实现目标
昨天晚上看完碟中谍后,有点小激动,然后就有了这片文章。
我们将猫眼上碟中谍的全部评论保存下来,用于后期分析~
总共评论3W条左右。
逻辑梳理
-
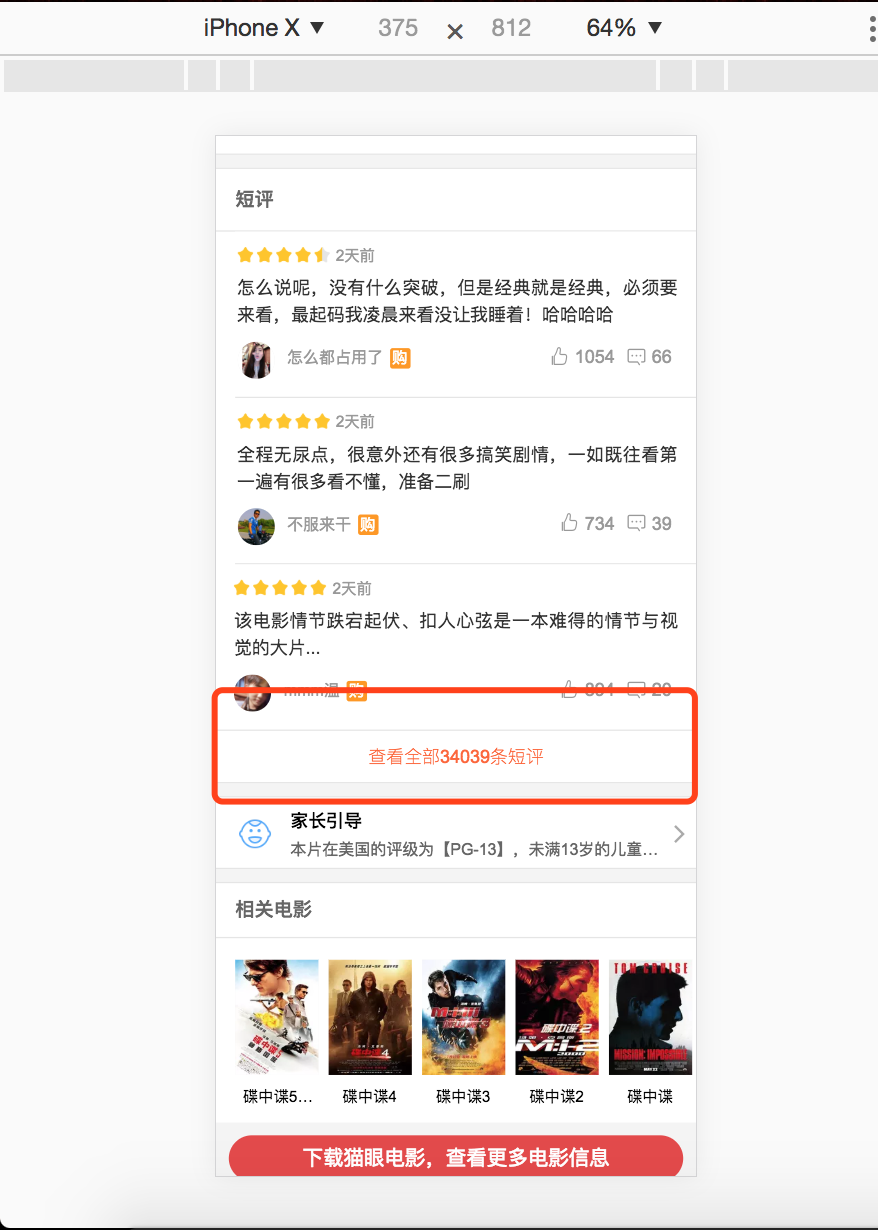
猫眼PC网页只能查看热门评论,只有在手机端页面才能查看全部评论。我们用chrome手机模式打开碟中谍6的页面,然后找到了全部评论入口:
-
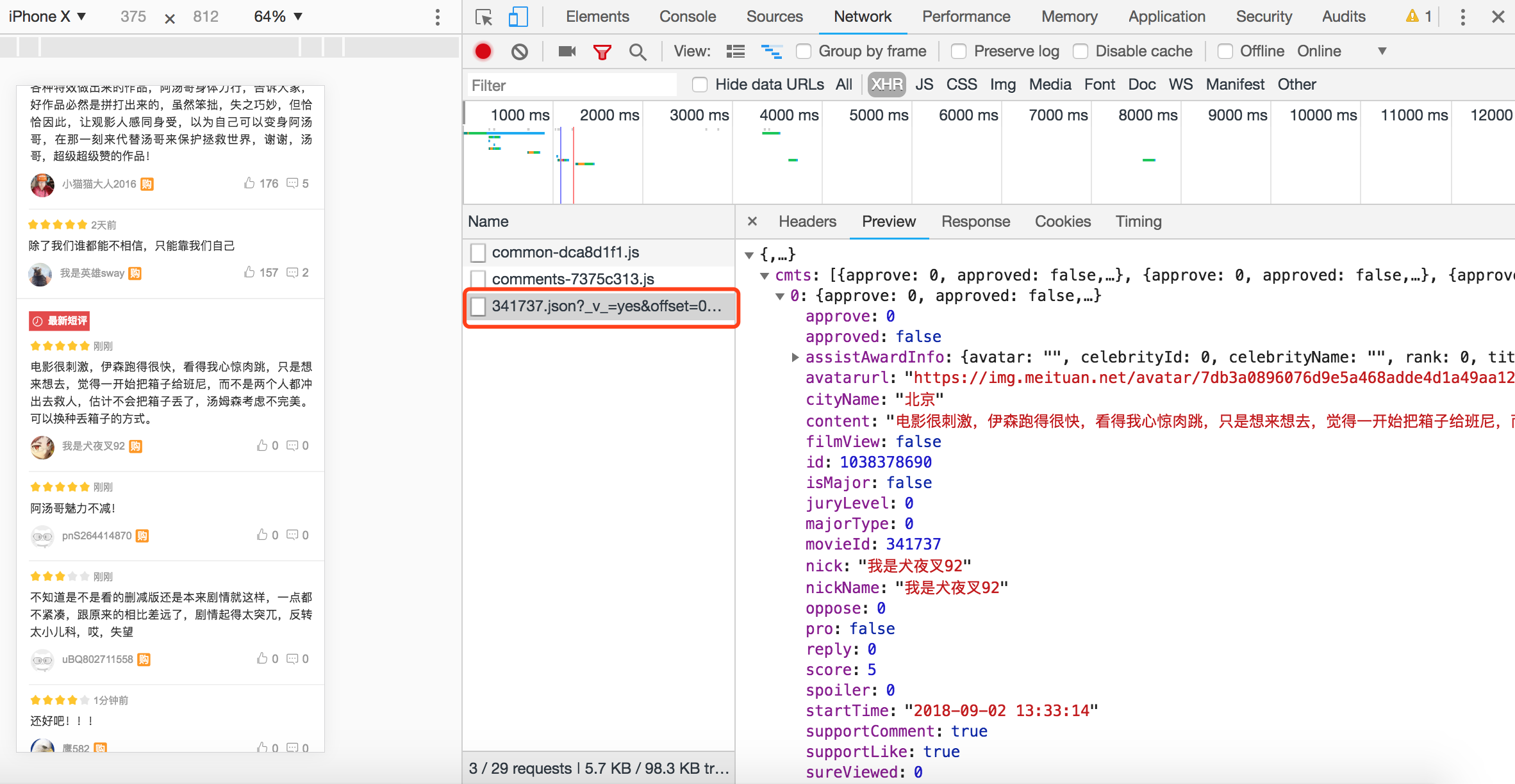
当我们将评论页面向上拖,后台请求中变看到了我们想要的接口地址:http://m.maoyan.com/mmdb/comments/movie/341737.json?_v_=yes&offset=15&startTime=2018-09-02%2013%3A33%3A14
-
请求地址中的参数:
- offset:偏移量
- startTime:查询起始时间
- 341737:电影ID
- 还有一个V不知道啥意思,不过没啥影响
其实正常来说到这儿就差不多了,按照以往的套路循环传入offset参数就好了,不过当我爬到第67页的时候,就已经不返回值了,为啥是67,67![\times]() 15=1005,猫眼应该是控制了每个startTime只能往前取1000条评论,所以只能换个思路,将每页最早一条评论的时间作为startTime传入,offset固定15就好了。
15=1005,猫眼应该是控制了每个startTime只能往前取1000条评论,所以只能换个思路,将每页最早一条评论的时间作为startTime传入,offset固定15就好了。
-
最后效果
代码部分
- Talk is cheap. Show me the code.
# -*- coding:utf-8 -*-
import requests
from datetime import datetime
import time
from tqdm import tqdm
from random import random
class MaoYan():
"""docstring for ClassName"""
def __init__(self, movie_id):
print '*******MaoYan_spider******'
print 'Author : Awesome_Tang'
print 'Date : 2018-09-01'
print 'Version: Python2.7'
print '**************************\n'
self.movie_id = movie_id
self.starttime = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
self.starturl = 'http://m.maoyan.com/mmdb/comments/movie/%s.json?_v_=yes&offset=0&startTime=%s'%(movie_id,self.starttime)
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'}
def GetCommentNum(self):
'''
查询总评论数
用于建立循环
'''
response = requests.get(self.starturl,headers = self.headers)
text = response.json()
num = text['total']
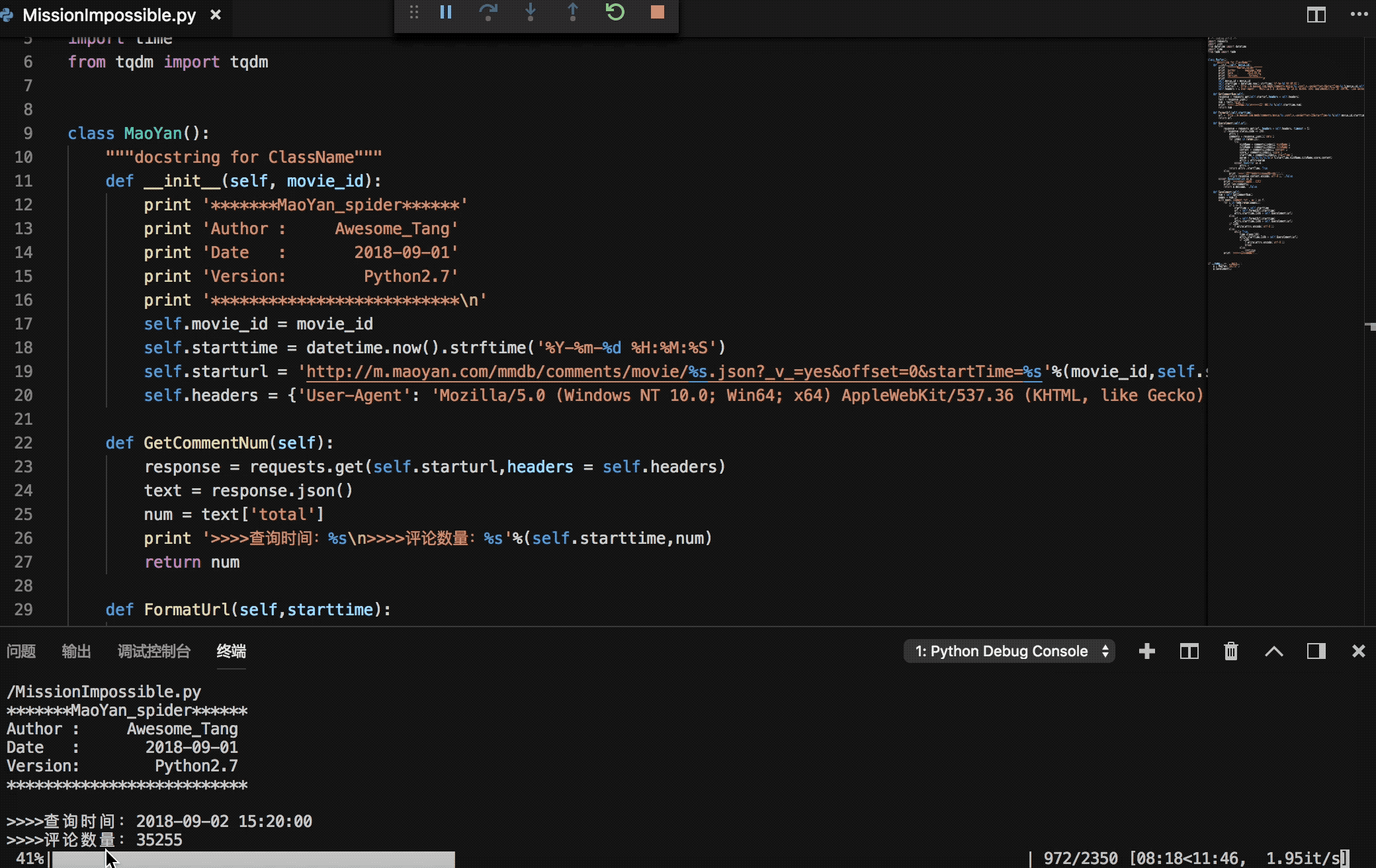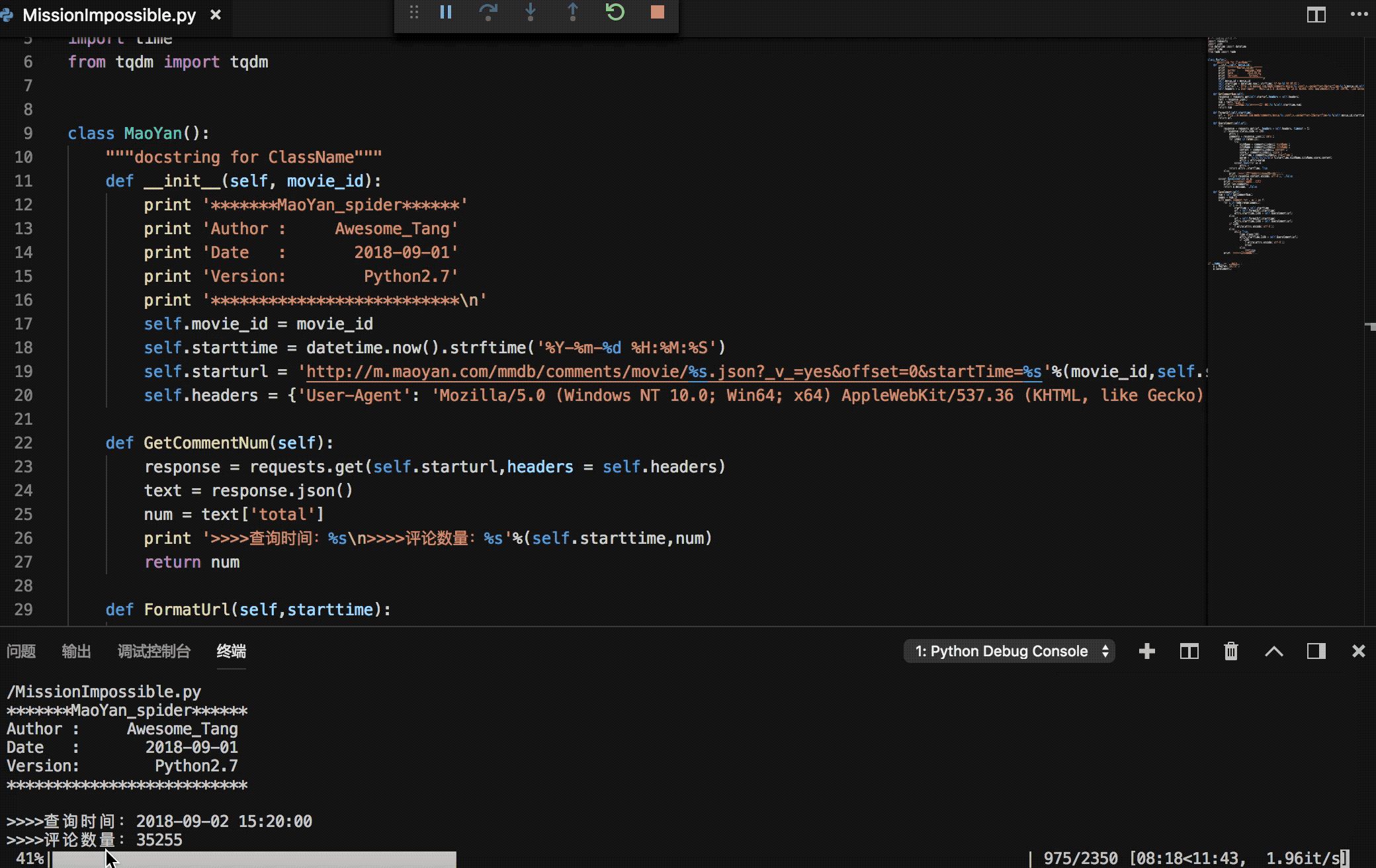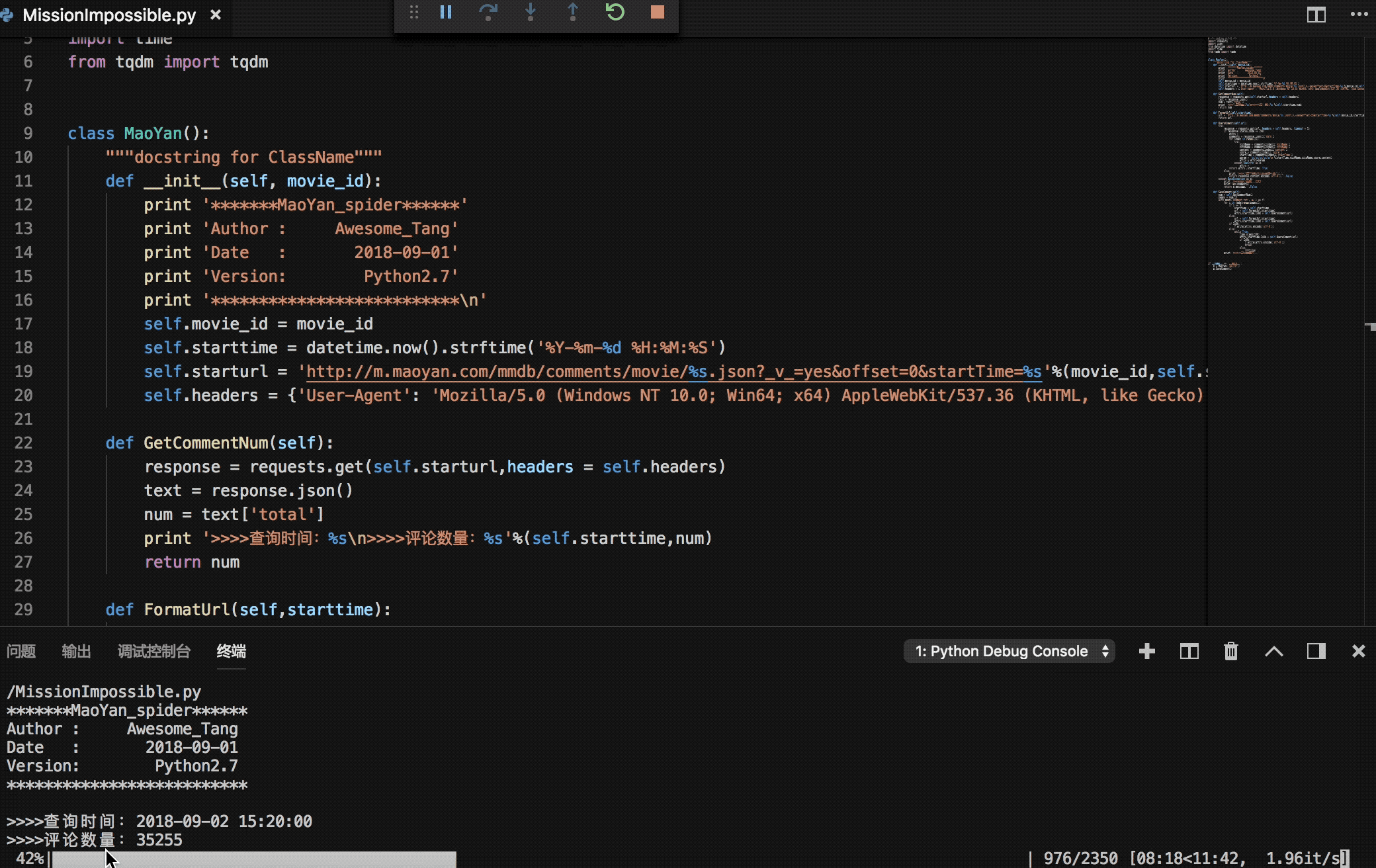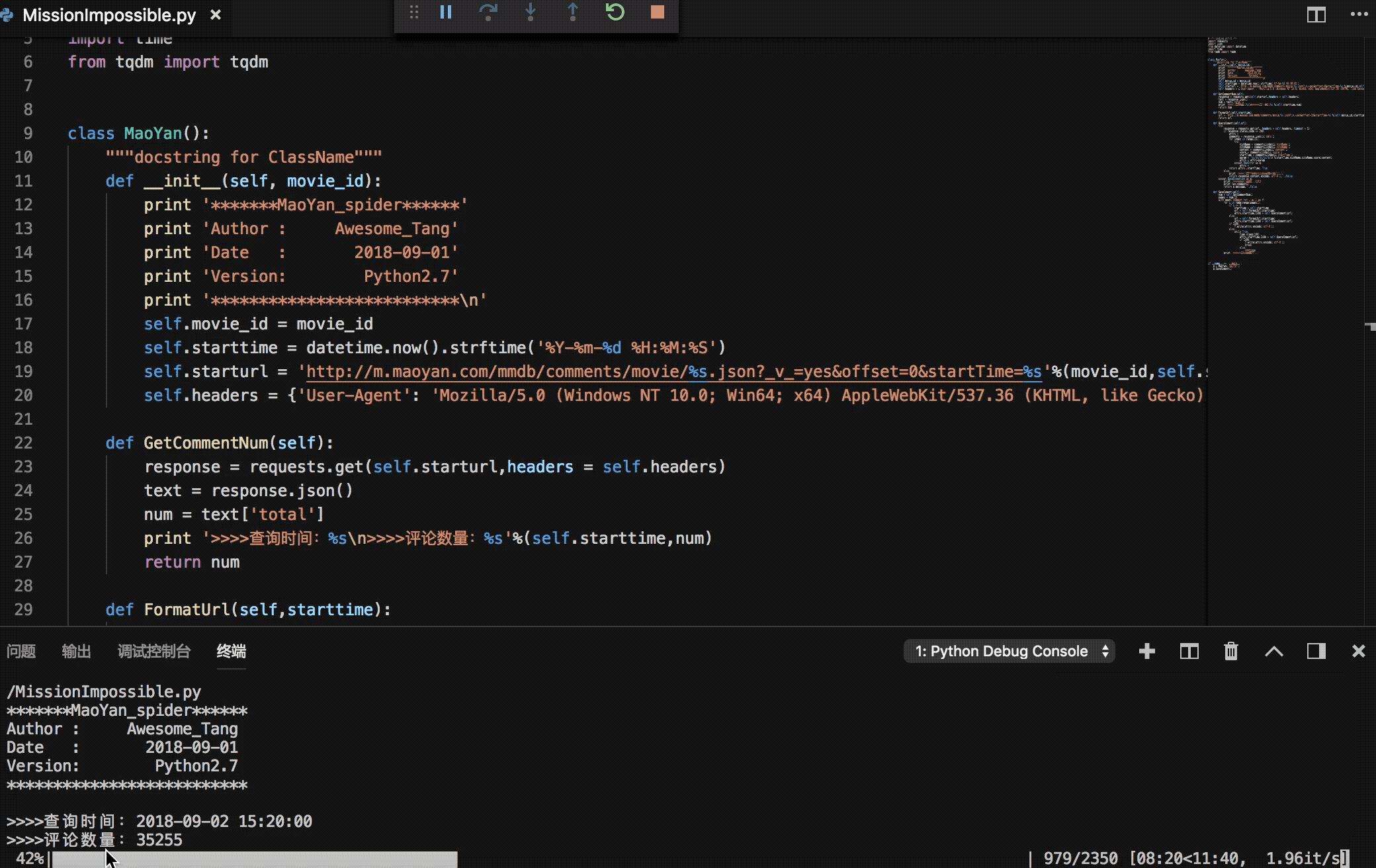
print '>>>>查询时间:%s\n>>>>评论数量:%s'%(self.starttime,num)
return num
def FormatUrl(self,starttime):
url = 'http://m.maoyan.com/mmdb/comments/movie/%s.json?_v_=yes&offset=15&startTime=%s'%(self.movie_id,starttime)
return url
def QueryComent(self,url):
'''
评论请求部分
nickName:用户昵称
cityName:城市
content:评论内容
score:用户评分
startTime:评论时间,每次取最早的时间传入下次请求
'''
time.sleep(random())
try:
response = requests.get(url, headers = self.headers, timeout = 5)
if response.status_code == 200:
attrs = ''
comments = response.json()['cmts']
for index in range(15):
try:
nickName = comments[index]['nickName']
cityName = comments[index]['cityName']
content = comments[index]['content']
score = comments[index]['score']
startTime = comments[index]['startTime']
param = '%s|%s|%s|%s|%s\n'%(startTime,nickName,cityName,score,content)
attrs = attrs+param
except KeyError as e:
attrs = ''
return attrs ,startTime, True
else:
print '>>>>查询过于频繁,请休息几分钟️️'
return response.content.encode('utf-8'),'',False
except BaseException as e:
print '>>>>请检查网络...'
print response.content.decode('utf-8')
return e.message,'',False
def SaveComent(self):
'''
保存评论到txt文件
如果请求成功保存,失败sleep100秒
tqdm用于实现进度条
'''
num = self.GetCommentNum()
pages = num/15
with open('comment.txt','a+') as f:
for i in tqdm(range(pages)):
if i == 0:
starttime = self.starttime
url = self.FormatUrl(starttime)
attrs,starttime,IsOk = self.QueryComent(url)
else:
url = self.FormatUrl(starttime)
attrs,starttime,IsOk = self.QueryComent(url)
if IsOk:
f.write(attrs.encode('utf-8'))
else:
while True:
time.sleep(100)
attrs,starttime,IsOk = self.QueryComent(url)
if IsOk:
f.write(attrs.encode('utf-8'))
break
else:
continue
print '>>>>评论保存完毕...'
if __name__ == '__main__':
p = MaoYan('341737')
p.SaveComent()
最后
评论算保存完了,近期会再做一个关于此次数据的可视化分析。另外阿汤哥真心太帅了,全程打肾上腺素,各位还没去看的赶紧~
skr~skr~~