


Spark之SQL解析(源码阅读十)
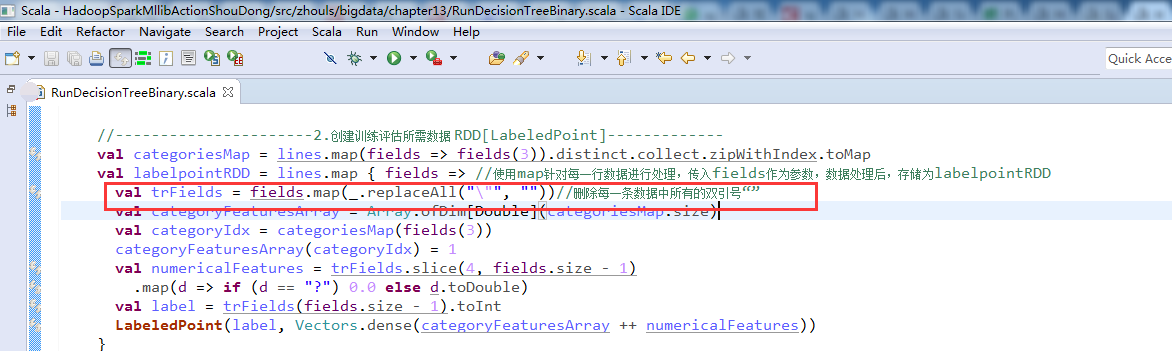
如何能更好的运用与监控sparkSQL?或许我们改更深层次的了解它深层次的原理是什么。之前总结的已经写了传统数据库与Spark的sql解析之间的差别。那么我们下来直切主题~ 如今的Spark已经支持多种多样的数据源的查询与加载,兼容了Hive,可用JDBC的方式或者ODBC来连接Spark SQL。下图为官网给出的架构.那么sparkSql呢可以重用Hive本身提供的元数据仓库(MetaStore)、HiveQL、以及用户自定义函数(UDF)及序列化和反序列化的工具(SerDes). 下来我们来细化SparkContext,大的流程是这样的: 1、SQL语句经过SqlParser解析成Unresolved LogicalPlan; 2、使用analyzer结合数据字典(catalog)进行绑定,生成Resolved LogicalPlan; 3、使用optimizer对Resolved LogicalPlan进行优化,生成Optimized LogicalPlan; 4、使用SparkPlan将LogicalPlan转换成PhysiclPlan; 5、使用prepareForExcep...