如何能更好的运用与监控sparkSQL?或许我们改更深层次的了解它深层次的原理是什么。之前总结的已经写了传统数据库与Spark的sql解析之间的差别。那么我们下来直切主题~
如今的Spark已经支持多种多样的数据源的查询与加载,兼容了Hive,可用JDBC的方式或者ODBC来连接Spark SQL。下图为官网给出的架构.那么sparkSql呢可以重用Hive本身提供的元数据仓库(MetaStore)、HiveQL、以及用户自定义函数(UDF)及序列化和反序列化的工具(SerDes).
![]()
下来我们来细化SparkContext,大的流程是这样的:
1、SQL语句经过SqlParser解析成Unresolved LogicalPlan;
2、使用analyzer结合数据字典(catalog)进行绑定,生成Resolved LogicalPlan;
3、使用optimizer对Resolved LogicalPlan进行优化,生成Optimized LogicalPlan;
4、使用SparkPlan将LogicalPlan转换成PhysiclPlan;
5、使用prepareForException将PhysicalPlan转换成可执行物理计划。
6、使用execute()执行可执行物理计划,生成DataFrame.
这些解析的过程,我们都可以通过监控页面观察的到。
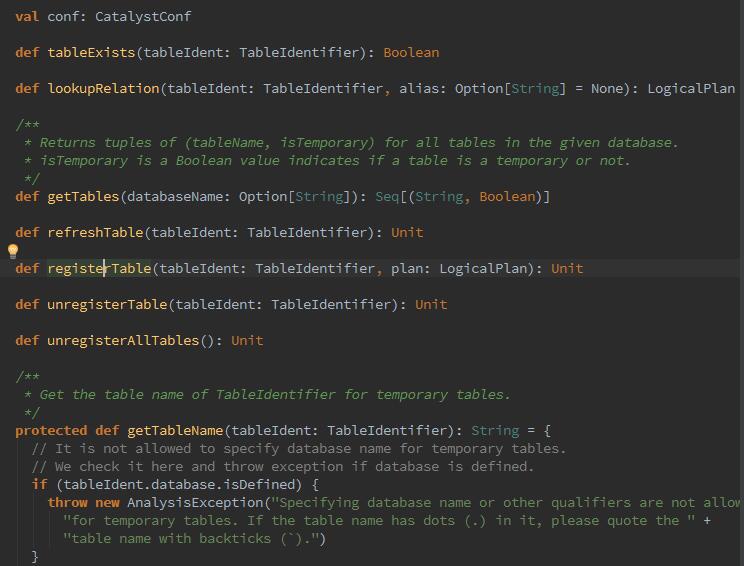
下来我们先从第一个Catalog开始,什么是Catalog?它是一个字典表,用于注册表,对标缓存后便于查询,源码如下:
![]()
这个类呢,是个特质,定义了一些tableExistes:判断表是否存在啊,registerTable:注册表啊、unregisterAllTables:清除所有已经注册的表啊等等。在创建时,new的是SimpleCatalog实现类,这个类实现了Catalog中的所有接口,将表名和logicalPlan一起放入table缓存,曾经的版本中呢,使用的是mutable.HashMap[String,LogicalPlan]。现在声明的是ConcurrentHashMap[String,LogicalPlan]
![]()
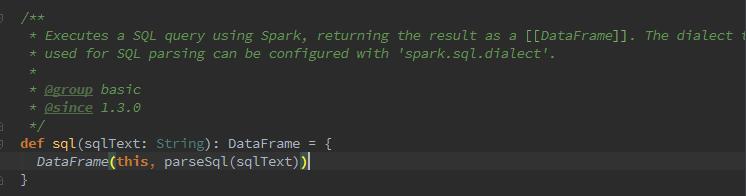
然后呢,我们来看一下词法解析器Parser的实现。在原先的版本中,调用sql方法,返回的是SchemaRDD,现在的返回类型为DataFrame:
![]()
你会发现,调用了parseSql,在解析完后返回的是一个物理计划。
![]()
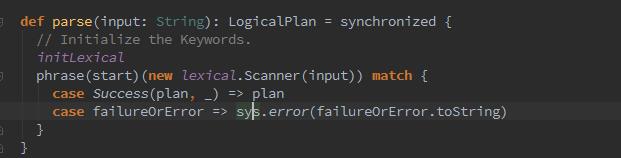
我们再深入parse方法,发现这里隐式调用了apply方法:
![]()
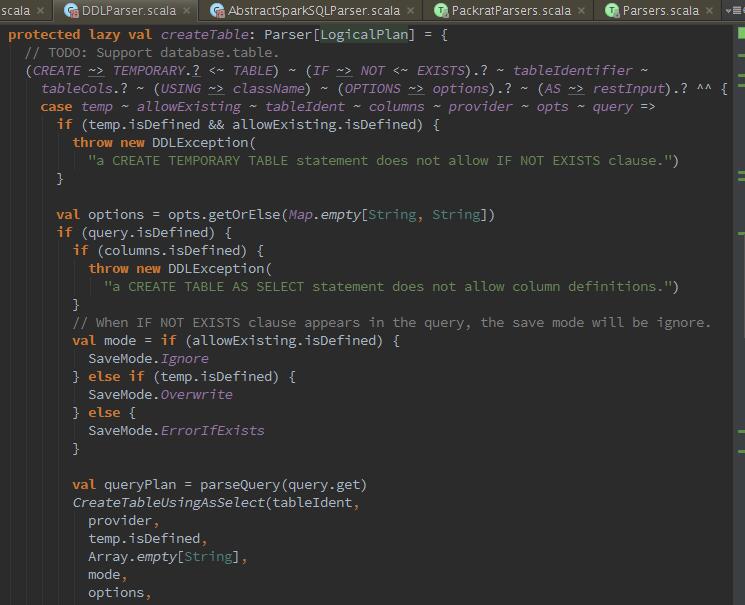
下来我们看一下,它的建表语句解析,你会发现其实它是解析了物理计划,然后模式匹配来创建表:
![]()
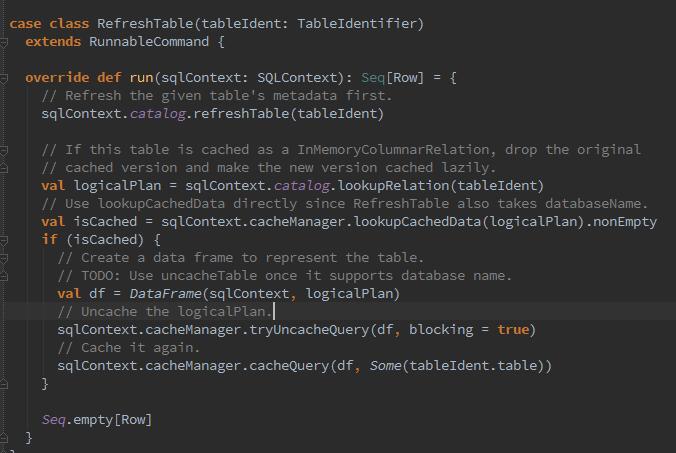
最后调用了RefreshTable中的run方法:
![]()
那么创建完表了,下来开始痛苦的sql解析。。。上传说中的操作符函数与解析的所有sql函数!
![]()
![]()
一望拉不到底。。。这个Keyword其实是对sql语句进行了解析:
![]()
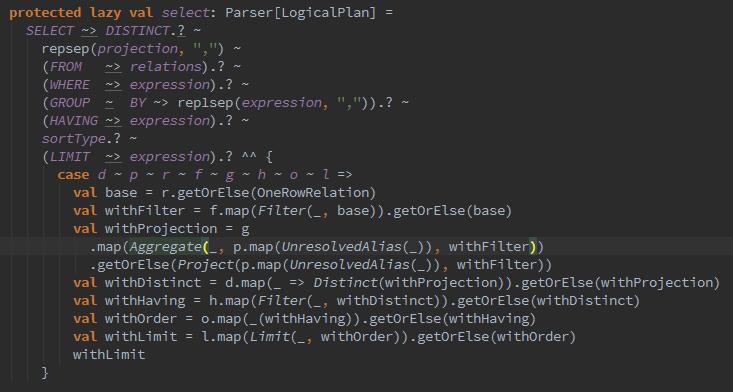
然后拿一个select的sql语法解析为例,本质就是将sql语句的条件进行了匹配,过滤筛选:
![]()
一个select的步骤包括,获取DISTINCT语句、投影字段projection、表relations、where后的表达式、group by后的表达式,hiving后的表达式、排序字段ordering、Limit后的表达式。随之就进行匹配封装操作RDD,Filter、Aggregate、Project、Distinct、sort、Limit,最终形成一颗LogicalPlan的Tree.
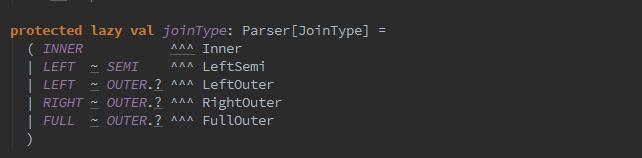
那么join操作,也包含了左外连接、全外连接、笛卡尔积等。
![]()
好的,既然sql的执行计划解析完了,下来该对解析后的执行计划进行优化,刚才的解析过程将sql解析为了一个Unresolved LogicalPlan的一棵树。下来Analyzer和optimizer将会对LogicalPlan的这棵树加入各种分析和优化操作,比如列剪枝啊 谓词下压啊。
Analyzer将Unresolved LogicalPlan与数据字典(catalog)进行绑定,生成resolved LogicalPlan.然后呢Optimizer对Resolved LogicalPlan进行优化,生成Optimized LogicalPlan.
![]()
这里的useCachedData方法实际是用于将LogicalPlan的树段替换为缓存中的。具体过滤优化看不懂啊TAT 算了。。第一遍源码,讲究先全通一下吧。
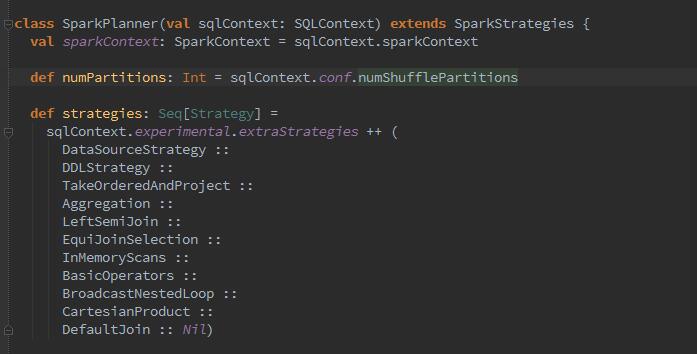
下来,一系列的解析啊、分析啊、优化啊操作过后,因为生成的逻辑执行计划无法被当做一般的job来处理,所以为了能够将逻辑执行计划按照其他job一样对待,需要将逻辑执行计划变为物理执行计划。
![]()
如下图,你注意哦,配置文件中shufflePartition的个数就是从这里传进来的。
![]()
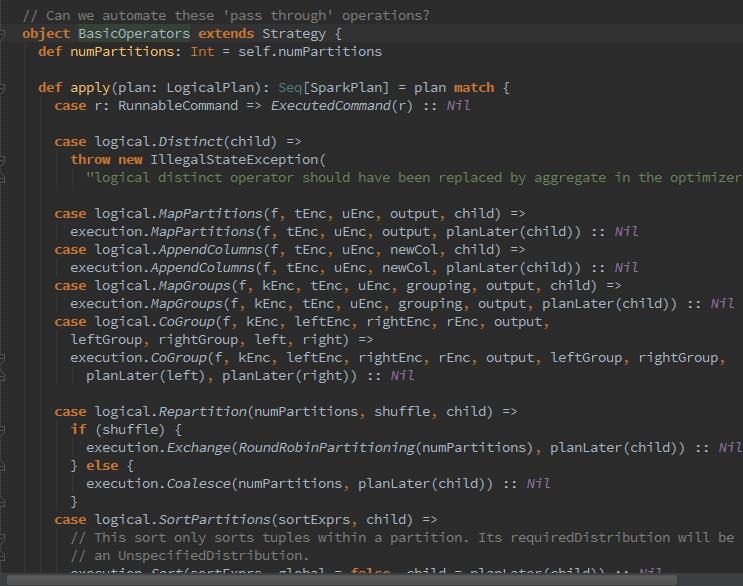
这里面真正牛逼变态的是BasicOperators。它对最常用的SQL关键字都做了处理,每个处理的分支,都会调用planLater方法,planLater方法给child节点的LogicalPlan应用sparkPlanner,于是就差形成了迭代处理的过程。最终实现将整颗LogicalPlan树使用SparkPlanner来完成转换。最终执行物理计划。
![]()
参考文献:《深入理解Spark:核心思想与源码分析》