前言
Tungsten 中文是钨丝的意思。 Tungsten Project 是 Databricks 公司提出的对Spark优化内存和CPU使用的计划,该计划初期似乎对Spark SQL优化的最多。不过部分RDD API 还有Shuffle也因此受益。
简述
Tungsten-sort优化点主要在三个方面:
- 直接在serialized binary data上sort而不是java objects,减少了memory的开销和GC的overhead。
- 提供cache-efficient sorter,使用一个8bytes的指针,把排序转化成了一个指针数组的排序。
- spill的merge过程也无需反序列化即可完成
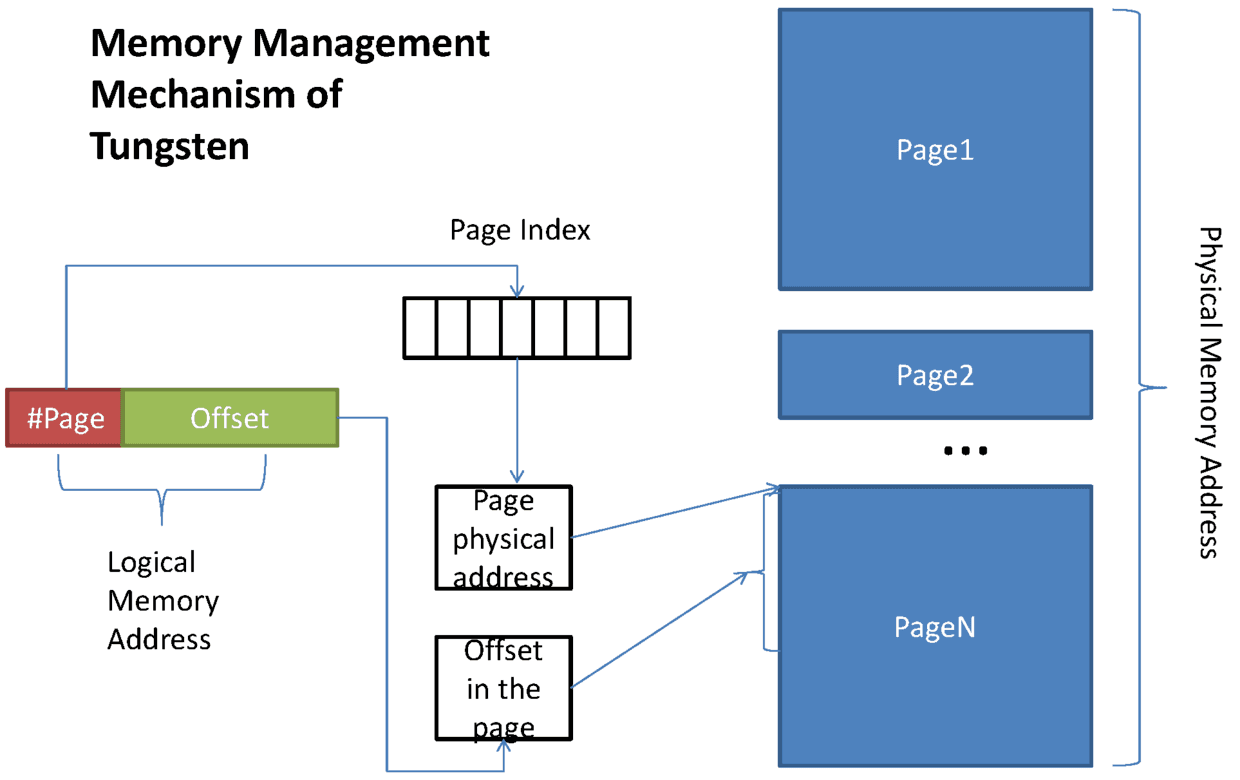
这些优化的实现导致引入了一个新的内存管理模型,类似OS的Page,对应的实际数据结构为MemoryBlock,支持off-heap 以及 in-heap 两种模式。为了能够对Record 在这些MemoryBlock进行定位,引入了Pointer(指针)的概念。
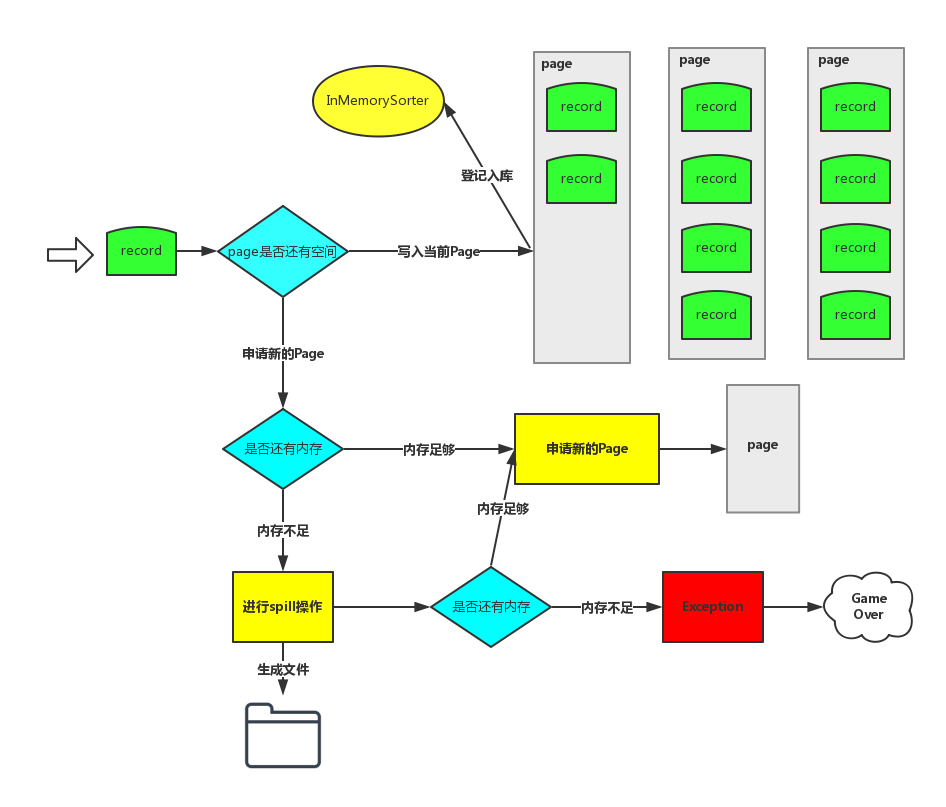
如果你还记得Sort Based Shuffle里存储数据的对象PartitionedAppendOnlyMap,这是一个放在JVM heap里普通对象,在Tungsten-sort中,他被替换成了类似操作系统内存页的对象。如果你无法申请到新的Page,这个时候就要执行spill操作,也就是写入到磁盘的操作。具体触发条件,和Sort Based Shuffle 也是类似的。
开启条件
Spark 默认开启的是Sort Based Shuffle,想要打开Tungsten-sort ,请设置
spark.shuffle.manager=tungsten-sort
对应的实现类是:
org.apache.spark.shuffle.unsafe.UnsafeShuffleManager
名字的来源是因为使用了大量JDK Sun Unsafe API。
当且仅当下面条件都满足时,才会使用新的Shuffle方式:
- Shuffle dependency 不能带有aggregation 或者输出需要排序
- Shuffle 的序列化器需要是 KryoSerializer 或者 Spark SQL's 自定义的一些序列化方式.
- Shuffle 文件的数量不能大于 16777216
- 序列化时,单条记录不能大于 128 MB
可以看到,能使用的条件还是挺苛刻的。
这些限制来源于哪里
参看如下代码,page的大小:
this.pageSizeBytes = (int) Math.min(
PackedRecordPointer.MAXIMUM_PAGE_SIZE_BYTES,
shuffleMemoryManager.pageSizeBytes());
这就保证了页大小不超过PackedRecordPointer.MAXIMUM_PAGE_SIZE_BYTES 的值,该值就被定义成了128M。
而产生这个限制的具体设计原因,我们还要仔细分析下Tungsten的内存模型:
这张图其实画的是 on-heap 的内存逻辑图,其中 #Page 部分为13bit, Offset 为51bit,你会发现 2^51 >>128M的。但是在Shuffle的过程中,对51bit 做了压缩,使用了27bit,具体如下:
[24 bit partition number][13 bit memory page number][27 bit offset in page]
这里预留出的24bit给了partition number,为了后面的排序用。上面的好几个限制其实都是因为这个指针引起的:
- 一个是partition 的限制,前面的数字 16777216 就是来源于partition number 使用24bit 表示的。
- 第二个是page number
- 第三个是偏移量,最大能表示到2^27=128M。那一个task 能管理到的内存是受限于这个指针的,最多是 2^13 * 128M 也就是1TB左右。
有了这个指针,我们就可以定位和管理到off-heap 或者 on-heap里的内存了。这个模型还是很漂亮的,内存管理也非常高效,记得之前的预估PartitionedAppendOnlyMap的内存是非常困难的,但是通过现在的内存管理机制,是非常快速并且精确的。
对于第一个限制,那是因为后续Shuffle Write的sort 部分,只对前面24bit的partiton number 进行排序,key的值没有被编码到这个指针,所以没办法进行ordering
同时,因为整个过程是追求不反序列化的,所以不能做aggregation。
Shuffle Write
核心类:
org.apache.spark.shuffle.unsafe.UnsafeShuffleWriter
数据会通过 UnsafeShuffleExternalSorter.insertRecordIntoSorter 一条一条写入到 serOutputStream 序列化输出流。
这里消耗内存的地方是
serBuffer = new MyByteArrayOutputStream(1024 * 1024)
默认是1M,类似于Sort Based Shuffle 中的ExternalSorter,在Tungsten Sort 对应的为UnsafeShuffleExternalSorter,记录序列化后就通过sorter.insertRecord方法放到sorter里去了。
这里sorter 负责申请Page,释放Page,判断是否要进行spill都这个类里完成。代码的架子其实和Sort Based 是一样的。
(另外,值得注意的是,这张图里进行spill操作的同时检查内存可用而导致的Exeception 的bug 已经在1.5.1版本被修复了,忽略那条路径)
内存是否充足的条件依然shuffleMemoryManager 来决定,也就是所有task shuffle 申请的Page内存总和不能大于下面的值:
ExecutorHeapMemeory * 0.2 * 0.8
上面的数字可通过下面两个配置来更改:
spark.shuffle.memoryFraction=0.2
spark.shuffle.safetyFraction=0.8
UnsafeShuffleExternalSorter 负责申请内存,并且会生成该条记录最后的逻辑地址,也就前面提到的 Pointer。
接着Record 会继续流转到UnsafeShuffleInMemorySorter中,这个对象维护了一个指针数组:
private long[] pointerArray;
数组的初始大小为 4096,后续如果不够了,则按每次两倍大小进行扩充。
假设100万条记录,那么该数组大约是8M 左右,所以其实还是很小的。一旦spill后该UnsafeShuffleInMemorySorter就会被赋为null,被回收掉。
我们回过头来看spill,其实逻辑上也异常简单了,UnsafeShuffleInMemorySorter 会返回一个迭代器,该迭代器粒度每个元素就是一个指针,然后到根据该指针可以拿到真实的record,然后写入到磁盘,因为这些record 在一开始进入UnsafeShuffleExternalSorter 就已经被序列化了,所以在这里就纯粹变成写字节数组了。形成的结构依然和Sort Based Shuffle 一致,一个文件里不同的partiton的数据用fileSegment来表示,对应的信息存在一个index文件里。
另外写文件的时候也需要一个 buffer :
spark.shuffle.file.buffer = 32k
另外从内存里拿到数据放到DiskWriter,这中间还要有个中转,是通过
final byte[] writeBuffer = new byte[DISK_WRITE_BUFFER_SIZE=1024 * 1024];
来完成的,都是内存,所以很快。
Task结束前,我们要做一次mergeSpills操作,然后形成一个shuffle 文件。这里面其实也挺复杂的,如果开启了
`spark.shuffle.unsafe.fastMergeEnabled=true`
并且没有开启
`spark.shuffle.compress=true`
或者压缩方式为:
则可以非常高效的进行合并,叫做transferTo。不过无论是什么合并,都不需要进行反序列化。
Shuffle Read
Shuffle Read 完全复用HashShuffleReader,具体参看 Sort-Based Shuffle。
总结
我个人感觉,Tungsten-sort 实现了内存的自主管理,管理方式模拟了操作系统的方式,通过Page可以使得大量的record被顺序存储在内存,整个shuffle write 排序的过程只需要对指针进行运算(二进制排序),并且无需反序列化,整个过程非常高效,对于减少GC,提高内存访问效率,提高CPU使用效率确实带来了明显的提升。