概要:在使用storm分布式计算框架进行数据处理时,如何保证进入storm的消息的一定会被处理,且不会被重复处理。这个时候仅仅开启storm的ack机制并不能解决上述问题。那么该如何设计出一个好的方案来解决上述问题?
现有架构背景:本人所在项目组的实时系统负责为XXX的实时产生的交易记录进行处理,根据处理的结果向用户推送不同的信息。实时系统平时接入量每秒1000条,双十一的时候,最大几十万条。
架构设计:
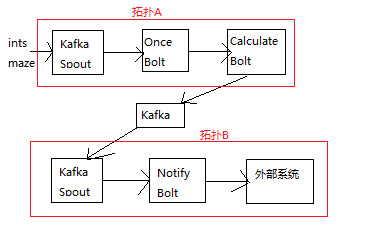
![]()
storm设置的超时时间为3分钟;kafkaspout的pending的长度为2000;storm开启ack机制,拓扑程序中如果出现异常则调用ack方法,向spout发出ack消息;每一个交易数据会有一个全局唯一性di。
处理流程:
交易数据会发送到kafka,然后拓扑A去kafka取数据进行处理,拓扑A中的OnceBolt会先对从kafka取出的消息进行一个唯一性过滤(根据该消息的全局id判断该消息是否存储在redis中,如果有,则说明拓扑A已经对该消息处理过了,则不会把该消息发送该下游的calculateBolt,直接向spout发送ack响应;如果没有,则把该消息发送该下游的calculateBolt。),calculateBolt对接收到来自上游的数据进行规则的匹配,根据该消息所符合的规则推送到不同的kafka通知主题中。
拓扑B则是不同的通知拓扑,去kafka读取对应通知的主题,然后把该消息推送到不同的客户端(微信客户端,支付宝客户端等)。
架构设计的意义:
通过借用redis,来保证消息不会被重复处理,对异常的消息,我们不让该消息重发。
因为系统只是对交易成功后的数据通过配置的规则进行区分来向用户推送不同的活动信息,从业务上看,系统并不需要保证所有交易的用户都一定要收到活动信息,只需要保证交易的用户不会收到重复的数据即可。
但是在线上运行半年后,还是发现了消息重复处理的问题,某些用户还是会收到两条甚至多条重复信息。
通过对现有架构的查看,我们发现问题出在拓扑B中(各个不同的通知拓扑),原因是拓扑B没有添加唯一性过滤bolt,虽然上游的拓扑对消息进行唯一性过滤了(保证了外部系统向kafka生产消息出现重复下,拓扑A不进行重复处理),但是回看拓扑B,我们可以知道消息重发绝对不是kafka主题中存在重复的两条消息,且拓扑B消息重复不是系统异常导致的(我们队异常进行ack应答),那么导致消息重复处理的原因就一定是消息超时导致的。ps:消息在storm中被处理,没有发生异常,而是由于集群硬件资源的争抢或者下游接口瓶颈无法快速处理拓扑B推送出去的消息,导致一条消息在3分钟内没有处理完,spout就认为该消息fail,而重新发该消息,但是超时的那一条消息并不是说不会处理,当他获得资源了,仍然会处理结束的。
解决方案:在拓扑B中添加唯一性过滤bolt即可解决。
个人推测:当时实时系统架构设计时,设计唯一性过滤bolt时,可能仅仅是考虑到外部系统向kafka推送数据可能会存在相同的消息,并没有想到storm本身tuple超时导致的消息重复处理。
该系统改进:虽然从业务的角度来说,并不需要保证每一个交易用户都一定要收到活动信息,但是我们完全可以做到每一个用户都收到活动信息,且收到的消息不重复。
我们可以做到对程序的异常进行控制,但是超时导致的fail我们无法控制。
我们对消息处理异常控制,当发生异常信息,我们在发送fail应答前,把该异常的消息存储到redis中,这样唯一性过滤的bolt就会对收到的每一条消息进行判断,如果在redis中,我们就知道该消息是异常导致的失败,就让该消息继续处理,如果该消息不在redis中,我们就知道该消息是超时导致的fail,那么我们就过滤掉该消息,不进行下一步处理。
这样我们就做到了消息的可靠处理且不会重复处理。
博主解决的是90%的问题,主要是因为:
1,彻头彻尾的异常是不会给你写redis的机会的,只能说绝大多数时候是OK的。
2,超时的任务最终也可能运行成功,这也会导致你做了2次。
我的看法:
既然是交易系统,最重要的就是业务本身满足幂等性和可重入,架构上容错导致的重试和重入,都不应该导致业务错乱。
所以,我认为在架构上能做的,是要保障at least once,博主判断redis不存在就认为是超时重发,殊不知超时的bolt可能很久之后异常退出,这样消息就没有人处理了。
不过具体场景具体分析,看业务需求取舍既可。
超时的任务最终也可能运行成功,这也会导致你做了2次。(ps:这个不会,我们认为超时的任务最终会处理成功,所以再次发送,我们会在唯一性过滤bolt中把该消息过滤掉)
超时的bolt可能很久之后异常退出,这样消息就没有人处理了(ps:这个我要研究下,就是超时后,再异常向spout发送fial响应是否还会重发消息,如果还会重发,那么就可以保证该异常消息可以再一次被处理)
彻头彻尾的异常是不会给你写redis的机会的,只能说绝大多数时候是OK的。(ps:正确,但是是不可控的吧,就像kafka把offset存储在zookeeper中,如果zookeeper挂掉就没有办法,确实绝大部分是ok
的,解决办法不知道有没有。)
最重要的就是业务本身满足幂等性和可重入,架构上容错导致的重试和重入,都不应该导致业务错乱(ps:我不是很明白,我这里并不要求一条消息具备事务的特性和幂等性有什么关系)
以上是我对该朋友对本系统架构找出的问题的个人思考。
老铁,你的--->推荐,--->关注,--->评论--->是我继续写作的动力。
微信公众号号:Apache技术研究院
由于博主能力有限,文中可能存在描述不正确,欢迎指正、补充!
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。