思来想去,还是放弃用word记笔记的习惯吧,写了又不会回头看。
虚拟环境
每创建一个项目,就一定要给该项目创建一个虚拟环境。
虚拟环境用来隔离项目之间因为版本不同而产生的差异。
Flask服务器搭建步骤
1、从flask包里面导入Flask类
![]()
2、实例化Flask。
我们管falsk的实例化对象叫app。括号里面的__name__是flask实例化核心对象的一个标志。
![]()
实例化时传入参数“__name__”的原因是让我们实例化的这个对象与其他对象有所区分(揣测的意思,以后看了源码可能会改)
(课下了解:基于类的视图——即插视图)
3、视图函数实现的功能复用性不高,get一个新名词 “基于类的视图——即插视图” ,传送门(打马,以后仔细看看):
http://docs.jinkan.org/docs/flask/views.html
扩展知识:重定向
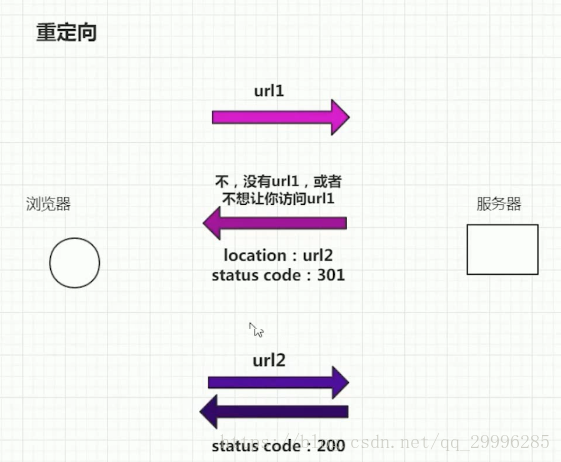
将@app.route(/hello“)改成@app.route(/hello/“)就可以兼容用户输入网址时,末尾带“/”之后无法访问网页的弊端。
浏览器申请访问url1,服务器并没有把url1的资源返回给浏览器,而是返回一个url2的location,并把状态码(status code:301或者302)设置成301或者302。浏览器获得返回值时,会先看一下状态码,如果状态码是301或者302,他就知道服务器希望他做一次重定向,他会再一次向服务器发送请求,这个请求就是url2。
![]()
Flask的实质是把末尾不带“/”的url重定向到“/”的url里面来。
重定向是为了保证每个资源都是唯一的url,否则不同的url可以访问相同的资源,会造成混乱
4、路由
在视图函数hello()中,用装饰器@app.route(‘/hello’) 来注册路由的原因是因为Python支持这样的一种装饰器。
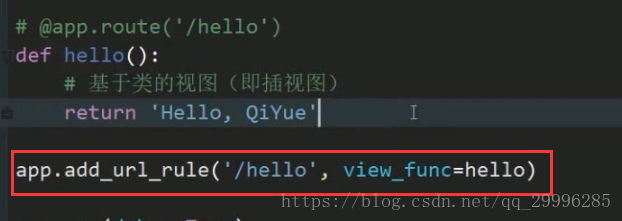
路由注册的另一种方法
![]()
如果你要使用基于类的视图(即插视图)的时候,你就要使用app.add_url_rule的方式来注册路由。
@app.route在底层的作用就是调用上面的add_url_rule,flask封装出装饰器,就是为了让界面看起来更优雅。
装饰器可以解决很多问题,尤其是代码耦合的问题(不明觉厉)。
![]()
如果只是写debug=True,那么你做的网页只能通过服务器所在的主机进行访问。
![]()
host=‘0.0.0.0’代表我可以接受外网的访问。
port=81代表端口号为81。
5、生产模式时,不能开启debug=True。原因有二:
首先调试模式(即开启debug=True)时的性能比较差;其次,我们不能向用户展示我们任何服务器的详细信息
6、部署的基本原则是开发模式和生产模式要保持镜像关系(也就是说两份源代码是一模一样的)。这个问题的解决办法就是写配置文件
建议:配置文件里面的参数全部大写
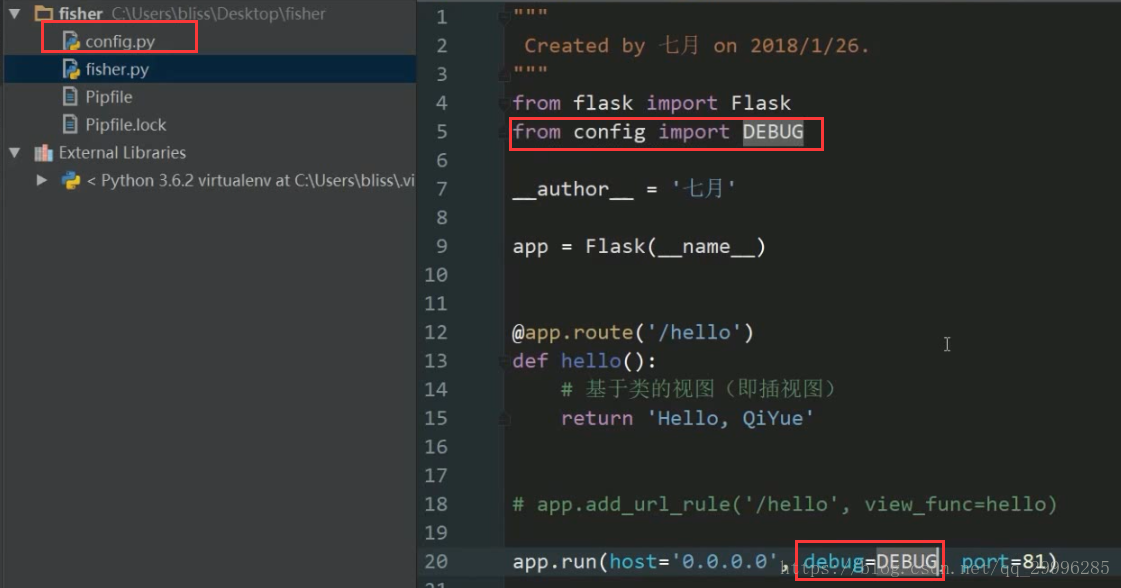
导入配置文件的方法一
导入我们写的配置文件(这里的语句是from config import DEBUG),导入之后,你就可以使用他了(把debug=True改成debug=DEBUG)
![]()
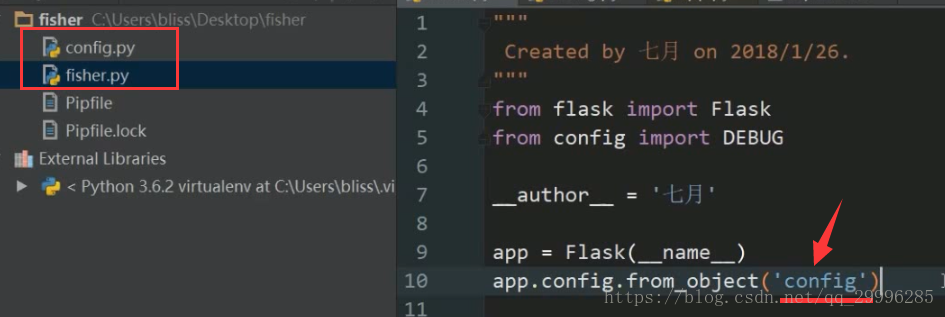
导入配置文件的方法二
由于config和Fisher在同一个文件夹里面,因此上面函数的路径就是‘config’
![]()
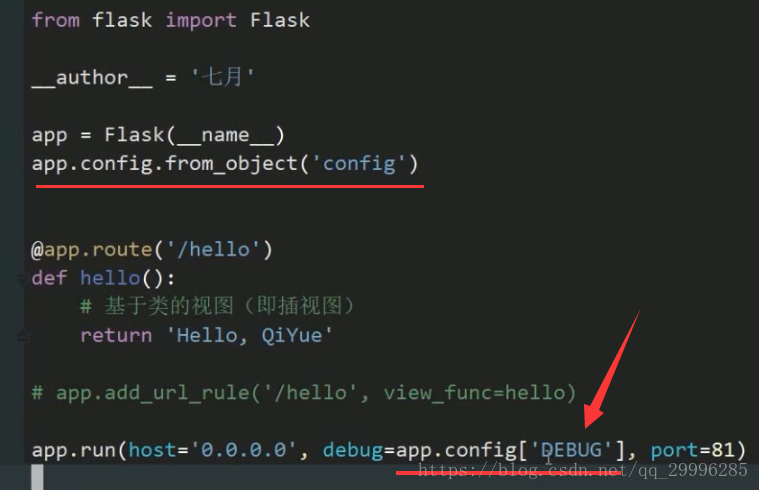
读取配置文件的方式
![]()
config其实是Python dict(字典)的一个子类
![]()
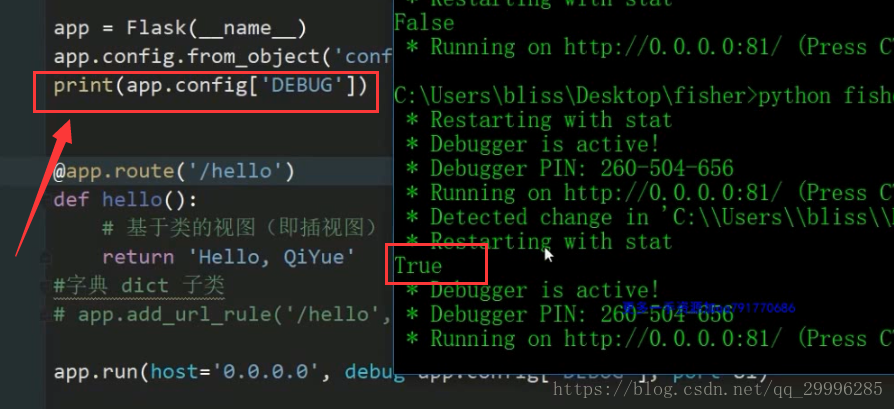
print函数可以在命令行里面输出东西,来查看我们的功能是否实现
注意:如果你是以“from_object”的形式(即:![]() )载入配置文件,flask要求变量的字母全部大写(因为小写字母会被自动忽略)。
)载入配置文件,flask要求变量的字母全部大写(因为小写字母会被自动忽略)。
补充:生产环境时,不使用flask自带的服务器,而是采用nginx+uwsgi(nginx作为前置服务器来接收浏览器发来的请求,之后请求会被转发给uwsgi);启动服务器不再是“Python ***.py”,而是由uwsgi加载模块,进而启动相关代码。在生产环境下,***就不再是入口文件了,他只是被uwsgi加载的模块文件,因此在生产环境下,app.run()是根本就不会被执行的。
加了![]() 之后,可以保证我们在生产环境下,不去启动flask自带的服务器(即:app.run())
之后,可以保证我们在生产环境下,不去启动flask自带的服务器(即:app.run())
补充:视图函数和普通函数不同,视图函数除了返回return信息之外,他会还会返回一系列的附加信息:
a、status code 200 404 301
b、content-type ——放置于http header的属性中,它的作用是告诉浏览器的接收方如何解析我们return的主体内容。(在flask的默认值为text/html )
7、response对象——flask会把你返回的东西作为响应的一个内容,同时会把主体内容和上面蓝字说的一些信息封装出一个对象,这个对象就叫做response对象。
创造response对象的流程:
首先导入make_response函数来创建对象![]()
然后在视图函数中作出相应的更改![]()
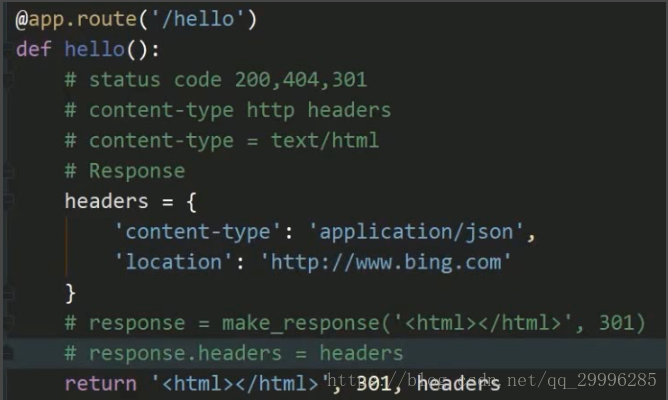
如此,返回页面会显示出文字<html></html>(因为response的content-type为text/plain)
补充:状态码只是一个标志,他并不会影响你要返回的一个内容,比如上面的视图函数会返回状态码404,但是网页依旧会有显示的内容。
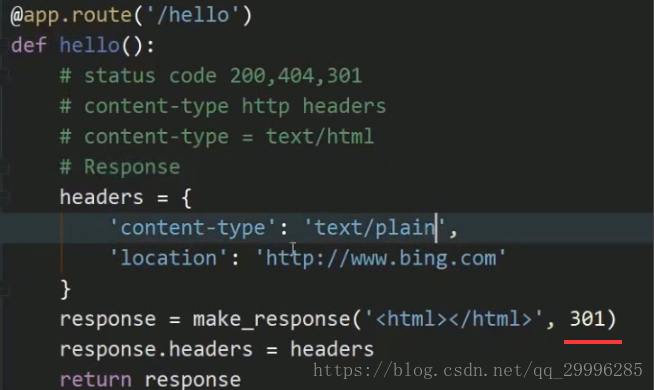
如果把response改成如图![]()
访问我们的主页时,就会直接重定向跳转到bing的首页。
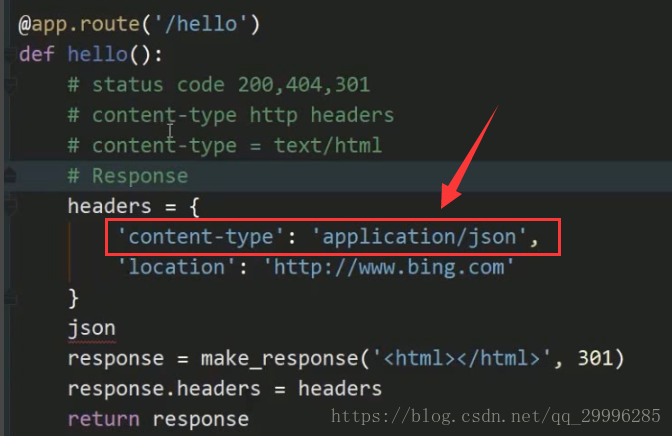
8、如何返回json格式的内容:
假如我们视图函数的接口是为我们的小程序或者移动端的app来提供数据的话,通常我们把他叫做api,而api的数据通常是json格式的,如何返回json格式的内容?——只要把response对象的content-type的值改成 “application/json” 即可。
![]()
response返回对象的简写方式:![]()
补充:如果你想在客户端生成cookie,就调用response的set_cookie方法就可以了。
数据与flask路由
搜索图书数据需要调用外部的api来获取图书检索数据
一、获取图书信息的两种方式:
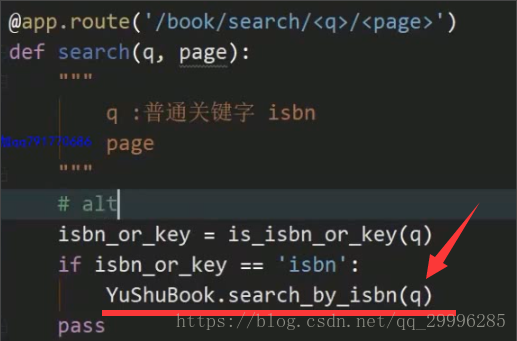
1、关键字搜索:![]()
2、isbn搜索:![]()
补充:api一定要设置访问频率的控制,否则很容易被人搞瘫痪。
补充:编写网站和编写api没有太大的区别,只要搞清楚网站返回的是什么,api返回的是什么即可。
二、传递参数的方式
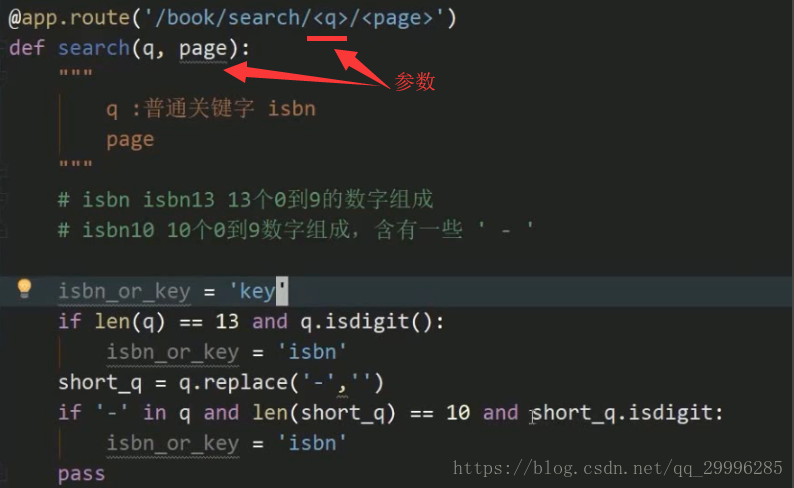
1、在url路径里传递参数
当中url里面加入了"<>",那么尖括号中的内容会被识别为是传入的参数,而不是固定的字符串
![]()
补充:Python里面的函数isdigit()可以自动识别参数是不是数字
用法: if q.isdigit():
编程知识——看源代码的方法:分层去看,首先理清代码的结构线索即可,了解各个函数的功能即可,无需依次查看函数的源码;当你需要看源码的时候再去看函数的源码即可。
2、在Python里面调用api
创建文件——http.py
将http请求封装在http模块里
在Python中,发送和http请求有两种方案
1、使用Python自带的urllib模块来发送http请求(比较难用)
2、用requests这样一个第三方的库来发送http请求(推荐)。
用requests这样一个第三方的库来发送http请求的方法:
首先需要安装requests包
补充:api的地址——url
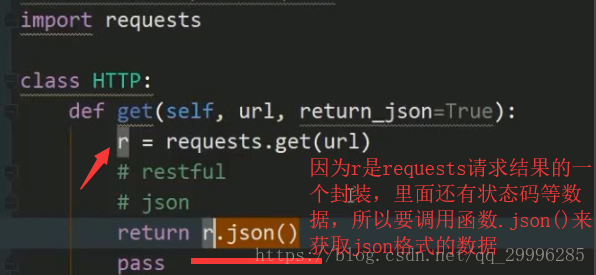
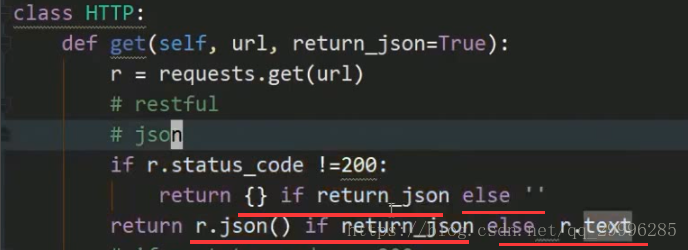
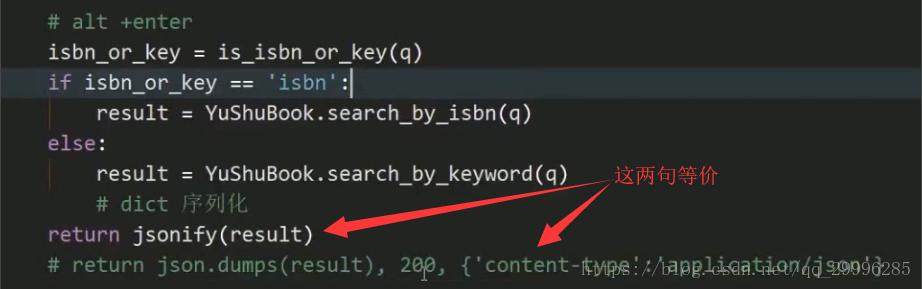
返回json格式的api的通用返回方法:
![]()
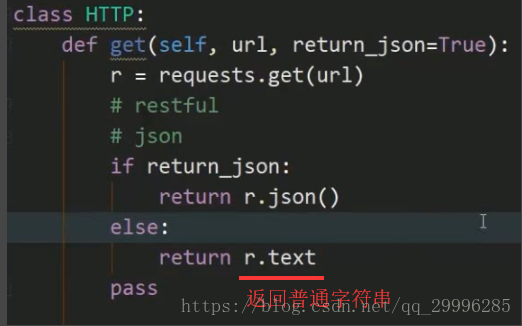
兼容返回json格式和字符串格式的api
![]()
简化if else 的方法
1、三元表达式:
![]()
2、巧妙的用if + return 来简化代码
3、把if和else里面的内容再提取成一个函数,然后再if和else里面调用我们的函数。
补充:Python爬虫可以用 scrapy(适合并发或者多线程的爬虫) 或者 requests+beautiful soap
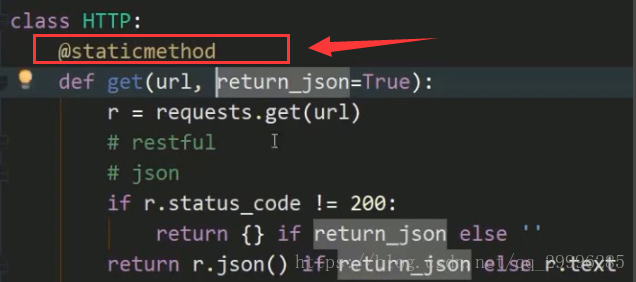
Python静态方法
1、@staticmethod
![]()
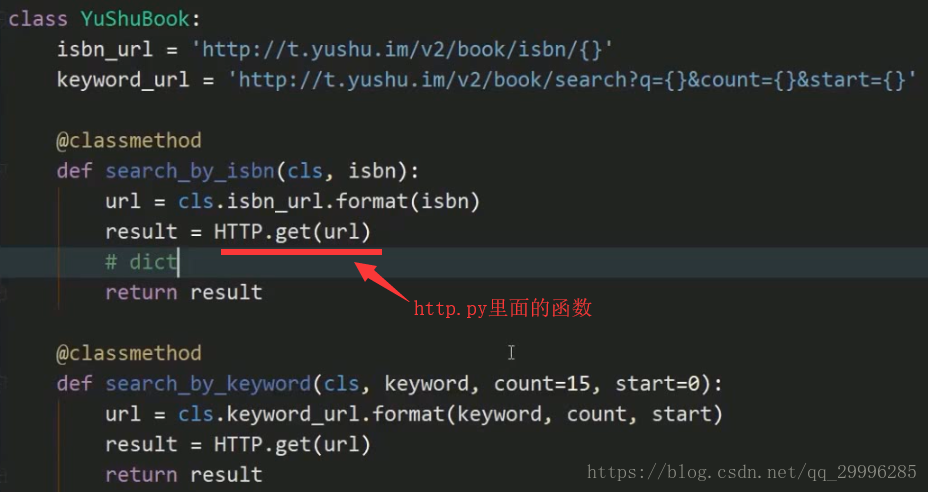
2、@classmethod——如果没有用到类里面相关的类变量时,没必要使用classmethod
补充:把方法封装到http对象里(如上图,函数被封装到class HTTP里),是为了以后便于扩展。
补充:在Python3里面class HTTP(object):和class HTTP:没有区别。在Python2里面,有经典类和新式类的区别。
三、从api获取数据
![]()
补充:json在Python里面会被准换成一个dict,也就是字典。
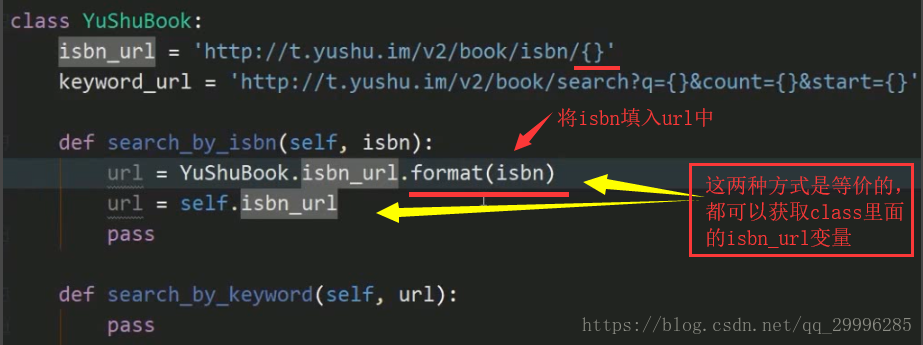
封装一个class,把获取的数据拼合出url,调用htp.py,获取json格式的返回值数据
![]()
在主函数中调用封装好的类,如此,实现输入一个关键词,返回json格式的数据
![]()
四、使用jsonify
jsonify是flask的一个功能,用之前要import一下
![]()
此时我们将json格式的数据返回到了客户端。
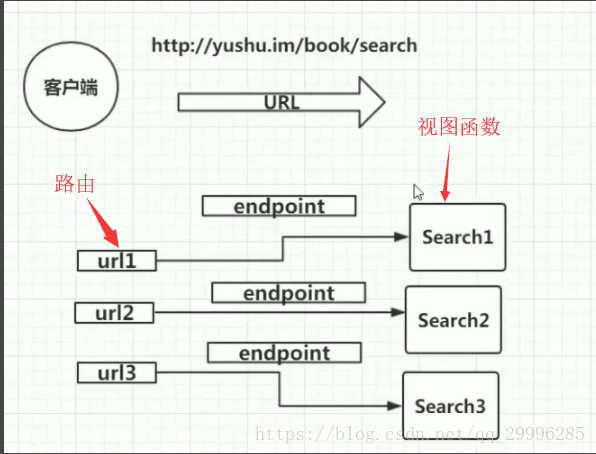
五 、深入了解flask路由
flask的路由机制图解
![]()
不传endpoint,视图函数依然可以被找到,这是因为flask里面,如果不传endpoint,会把视图函数的函数名作为endpoint的默认值。
补充:flask调试模式如果启动,他会把你的代码执行两次,会有一个restart的过程(这也就是debug的默认值为什么是false的缘故)
装饰器在底层会调用add_url_rule函数 ![]()
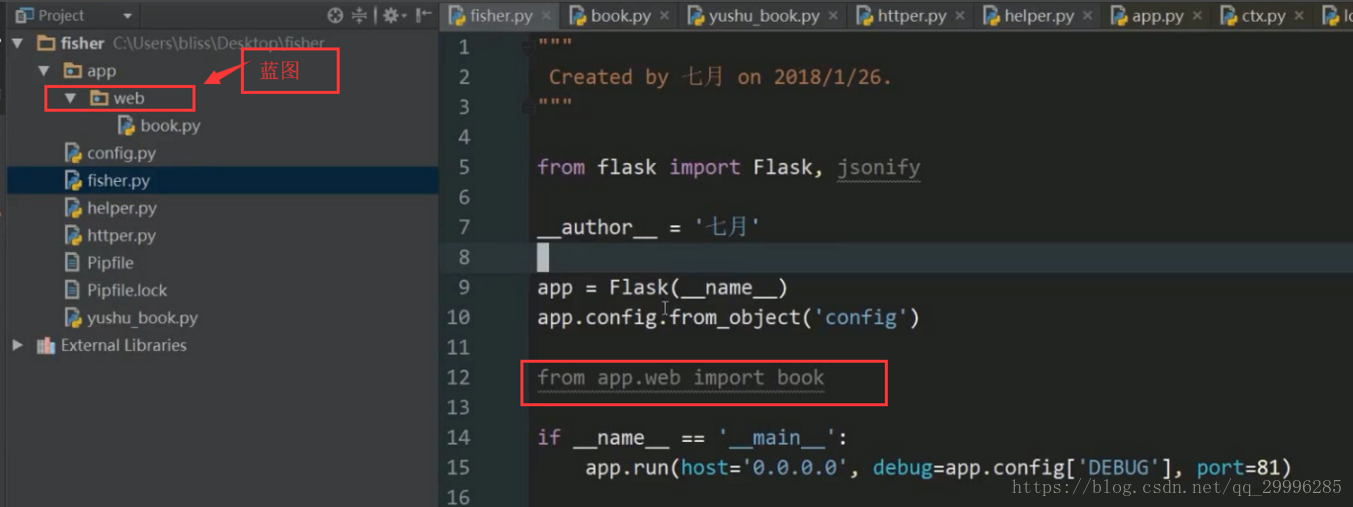
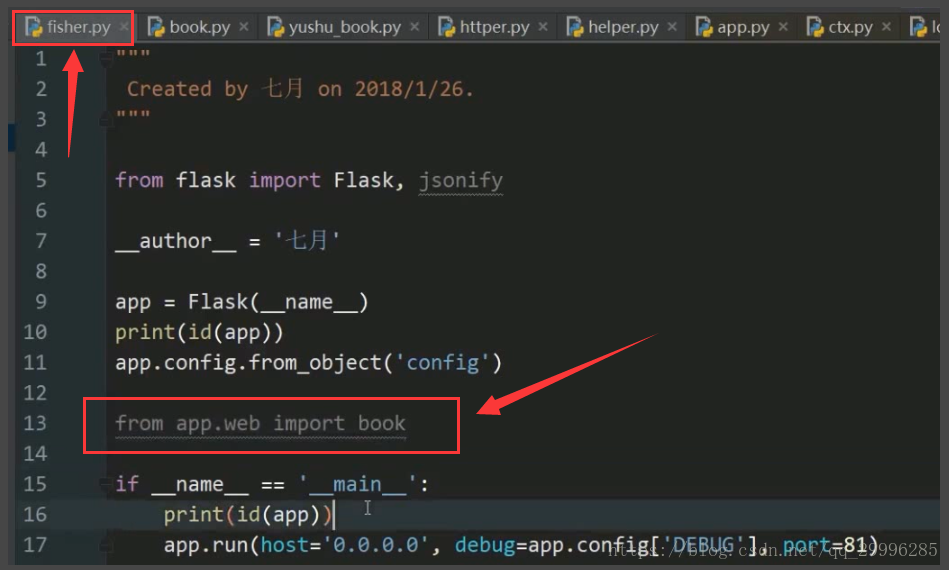
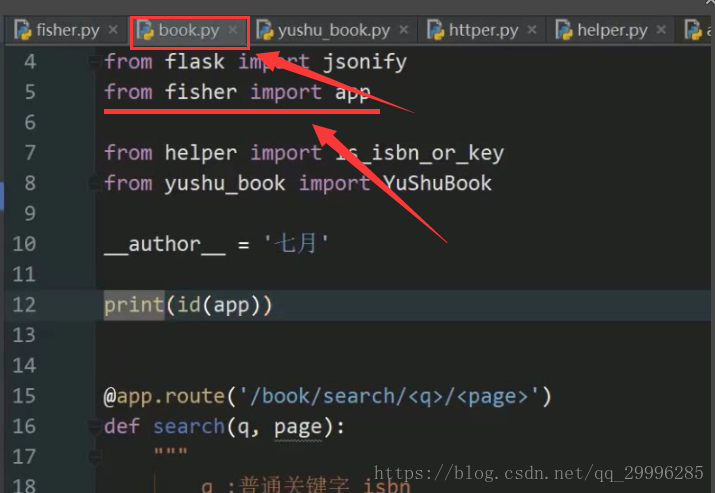
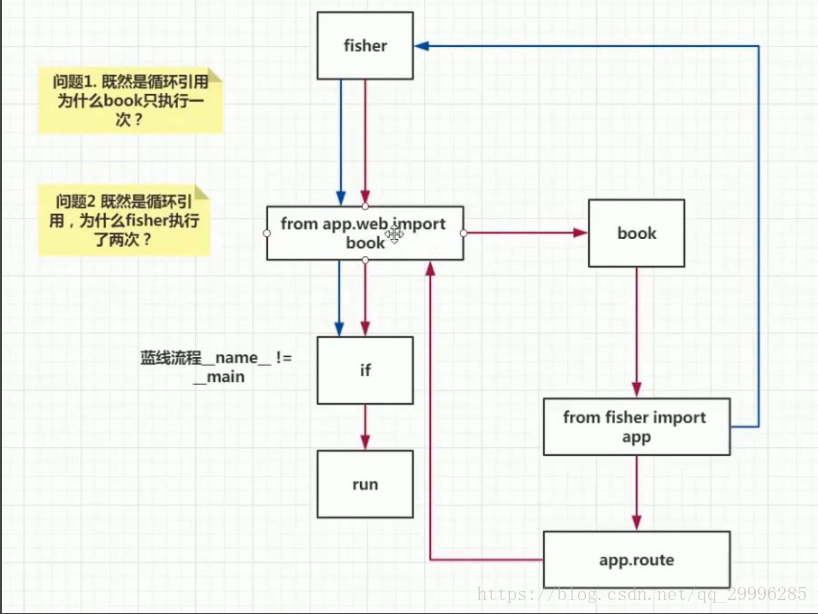
循环引入流程分析
下面两个代码互相import对方
![]()
![]()
book模块的导入用蓝线标示
![]()
由于第二次判断if语句的时候,name不等于main(因为这个模块是有book模块导入的),因此不会执行app.run()方法。
book模块会执行一次,为什么Fisher会执行两次?原因就是启动Fisher时,我们没有把Fisher当成模块导入,而是当作启动文件,因此他一共执行两次(启动时一次,导入时一次)。
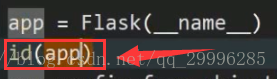
补充:查看对象地址的方法(比如,查看app核心对象的地址:![]() )
)
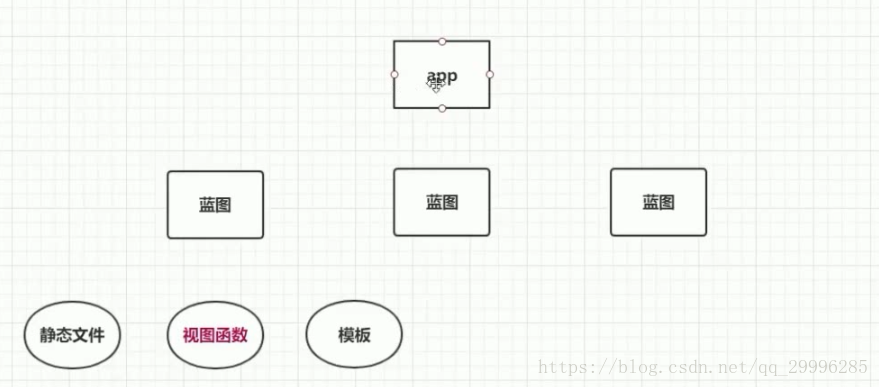
应用、蓝图与视图函数
蓝图
![]()
蓝图不能独立存在,他要插入到flask核心对象里。每一个蓝图又可以插入很多视图函数,蓝图还可以指定他自己的静态文件夹和模板文件夹。
思路——视图函数注册到蓝图里,蓝图注册到核心对象app里
![]()
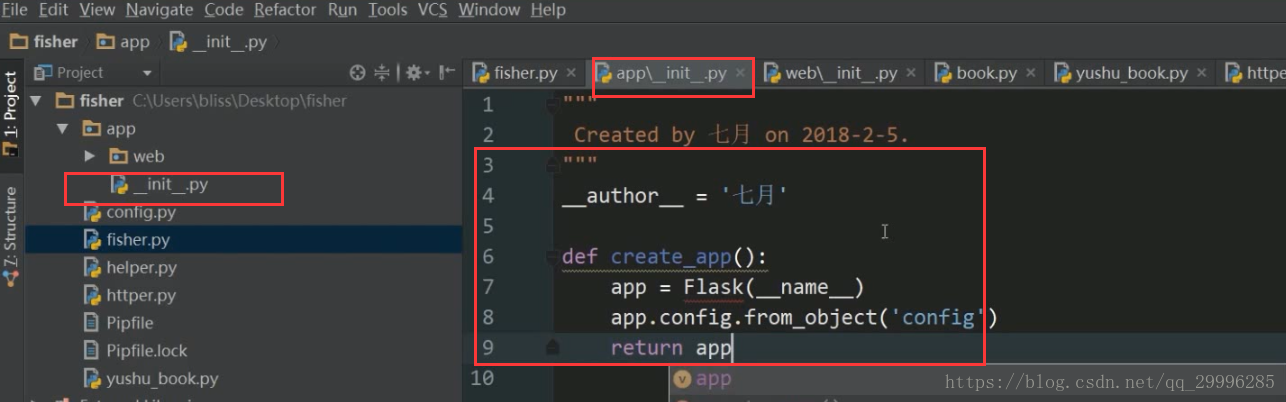
补充:让一个文件夹成为一个包的方法——在文件夹下面(不是里面)加一个_init_.py文件 ![]()
该文件用于核心对象的初始化工作。
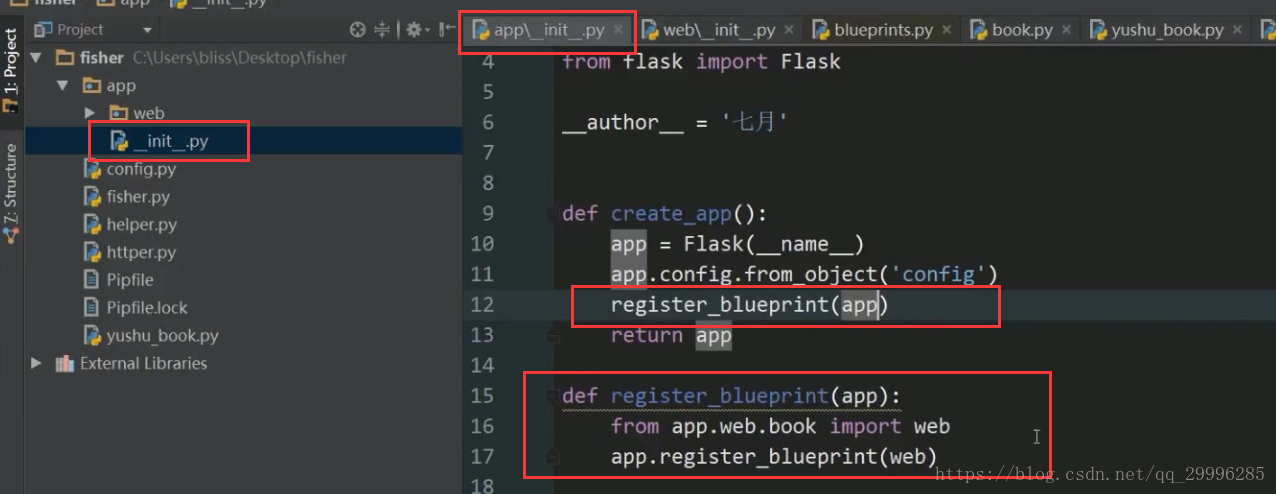
应用级别的初始化工作
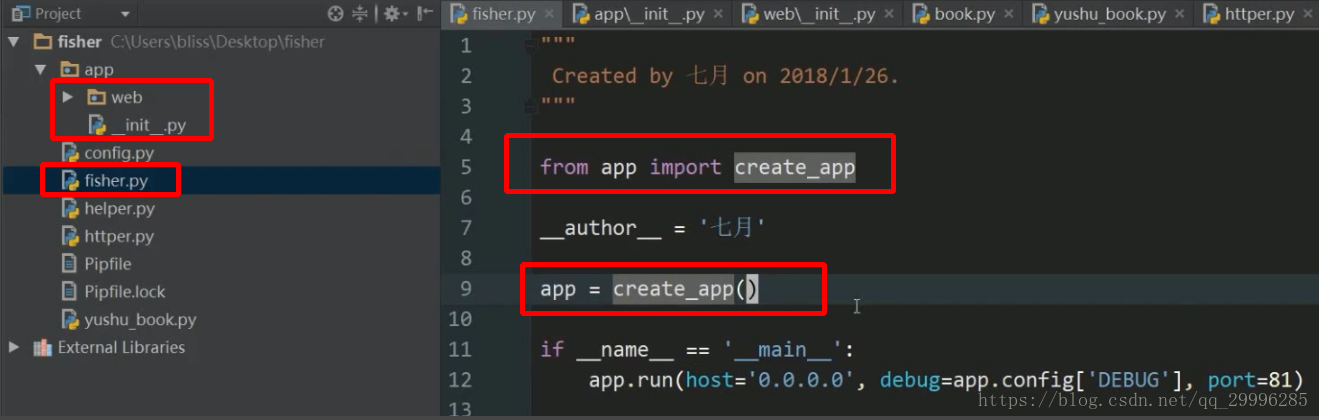
1、在_init_.py中初始化实例对象
![]()
2、在主执行程序里面调用函数来创建实例化对象:
![]()
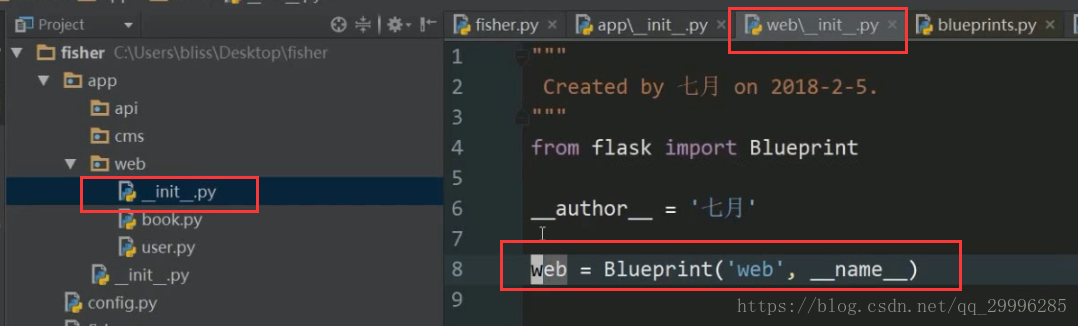
蓝图的基本用法
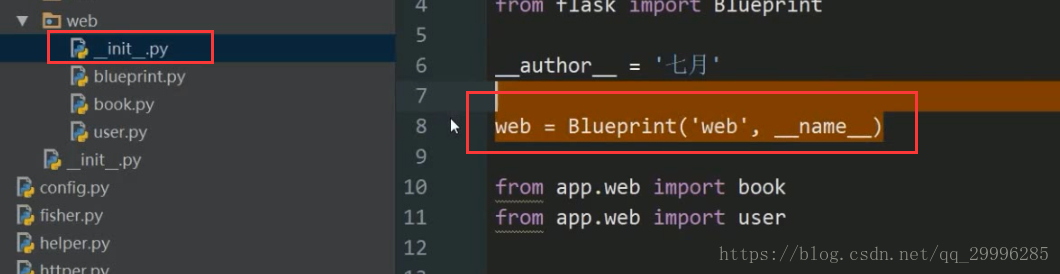
蓝图的初始化工作会放到蓝图文件夹里面的_init_.py中进行
![]()
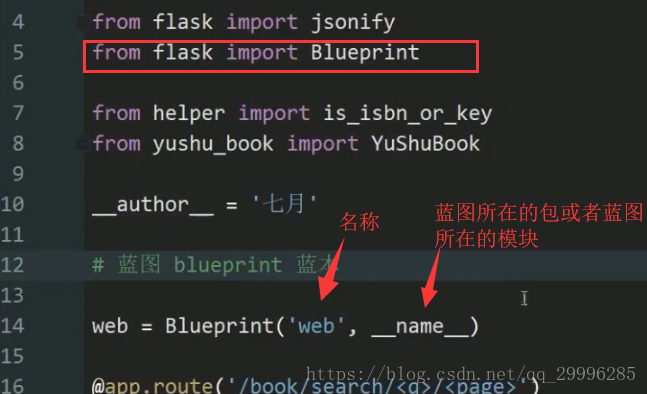
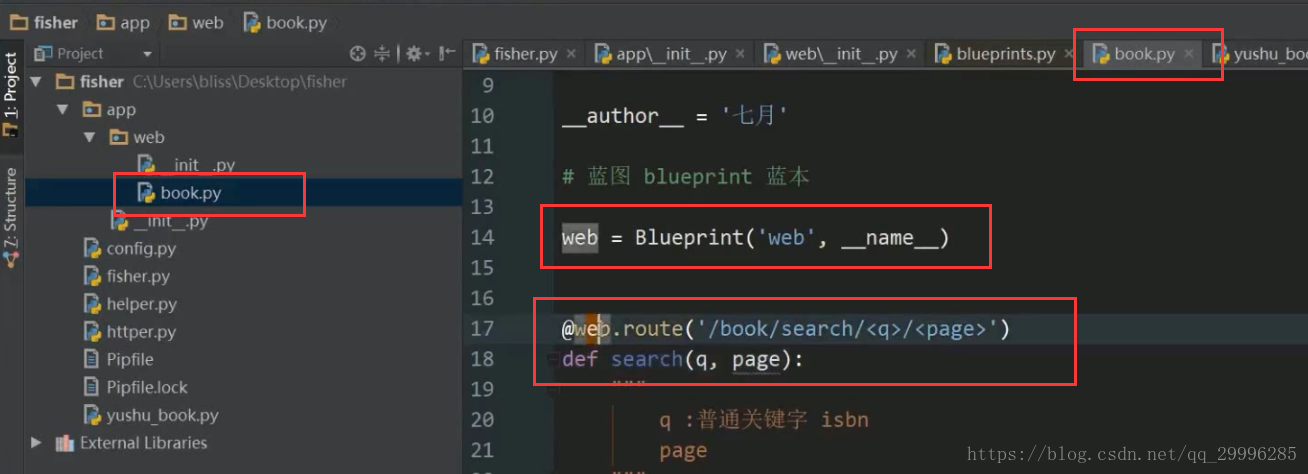
1、实例化蓝图对象(不再使用app来注册路由,我们使用蓝图来注册路由)
![]()
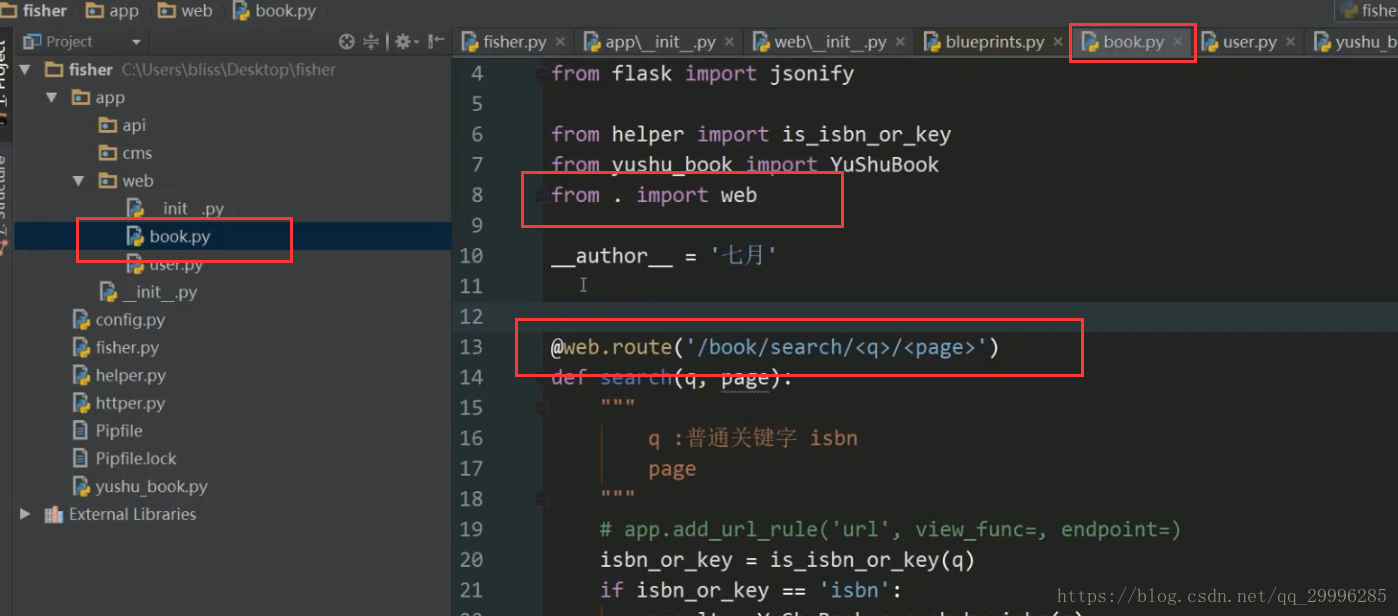
2、把视图函数注册到蓝图上
![]()
3、把蓝图注册到app里
![]()
蓝图的特性:蓝图不能替代视图函数核心对象,两个不是同一回事。
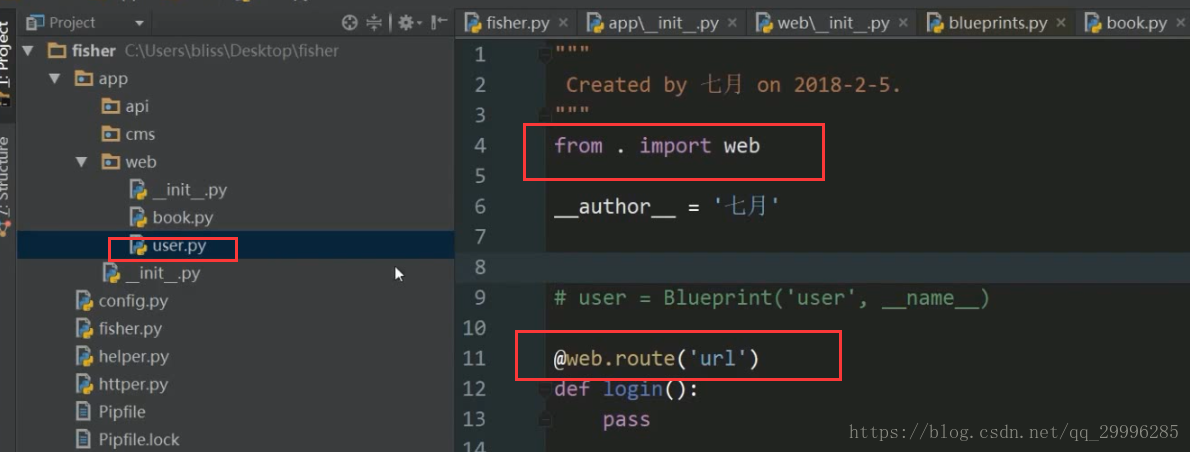
蓝图分模块管理——把不同的视图函数拆分到不同的文件
1、实例化蓝图
![]()
2、将蓝图导入并注册路由
![]()
![]()
3、将视图函数的模块导入执行
![]()
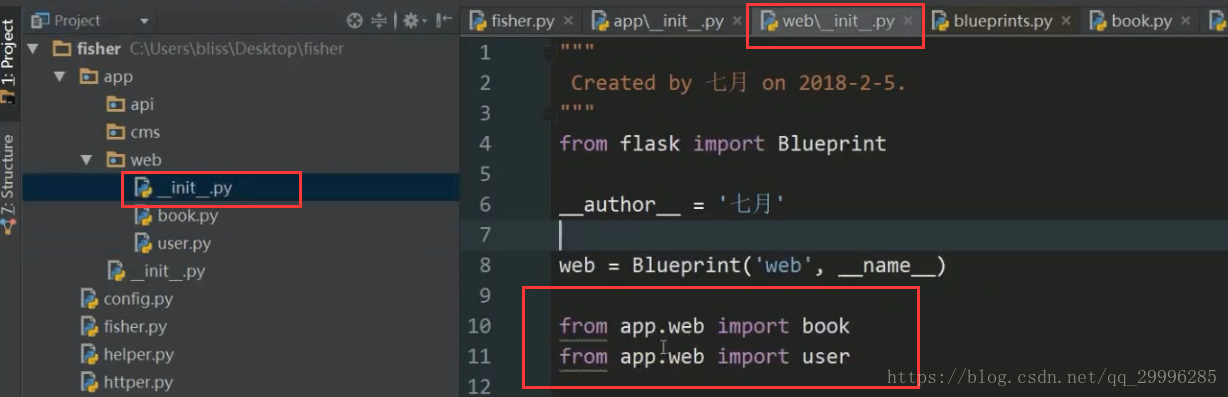
防止循环导入的方法:
1、把init.py里面的数理化导入到blueprint里面
![]()
![]()
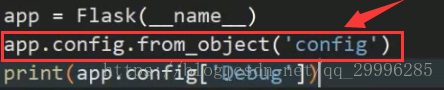 )载入配置文件,flask要求变量的字母全部大写(因为小写字母会被自动忽略)。
)载入配置文件,flask要求变量的字母全部大写(因为小写字母会被自动忽略)。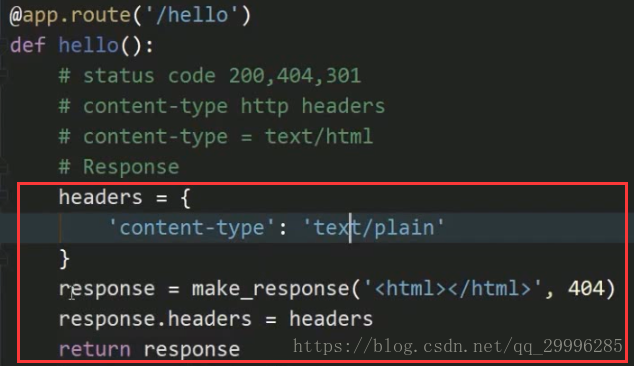
 )
)