1. HDFS上的小文件问题
小文件是指文件大小明显小于HDFS上块(block)大小(默认64MB)的文件。如果存储小文件,必定会有大量这样的小文件,否则你也不会使用Hadoop(If you’re storing small files, then you probably have lots of them (otherwise you wouldn’t turn to Hadoop)),这样的文件给hadoop的扩展性和性能带来严重问题。当一个文件的大小小于HDFS的块大小(默认64MB),就将认定为小文件否则就是大文件。为了检测输入文件的大小,可以浏览Hadoop DFS 主页 http://machinename:50070/dfshealth.jsp ,并点击Browse filesystem(浏览文件系统)。
首先,在HDFS中,任何一个文件,目录或者block在NameNode节点的内存中均以一个对象表示(元数据)(Every file, directory and block in HDFS is represented as an object in the namenode’s memory),而这受到NameNode物理内存容量的限制。每个元数据对象约占150byte,所以如果有1千万个小文件,每个文件占用一个block,则NameNode大约需要2G空间。如果存储1亿个文件,则NameNode需要20G空间,这毫无疑问1亿个小文件是不可取的。
其次,处理小文件并非Hadoop的设计目标,HDFS的设计目标是流式访问大数据集(TB级别)。因而,在HDFS中存储大量小文件是很低效的。访问大量小文件经常会导致大量的寻找,以及不断的从一个DatanNde跳到另一个DataNode去检索小文件(Reading through small files normally causes lots of seeks and lots of hopping from datanode to datanode to retrieve each small file),这都不是一个很有效的访问模式,严重影响性能。
最后,处理大量小文件速度远远小于处理同等大小的大文件的速度。每一个小文件要占用一个slot,而task启动将耗费大量时间甚至大部分时间都耗费在启动task和释放task上。
2. MapReduce上的小文件问题
Map任务(task)一般一次处理一个块大小的输入(input)(默认使用FileInputFormat)。如果文件非常小,并且拥有大量的这种小文件,那么每一个map task都仅仅处理非常小的input数据,因此会产生大量的map tasks,每一个map task都会额外增加bookkeeping开销(each of which imposes extra bookkeeping overhead)。一个1GB的文件,拆分成16个块大小文件(默认block size为64M),相对于拆分成10000个100KB的小文件,后者每一个小文件启动一个map task,那么job的时间将会十倍甚至百倍慢于前者。
Hadoop中有一些特性可以用来减轻bookkeeping开销:可以在一个JVM中允许task JVM重用,以支持在一个JVM中运行多个map task,以此来减少JVM的启动开销(通过设置mapred.job.reuse.jvm.num.tasks属性,默认为1,-1表示无限制)。(译者注:如果有大量小文件,每个小文件都要启动一个map task,则必相应的启动JVM,这提供的一个解决方案就是重用task 的JVM,以此减少JVM启动开销);另 一种方法是使用MultiFileInputSplit,它可以使得一个map中能够处理多个split。
3. 为什么会产生大量的小文件
至少有两种场景下会产生大量的小文件:
(1)这些小文件都是一个大逻辑文件的一部分。由于HDFS在2.x版本开始支持对文件的append,所以在此之前保存无边界文件(例如,log文件)(译者注:持续产生的文件,例如日志每天都会生成)一种常用的方式就是将这些数据以块的形式写入HDFS中(a very common pattern for saving unbounded files (e.g. log files) is to write them in chunks into HDFS)。
(2)文件本身就是很小。设想一下,我们有一个很大的图片语料库,每一个图片都是一个独一的文件,并且没有一种很好的方法来将这些文件合并为一个大的文件。
4. 解决方案
这两种情况需要有不同的解决方 式。
4.1 第一种情况
对于第一种情况,文件是许多记录(Records)组成的,那么可以通过调用HDFS的sync()方法(和append方法结合使用),每隔一定时间生成一个大文件。或者,可以通过写一个程序来来合并这些小文件(可以看一下Nathan Marz关于Consolidator一种小工具的文章)。
4.2 第二种情况
对于第二种情况,就需要某种形式的容器通过某种方式来对这些文件进行分组。Hadoop提供了一些选择:
4.2.1 HAR File
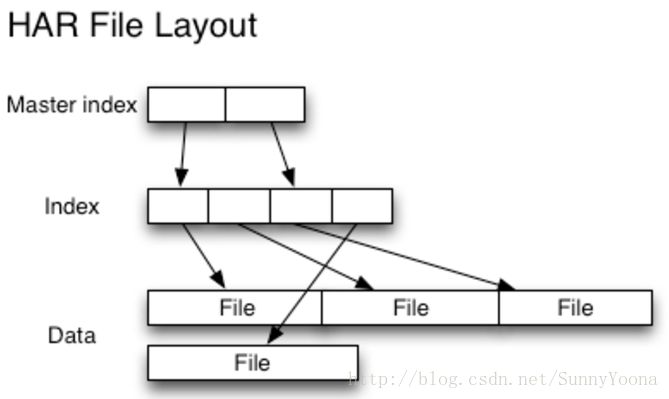
Hadoop Archives (HAR files)是在0.18.0版本中引入到HDFS中的,它的出现就是为了缓解大量小文件消耗NameNode内存的问题。HAR文件是通过在HDFS上构建一个分层文件系统来工作。HAR文件通过hadoop archive命令来创建,而这个命令实 际上是运行了一个MapReduce作业来将小文件打包成少量的HDFS文件(译者注:将小文件进行合并几个大文件)。对于client端来说,使用HAR文件没有任何的改变:所有的原始文件都可见以及可访问(只是使用har://URL,而不是hdfs://URL),但是在HDFS中中文件数却减少了。
读取HAR中的文件不如读取HDFS中的文件更有效,并且实际上可能较慢,因为每个HAR文件访问需要读取两个索引文件以及还要读取数据文件本身(如下图)。尽管HAR文件可以用作MapReduce的输入,但是没有特殊的魔法允许MapReduce直接操作HAR在HDFS块上的所有文件(although HAR files can be used as input to MapReduce, there is no special magic that allows maps to operate over all the files in the HAR co-resident on a HDFS block)。 可以考虑通过创建一种input format,充分利用HAR文件的局部性优势,但是目前还没有这种input format。需要注意的是:MultiFileInputSplit,即使在HADOOP-4565(https://issues.apache.org/jira/browse/HADOOP-4565)的改进,但始终还是需要每个小文件的寻找。我们非常有兴趣看到这个与SequenceFile进行对比。 在目前看来,HARs可能最好仅用于存储文档(At the current time HARs are probably best used purely for archival purposes.)。
![image]()
4.2.2 SequenceFile
通常对于"小文件问题"的回应会是:使用序列文件(SequenceFile)。这种方法的思路是,使用文件名(filename)作为key,并且文件内容(file contents)作为value,如下图。在实践中这种方式非常有效。我们回到10,000个100KB小文件问题上,你可以编写一个程序将它们放入一个单一的SequenceFile,然后你可以流式处理它们(直接处理或使用MapReduce)操作SequenceFile。这样同时会带来两个优势:(1)SequenceFiles是可拆分的,因此MapReduce可以将它们分成块并独立地对每个块进行操作;(2)它们同时支持压缩,不像HAR。 在大多数情况下,块压缩是最好的选择,因为它将压缩几个记录为一个块,而不是一个记录压缩一个块。(Block compression is the best option in most cases, since it compresses blocks of several records (rather than per record))。
![image]()
将现有数据转换为SequenceFile可能很慢。 但是,完全可以并行创建SequenceFile的集合。(It can be slow to convert existing data into Sequence Files. However, it is perfectly possible to create a collection of Sequence Files in parallel.)Stuart Sierra写了一篇关于将tar文件转换为SequenceFile的文章(https://stuartsierra.com/2008/04/24/a-million-little-files ),像这样的工具是非常有用的,我们应该多看看。展望未来,最好设计数据管道,将源数据直接写入SequenceFile(如果可能),而不是作为中间步骤写入小文件。
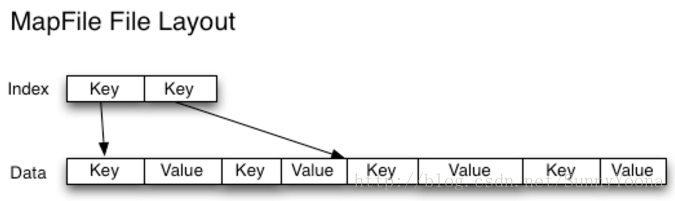
与HAR文件不同,没有办法列出SequenceFile中的所有键,所以不能读取整个文件。Map File,就像对键进行排序的SequenceFile,只维护了部分索引,所以他们也不能列出所有的键,如下图。
![image]()
SequenceFile是以Java为中心的。 TFile(https://issues.apache.org/jira/browse/HADOOP-4565 )设计为跨平台,并且可以替代SequenceFile,不过现在还不可用。
4.2.3 HBase
如果你生产很多小文件,那么根据访问模式,不同类型的存储可能更合适(If you are producing lots of small files, then, depending on the access pattern, a different type of storage might be more appropriate)。HBase以Map Files(带索引的SequenceFile)方式存储数据,如果您需要随机访问来执行MapReduce式流式分析,这是一个不错的选择( HBase stores data in MapFiles (indexed SequenceFiles), and is a good choice if you need to do MapReduce style streaming analyses with the occasional random look up)。如果延迟是一个问题,那么还有很多其他选择 - 参见Richard Jones对键值存储的调查(http://www.metabrew.com/article/anti-rdbms-a-list-of-distributed-key-value-stores/)。
原文:http://blog.cloudera.com/blog/2009/02/the-small-files-problem/