在上一章中提到了编码压缩,讲了一个简单的DataBlockEncoding.PREFIX算法,它用的是前序编码压缩的算法,它搜索到时候,是全扫描的方式搜索的,如此一来,搜索效率实在是不敢恭维,所以在hbase当中单独拿了一个工程出来实现了Trie的数据结果,既达到了压缩编码的效果,亦达到了方便查询的效果,一举两得,设置的方法是在上一章的末尾提了。
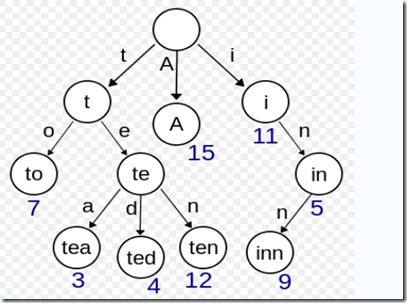
下面讲一下这个Trie树的原理吧。
![214e47591317c2e48f2042ad89fafb6ff1f53e6d]()
树里面有3中类型的数据结构,branch(分支)、leaf(叶子)、nub(节点)
1、branch 分支节点,比如图中的t,以它为结果的词并没有出现过,但它是to、tea等次的分支的地方,单个t的词没有出现过。
2、leaf叶子节点,比如图中的to,它下面没有子节点了,并且出现了7次。
3、nub节点,它是结余两者之间的,比如i,它独立出现了11次。
下面我们就具体说一下在hbase的工程里面它是什么样子的,下面是一个例子:
* Example inputs (numInputs=7):
* 0: AAA
* 1: AAA
* 2: AAB
* 3: AAB
* 4: AAB
* 5: AABQQ
* 6: AABQQ
* <br/><br/>
* Resulting TokenizerNodes:
* AA <- branch, numOccurrences=0, tokenStartOffset=0, token.length=2
* A <- leaf, numOccurrences=2, tokenStartOffset=2, token.length=1
* B <- nub, numOccurrences=3, tokenStartOffset=2, token.length=1
* QQ <- leaf, numOccurrences=2, tokenStartOffset=3, token.length=2
这里面3个辅助字段,numOccurrences(出现次数)、tokenStartOffset(在原词当中的位置)、token.length(词的长度)。
描述这个数据结构用了两个类Tokenizer和TokenizerNode。
好,我们先看一下发起点PrefixTreeCodec,这个类是继承自DataBlockEncoder接口的,DataBlockEncoder是专门负责编码压缩的,它里面的有3个重要的方法,encodeKeyValues(编码)、decodeKeyValues(反编码)、createSeeker(创建扫描器)。
因此我们先看PrefixTreeCodec里面的encodeKeyValues方法,这个是我们的入口,我们发现internalEncodeKeyValues是实际编码的地方。
private void internalEncodeKeyValues(DataOutputStream encodedOutputStream,
ByteBuffer rawKeyValues, boolean includesMvccVersion) throws IOException {
rawKeyValues.rewind();
PrefixTreeEncoder builder = EncoderFactory.checkOut(encodedOutputStream, includesMvccVersion);
try{
KeyValue kv;
while ((kv = KeyValueUtil.nextShallowCopy(rawKeyValues, includesMvccVersion)) != null) {
builder.write(kv);
}
builder.flush();
}finally{
EncoderFactory.checkIn(builder);
}
}
可以看到从rawKeyValues里面不断读取kv出来,用PrefixTreeEncoder.write方法来进行编码,最后调用flush进行输出。
我们现在就进入PrefixTreeEncoder.write的方法里面吧。
rowTokenizer.addSorted(CellUtil.fillRowRange(cell, rowRange));
addFamilyPart(cell);
addQualifierPart(cell);
addAfterRowFamilyQualifier(cell);
这里就跳到Tokenizer.addSorted方法里面。
public void addSorted(final ByteRange bytes) {
++numArraysAdded;
//先检查最大长度,如果它是最大,改变最大长度
if (bytes.getLength() > maxElementLength) {
maxElementLength = bytes.getLength();
}
if (root == null) {
// 根节点
root = addNode(null, 1, 0, bytes, 0);
} else {
root.addSorted(bytes);
}
}
如果root节点为空,就new一个root节点出来,有了根节点之后,就把节点添加到root节点的孩子队列里面。
下面贴一下addSorted的代码吧。
public void addSorted(final ByteRange bytes) {// recursively build the tree
/*
* 前缀完全匹配,子节点也不为空,取出最后一个节点,和最后一个节点也部分匹配
* 就添加到最后一个节点的子节点当中
*/
if (matchesToken(bytes) && CollectionUtils.notEmpty(children)) {
TokenizerNode lastChild = CollectionUtils.getLast(children);
//和最后一个节点前缀部分匹配
if (lastChild.partiallyMatchesToken(bytes)) {
lastChild.addSorted(bytes);
return;
}
}
//匹配长度
int numIdenticalTokenBytes = numIdenticalBytes(bytes);// should be <= token.length
//当前token的起始长度是不变的了,剩余的尾巴的其实位置
int tailOffset = tokenStartOffset + numIdenticalTokenBytes;
//尾巴的长度
int tailLength = bytes.getLength() - tailOffset;
if (numIdenticalTokenBytes == token.getLength()) {
//和该节点完全匹配
if (tailLength == 0) {// identical to this node (case 1)
incrementNumOccurrences(1);
} else {
// 加到节点的下面,作为孩子
int childNodeDepth = nodeDepth + 1;
int childTokenStartOffset = tokenStartOffset + numIdenticalTokenBytes;
TokenizerNode newChildNode = builder.addNode(this, childNodeDepth, childTokenStartOffset, bytes, tailOffset);
addChild(newChildNode);
}
} else {
split(numIdenticalTokenBytes, bytes);
}
}
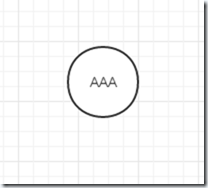
1、我们先添加一个AAA进去,它是根节点,parent是null,深度为1,在原词中起始位置为0。
![f848aff0d1ddaad46aa2b83e974e0a401605c8b6]()
2、添加一个AAA,它首先和之前的AAA相比,完全一致,走的是incrementNumOccurrences(1),出现次数(numOccurrences)变成2。
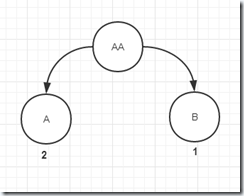
3、添加AAB,它和AAA相比,匹配的长度为2,尾巴长度为1,那么它走的是这条路split(numIdenticalTokenBytes, bytes)这条路径。
protected void split(int numTokenBytesToRetain, final ByteRange bytes) {
int childNodeDepth = nodeDepth;
int childTokenStartOffset = tokenStartOffset + numTokenBytesToRetain;
//create leaf AA 先创建左边的节点
TokenizerNode firstChild = builder.addNode(this, childNodeDepth, childTokenStartOffset,
token, numTokenBytesToRetain);
firstChild.setNumOccurrences(numOccurrences);// do before clearing this node's numOccurrences
//这一步很重要,更改原节点的长度,node节点记录的数据不是一个简单的byte[]
token.setLength(numTokenBytesToRetain);//shorten current token from BAA to B
numOccurrences = 0;//current node is now a branch
moveChildrenToDifferentParent(firstChild);//point the new leaf (AA) to the new branch (B)
addChild(firstChild);//add the new leaf (AA) to the branch's (B's) children
//create leaf 再创建右边的节点
TokenizerNode secondChild = builder.addNode(this, childNodeDepth, childTokenStartOffset,
bytes, tokenStartOffset + numTokenBytesToRetain);
addChild(secondChild);//add the new leaf (00) to the branch's (B's) children
// 递归增加左右子树的深度
firstChild.incrementNodeDepthRecursively();
secondChild.incrementNodeDepthRecursively();
}
split完成的效果:
![d2fe842fd4604aab2c92249c18dc2352580daaea]()
1) 子节点的tokenStartOffset 等于父节点的tokenStartOffset 加上匹配的长度,这里是0+2=2
2)创建左孩子,token为A,深度为父节点一致,出现次数和父亲一样2次
3)父节点的token长度变为匹配长度2,即(AA),出现次数置为0
4)把原来节点的子节点指向左孩子
5)把左孩子的父节点指向当前节点
6)创建右孩子,token为B,深度为父节点一致
7)把右孩子的父节点指向当前节点
8)把左右孩子的深度递归增加。
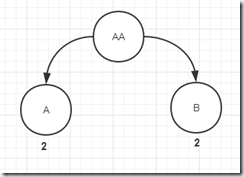
4、 添加AAB,和AA完全匹配,最后一个孩子节点AAB也匹配,调用AAB节点的addSorted(bytes),因为是完全匹配,所以和第二步一样,B的出现次数加1
![7d42e5589dcda95f45e52d4a38bec52503e6c77d]()
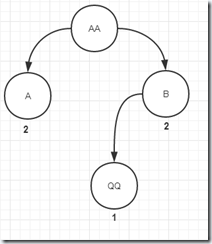
5、添加AABQQ,和AA完全匹配,最后一个孩子节点AAB也匹配,调用AAB节点的addSorted(bytes), 成为AAB的孩子
先走的这段代码,走进递归:
if (matchesToken(bytes) && CollectionUtils.notEmpty(children)) {
TokenizerNode lastChild = CollectionUtils.getLast(children);
//和最后一个节点前缀部分匹配
if (lastChild.partiallyMatchesToken(bytes)) {
lastChild.addSorted(bytes);
return;
}
}
然后再走的这段代码:
int childNodeDepth = nodeDepth + 1;
int childTokenStartOffset = tokenStartOffset + numIdenticalTokenBytes;
TokenizerNode newChildNode = builder.addNode(this, childNodeDepth, childTokenStartOffset,
bytes, tailOffset);
addChild(newChildNode);
![4acd330f539b28fc1aa71b145498bc23e53c9e6a]()
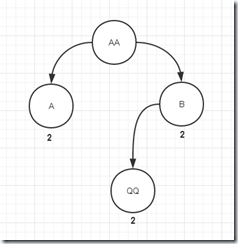
6、添加AABQQ,和之前的一样,这里就不重复了,增加QQ的出现次数。
构建玩Trie树之后,在flush的时候还做了很多操作,为这棵树构建索引信息,方便查询,这块博主真的无能为力了,不知道怎么才能把这块讲好。