登录)。所以这里先简单科普一下SSH的两种登录机制。一个是口令机制(即用密码登录),另一个是公钥机制。两种机制本质都是利用了不对称加密机制中公钥加密私钥解密原理,不同点就是谁用谁的公钥加密什么东西,听起来似乎有点儿绕,那我这么来解释,假设现在有两个机器,机器A使用SSH登录到机器B:
- 口令机制:认证过程是,A用B的公钥加密登录密码,并发给B,B用其自己的私钥解密,核对密码正确性。下图是一个使用口令机制登录的完整流程。
![a.口令登录机制]()
- 公钥机制:认证工程是,B用A的公钥加密随机字符串R,并发给A,A用自己的私钥解密R,并将R和本次会话的SessionKey用MD5加密得到D1,再发回给B,B比对收到的D1和自己用R和SessionKey生成的D2是否相同。下图是一个使用公钥机制登录的完整流程。
![b.公钥机制登录]()
(注意:验证成功后的后续通信,都是通过对称加密的方式,具体怎么获得这个对称加密的秘钥,比较复杂,请自行google)
所以,回到怎么制作SSH免密登录镜像,可以发现,只需要在制作镜像的实例中,先生成一对公钥私钥,然后将公钥拷贝至主机用于保存其他主机公钥的文件中即可,即将生成的id_rsa.pub放到~/.ssh/authorized_keys中。这样因为所有的计算节点中都用的同一个镜像,所以任意一个节点A登录到其他节点B,B中总包含着A的公钥,于是SSH免密登录就做到了。当然,只做到这一步还不行,因为你会发现,当第一次登录的时候,本机会进行远程SSH主机的公钥检查,即提示你即将接收远程主机的公钥密纹,是否确认接收此公钥。所以为了防止第一次登录出现这种情况,你需要禁用远程主机的公钥检查,即需要配置ssh_config,设置StrictHostKeyChecking为no。(文章末尾会提供完整的github目录,供参考)
除了免密登录外,基础镜像中还需要添加各类基础软件,比如需要安装NFS和RPC相关组件,以及一些高性能计算相关的库如openMPI等。以上的所有镜像相关配置,或者软件安装过程都可以放在一个脚本中来完成。我们知道Packer本质就是用JSON配置文件描述的方式帮助我们完成了上面所说的4个过程。我觉得直接从我的JSON配置文件来说明Packer更直观一些。
{
"variables": {
"access_key": "your access_key",
"secret_key": "your secret_key"
},
"builders": [{
"type":"alicloud-ecs",
"access_key":"{{user `access_key`}}",
"secret_key":"{{user `secret_key`}}",
"region":"cn-beijing",
"image_name":"small_hpc_image",
"source_image":"centos_7_04_64_20G_alibase_201701015.vhd",
"instance_name":"base_hpc_instance",
"vpc_id":"vpc-***********lcdnky",
"vswitch_id":"vsw-***********vz0hw382yd",
"security_group_id":"sg-***********2ufql1ic8",
"ssh_username":"root",
"instance_type":"ecs.t5-lc1m2.small",
"internet_max_bandwidth_out":"1",
"io_optimized":"true",
"image_force_delete":"true",
"internet_charge_type":"PayByTraffic",
"ssh_password":"your password"
}],
"provisioners": [{
"type": "file",
"source": "ImageScript.sh",
"destination": "/tmp/"
},{
"type": "shell",
"inline": [
"sleep 30s",
"cd /tmp",
"chmod 755 ImageScript.sh",
"./ImageScript.sh > log"
]
}]
}
- variables:存放一些用户自定义的基础变量值,比如你可以存放你的ak,sk等
- builders: 是一个JSONarray,它会是读取配置然后创建用于制作镜像的实例,每个JSON代表了一个实例,并且builders中的参数是随着你使用的云厂商不同而不同,你需要参考Packer的官方手册,不过会有一些公共的变量如ssh_username,ssh_password等。在本例子中,由于使用的是阿里云,所以我们需要制定诸如基础镜像,网络配置,实例密码等。(这里有一些非常“重要”的坑后文会着重说明)
- provisioners:这个是用户自定义的一些操作,比如上传脚本,并运行相关脚本等操作,方便用户自定义相关镜像中的内容。这里我们就可以将上文中关于SSH免密登录,以及相关软件安装的过程,封装成一个脚本ImageScript.sh。provisioners中定义了很多类型的用户操作,比如上面配置中的file类型和shell类型,分别对应着用户上传本地文件和执行bash脚本的行为,当然还有很多其他行为,大家可以参考Packer文档。
下面这些话是我个人在使用Packer上遇到的一些小坑,写出来希望大家可以减少踩到的几率。
- openAPI中创建实例,一般只需要制定虚拟交换机id和安全组id即可,但是packer需要注意的是,一定要同时指定vswitch_id相关联的vpc_id。
- 务必将出口带宽internet_max_bandwidth_out值设置大于0,或者绑定弹性网卡,同时记得设置ssh_password登录密码。因为packer在使用provisioners时,会利用ssh从公网登录到机器的实例中,再进行后续操作。所以公网出口带宽设置大于0的目的就在于,实例创建后会有公网IP地址,供packer使用。
2.编排启动属于你的迷你并行计算集群
有了Packer制作的镜像之后,就到了Terraform来编排计算集群中各个节点的启动顺序,以及启动之后需要加载的配置项等行为。根据我们的需求,整个集群只有一个节点对外拥有公网IP(即将这个节点作为一个跳板),并且集群中所有节点拥有一个NFS共享目录。要做到这些,我们用一个图来展示编排的行为。这里有一个假设就是,我们用某一个节点下挂载的云盘中的某一目录,作为所有节点的共享目录。(当然这里我很推荐大家使用阿里云的NAS文件存储,设置更快速的CPFS,让所有节点都挂载在NAS上,这样就不用考虑在启动时那个节点作为NFS Server了。)
下图中,箭头从A指向B,表示B的成功依赖于A的完成 ![]() 上面的这个图我觉得比较清晰的展现了各类资源、实例应该以什么顺序启动。那么Terraform就是一个编排工具帮我们完成上面所有的资源创建,并且可以通过显示或者隐式的方式,确保资源之间创建的相互依赖关系,这一点十分类似Spark中的DAG(terraform对于没有依赖关系的资源会并行的创建)。下面我从terrafomr提供的基本命令和主要配置项大致讲解一下Terraform的一些基础知识。
上面的这个图我觉得比较清晰的展现了各类资源、实例应该以什么顺序启动。那么Terraform就是一个编排工具帮我们完成上面所有的资源创建,并且可以通过显示或者隐式的方式,确保资源之间创建的相互依赖关系,这一点十分类似Spark中的DAG(terraform对于没有依赖关系的资源会并行的创建)。下面我从terrafomr提供的基本命令和主要配置项大致讲解一下Terraform的一些基础知识。
基本命令:terraform和git有些相似,在使用前需要创建一个目录,并创建一个.tf文件(官方称tf就是terraform format格式,其自创的一种语法格式)。此文件中需要指定provider的信息(即你使用的是哪个云厂商进行操作)。以下列出了4个基本的操作
- terraform init:初始化操作,terraform会根据tf文件中的provider厂商,下载相应厂商的可执行二进制库,也就是为apply提供正确环境
- terraform plan:执行预览,可以看到此配置文件将展示怎么的一个云服务状态
- terrafrom apply:执行编排操作
- terraform destroy:销毁当前状态下所有的云服务资源
主要配置项:包括provider配置项,data配置项,和resource配置项。
- provider:上文也说了,用于声明你需要使用的云厂商是谁,并且指明access_key和secret_key还有region的相关信息等
- data: 用来查询某个资源的相关情况,比如本例子中,就使用data配置项并结合过滤条件来找到我在上一节创建的镜像id。除此之外还可以进行过滤出用户需要的资源信息(如可用的实例类型等等,可参考https://www.terraform.io/docs/configuration/data-sources.html)
- resource:此配置项是最为中的,它关系到你所创建的资源的所有状态,包括创建vpc,安全组,虚拟交换机,以及最为重要的实例。资源之间的相关关系,通过隐式声明和显示声明进行表述。隐式声明主要通过tf的表达式表示,比如下面阐述的例子用vswitch资源的表示中,中就使用了表达式${alicloud_vpc.vpc.id}来表示使用创建的vpc资源的id。而显示声明更简单,直接使用depends_on来指名,如在创建nfs client节点时,就需要依赖nfs server节点已经创建并初始化完成。
下面,我们直接从构建这个迷你并行计算集群的tf配置文件来解读,从而对整个terraform的用法有更直观的理解,大家可以根据文件中的注释来进一步理解。
# Configure the Alicloud Provider
# 创建一个拥有公网IP的ECS服务器,且需要运行脚本命令初始化服务器
# 用户可以将类似ak,sk这些环境变量定义在其他tf文件中,并将需要声明的变量用一下方式声明
# variable "access_key" { default = "xxxxxxx"}
provider "alicloud" {
access_key = "${var.access_key}"
secret_key = "${var.secret_key}"
region = "${var.region}"
}
# 创建一个vpc,CIDR为172.16.0.0/12"
resource "alicloud_vpc" "vpc" {
name = "small_hpc_vpc"
cidr_block = "172.16.0.0/12"
description ="this is a example vpc for small_hpc_cluster"
}
# 创建一个vswitch,vsw的创建依赖于vpc的创建,即vsw必须附属于某一个vpc
resource "alicloud_vswitch" "vsw" {
name = "small_hpc_vsw"
vpc_id = "${alicloud_vpc.vpc.id}"
cidr_block = "${var.cidr_block}"
availability_zone = "${var.zoneid}"
description = "this is a example vsw for small_hpc_cluster"
}
# 基于某一个VPC创建安全组
resource "alicloud_security_group" "group" {
name = "small_hpc_security_group"
vpc_id = "${alicloud_vpc.vpc.id}"
}
# 创建一个安全组
resource "alicloud_security_group" "default" {
name = "small_hpc_default"
description = "a security for small_hpc_default"
vpc_id = "${alicloud_vpc.vpc.id}"
}
# 获取镜像的id
data "alicloud_images" "images_ds" {
owners = "self"
name_regex = "^small_hpc_image"
}
# 创建一个实例,同时这个实例也作为NFS的Server运行
# Create a machine and at same time this machine is NFS server
resource "alicloud_instance" "master" {
availability_zone = "${var.zoneid}"
image_id = "${data.alicloud_images.images_ds.images.0.id}"
security_groups = ["${alicloud_security_group.default.id}"]
instance_name = "${var.base_nstance_name}"
instance_type = "${var.instance_type}"
vswitch_id = "${alicloud_vswitch.vsw.id}"
internet_charge_type = "${var.internet_charge_type}"
internet_max_bandwidth_out = "1"
# ALicloud OpenAPI中定义的参数,用户可以将bash文件传入其中(不大于16k,且需要注意terraform不要将文本用
# base64方式编码,这里和OpenAPI文档有一些出入)
user_data = "#!/bin/sh\n mkdir -p /root/share"
host_name = "hpc0"
password = "${var.password}"
private_ip = "${cidrhost(var.cidr_block, count.index+1)}"
# 用户自定义操作,file表示实例启动后,将本地文件或者目录拷贝到指定实例目录中
provisioner "file" {
source = "nfs_server_script.sh"
destination = "/tmp/nfs_server_script.sh"
}
provisioner "file" {
source = "mpi_testfile"
destination = "/root/share"
}
# 用户自定义操作,remote表示实例启动后,在实例中执行用户所要求的命令
provisioner "remote-exec" {
inline = [
"cd /tmp && chmod 700 nfs_server_script.sh",
"./nfs_server_script.sh > nfs_server_script_log",
]
}
# 和provider相关,指定使用SSH方式连接到实例来执行用户自定义操作(注意请务必保证实例有公网IP)
# 且host务必显示指定
connection {
host = "${alicloud_instance.master.public_ip}"
type = "ssh"
user = "root"
password = "${alicloud_instance.master.password}"
timeout = "10s"
}
}
# 定义输出值,在使用terraform apply完成创建后,控制台会用高亮显示输出定义的值,或者也可以通过命令
# terraform output public_ip获取相应值
output "public_ip" {
value = "${alicloud_instance.master.public_ip}"
}
# 创建两个安全组规则,一个是为了方面SSH登录,允许1-65545端口入方向
resource "alicloud_security_group_rule" "allow_22_tcp" {
type = "ingress"
ip_protocol = "tcp"
nic_type = "intranet"
policy = "accept"
port_range = "1/65535"
priority = 1
security_group_id = "${alicloud_security_group.default.id}"
cidr_ip = "0.0.0.0/0"
}
resource "alicloud_security_group_rule" "allow_icmp"{
type = "ingress"
ip_protocol = "icmp"
nic_type = "intranet"
policy = "accept"
port_range = "-1/-1"
priority = 1
security_group_id = "${alicloud_security_group.default.id}"
cidr_ip = "0.0.0.0/0"
}
# 创建其他节点,同事其他节点也作为NFS的client节点
resource "alicloud_instance" "slave" {
# count 表示创建该实例的个数
count = "${var.node_count}"
availability_zone = "${var.zoneid}"
image_id = "${data.alicloud_images.images_ds.images.0.id}"
security_groups = ["${alicloud_security_group.default.id}"]
instance_name = "${var.base_nstance_name}"
instance_type = "${var.instance_type}"
vswitch_id = "${alicloud_vswitch.vsw.id}"
internet_charge_type = "${var.internet_charge_type}"
# terraform提供了丰富的表达式写法和内建函数。如下面的count.index会获取到当前创建的资源是第几个资源
host_name = "hpc${count.index+1}"
# cidrhost内建函数更为强大,可以根据cidr_block和某一整数值计算出当前网络地址下对应主机地址
private_ip = "${cidrhost(var.cidr_block, count.index+2)}"
# file内建函数用于读取本地某一文件
user_data = "${file("nfs_client_script.sh")}"
depends_on = ["alicloud_instance.master"]
}
上面的配置文件展示了Terraform一般用法,当然Terraform提供了非常丰富的使用场景,以及强大的语法表达式,和内建函数。在使用过程中,建议大家阅读terraform的官方手册,来更进一步学习。当然本人在第一次使用的时候也是遇到了各种各样的“坑”,比如user_data在terraform中不需要进行base64编码,以及必须制定connection中host主机地址等。
下面就是我们创建编排资源的时候啦。我们在包含tf的目录下,输入terraform apply,terraform会打印出当前行为期望的执行过程,这个时候再敲入yes,然后等待几分钟你的编排好的实例就创建好啦。
![]()
现在我们登录到集群中执行一个简单的MPI helloworld程序,当你看到如下画面就表明你的迷你并行计算集群已经可以即拿即用啦,当你用完此集群后,直接键入terraform destory销毁这些资源即可。
![]()
好啦,Terraform的用法我觉得点到为止就好啦,这个例子已经囊括了绝大多数的使用方法,所以大家可以到本人的github上下载源码https://github.com/xiaobaidemu/smallhpc_terraform,感受一下(记得添加上你自己的ak和sk,以及password)。
参考文章:


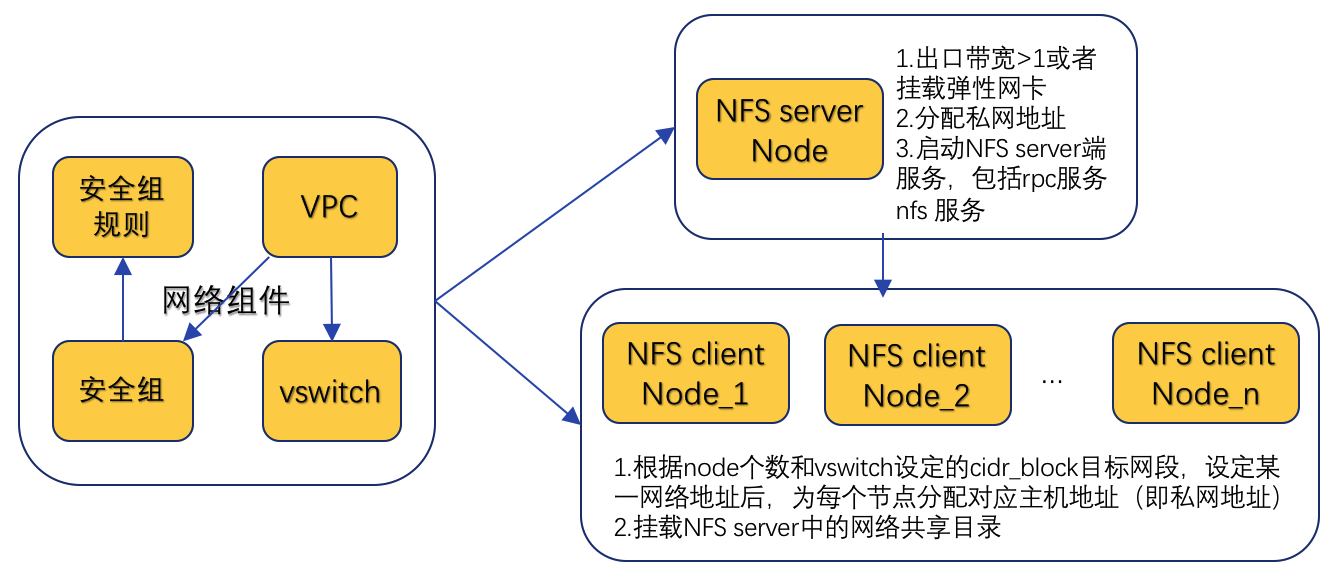 上面的这个图我觉得比较清晰的展现了各类资源、实例应该以什么顺序启动。那么Terraform就是一个
上面的这个图我觉得比较清晰的展现了各类资源、实例应该以什么顺序启动。那么Terraform就是一个