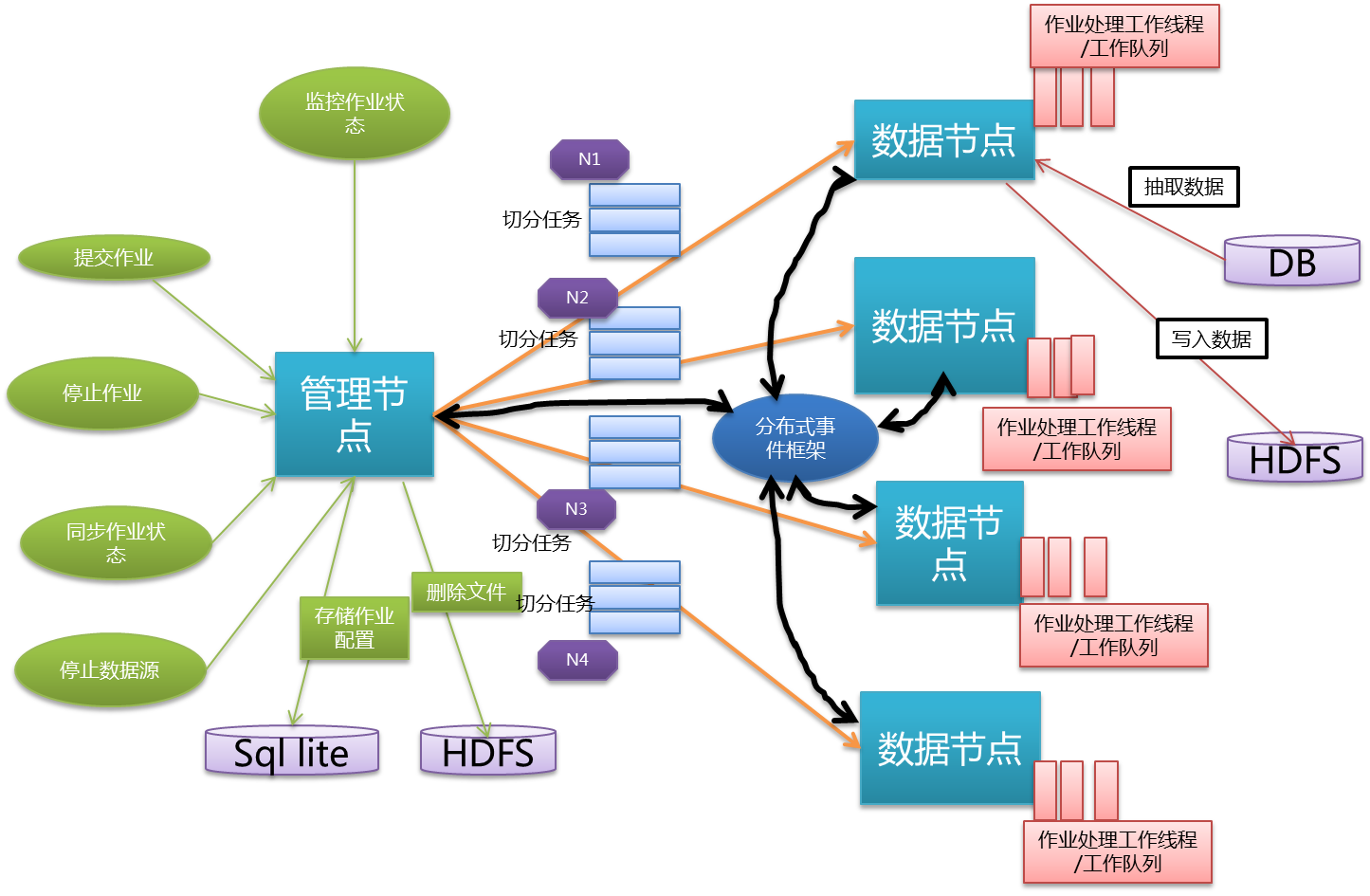
bboss大数据抽取工具功能特点如下:
- 实现db到hadoop hdfs数据导入功能,提供高效的分布式并行处理能力,可以采用数据库分区、按字段分区、分页方式并行批处理抽取db数据到hdfs文件系统中;能有效解决按字段分区抽取数据时,各分区数据不均匀导致作业任务处理节点负载不均衡的问题。
- 灵活的作业任务处理模式:可以增量方式执行作业任务,作业可以停止后重新执行,重新执行时只需执行未完成的作业任务,也可以全部重新执行所有作业任务;当停止作业后,可以在原有作业切分的基础进一步切分出子任务,然后再重新执行作业,提升系统处理数据效率。
- 数据处理服务器为每个作业分配独立的作业任务处理工作线程和任务执行队列,作业之间互不干扰
- 采用异步事件驱动模式来管理和分发作业指令、采集作业状态数据。
- 通过管理监控端,可以实时监控作业在各个数据处理节点作业任务的实时运行状态,查看作业的历史执行状态,方便地实现提交新的作业、重新执行作业、停止正在执行的作业、清除作业执行监控数据、同步作业任务执行状态等操作
工具架构拓扑图:
![img_268c3716637d86043030487d62aada4d.png]()
所采用的技术体系:
- Bboss ioc:轻量级ioc容器,ioc扩展属性配置语法
- Bboss持久层:高效数据查询行处理器,灵活动态数据源管理(连接池数据源/非连接池数据源),表分区信息查询等,动态创建作业配置表和作业监控记录表
- Bboss分布式事件框架:基于JGroups,提供异步分布式事件驱动模型,动态管理作业节点(服务节点和数据处理节点),包括作业节点的动态加入、动态离开等;在管理节点、数据处理节点之间分发和接收各种作业处理指令事件
- Bboss mvc:实现监控管理应用模块,在监控服务节点中,通过mvc 容器启动监听器启动作业管理节点
- Bboss序列化组件:用来将作业监控数据序列化存储到sqllite中的作业监控表,同时在查看作业执行历史时将序列化存储的作业监控数据还原为对象状态的监控对象,便于界面展示
- Bboss 标签库,jquery等:实现监控管理应用的视图层
- Hadoop Hdfs客户端:用来连接hadoop hdfs文件系统
- Sqllite:在监控节点中保存作业配置,保存作业执行状态数据
- Jetty:运行监控管理应用模块的web应用容器
- Bboss应用执行容器:用来启动作业管理监控应用、作业数据处理应用、启动jetty容器
bboss大数据抽取工具源码github托管地址:
https://github.com/bbossgroups/bigdatas
版本源码和发布包下载地址:
https://github.com/bbossgroups/bigdatas/releases
操作使用文档:
大数据抽取工具管理操作手册.docx