



























20【在线日志分析】之记录一次Spark Streaming+Spark SQL的数据倾斜
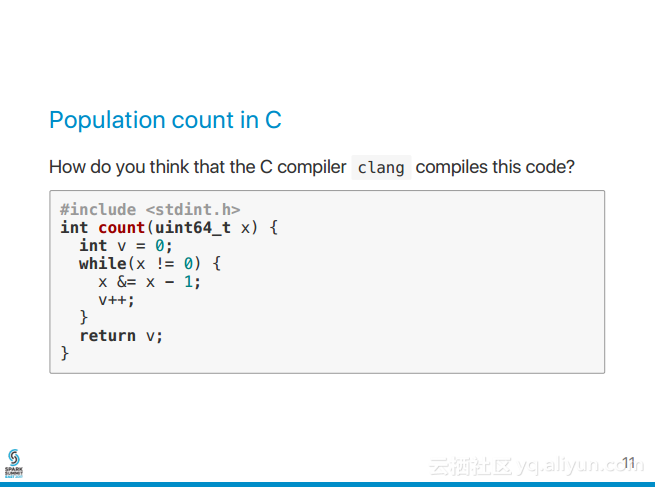
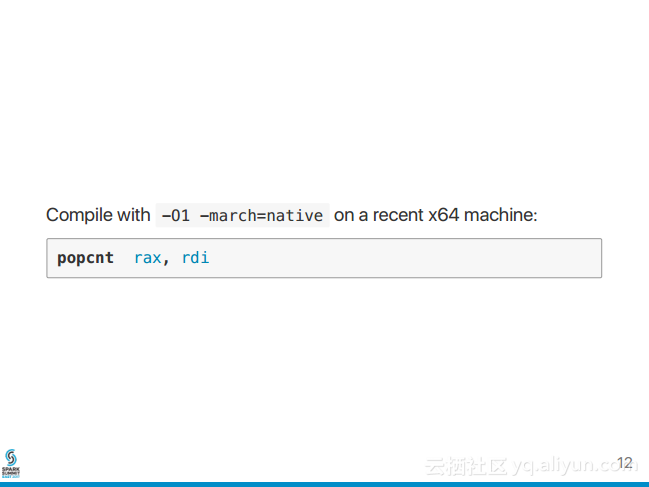
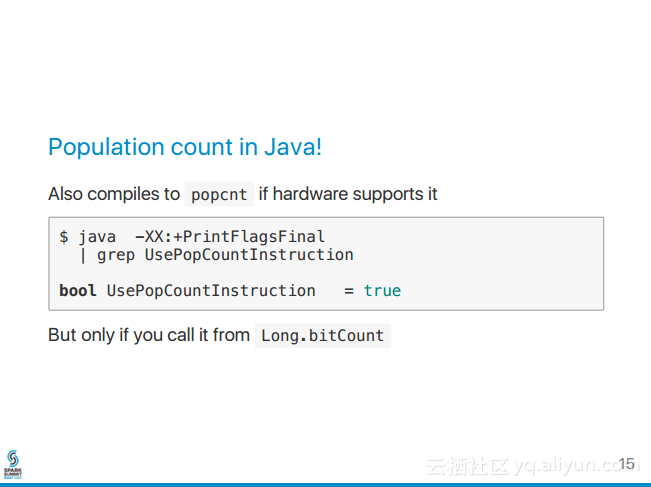
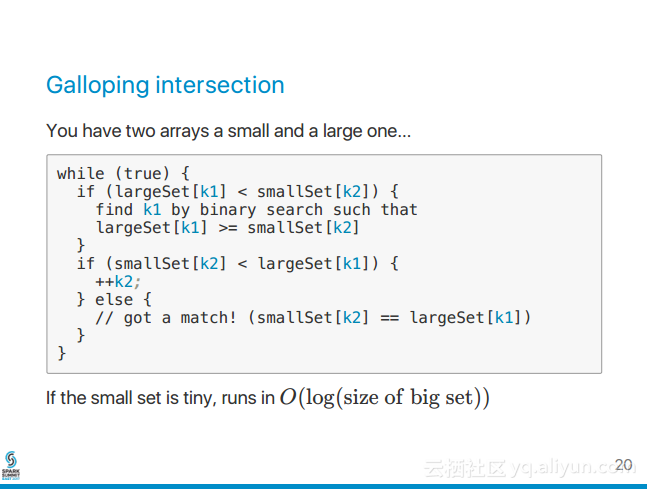
1.现象 三台机器都有产生executor,每台都会产生tasks,但是其中只有一台的task有input数据,其他机器的tasks都没有数据。 2.猜想 2.1是不是数据倾斜? 是 2.2是数据量过大,group by时,导致key分布不均? 比如key1 有98万,key2有2万,那么shuffle时,肯定数据倾斜。但是我刚开始数据量不是很大,所以pass (就算数据量大,也很简单处理,一般处理时key加上随机前缀数) 2.3是不是数据量太少 不够分区的? 也怀疑过,不过还没去验证 2.4 flume流到kafka,是snappy压缩格式,而spark作为kafka的消费者,虽然能够自动识别压缩格式,但是这种snappy格式不支持切分 也怀疑过,不过还没去修改支持spilt的压缩格式,也还没去验证 2.5 spark streaming分区数目是有谁决定的? 使用direct这种模式是由kafka的分区数目决定, 使用receiver这种模式由流的数目决定也就是由receiver数目决定。 3.修改分区数 [root@sht-sgmhadoopdn-02 kafka]#bin/ka...