spaCy 是一个 Python 和 CPython 的 NLP 自然语言文本处理库。spaCy 2.2 自然语言处理库更精简,更干净,更方便用户使用,除了用于培训、评估和序列化的新模型包和特性之外,还进行了大量的 bug 修复,改进了调试和错误处理,并大大减少了磁盘上库的大小。
新模型与数据增强
spaCy v2.2 提供了经过再培训的统计模型,其中包括修复错误和改进大小写文本的性能。与其他统计模型一样,spaCy 的模型可能对培训数据和正在处理的数据之间的差异非常敏感。
用于训练的新 CLI 功能
spaCy v2.2 包括对培训和数据开发工作流的几个可用性改进,特别是对于文本分类。改进了错误消息,更新了文档,并使评估指标更加详细。例如,评估现在默认提供每一实体类型和每文本类别的准确性统计信息。最有用的改进之一是在 spaCy train 命令行接口中集成了对文本分类器的支持。现在可以编写如下命令,就像在训练解析器、实体识别器或标记器时一样:
$ python -m spacy train en /output /train /dev --pipeline textcat
--textcat-arch simple_cnn --textcat-multilabel
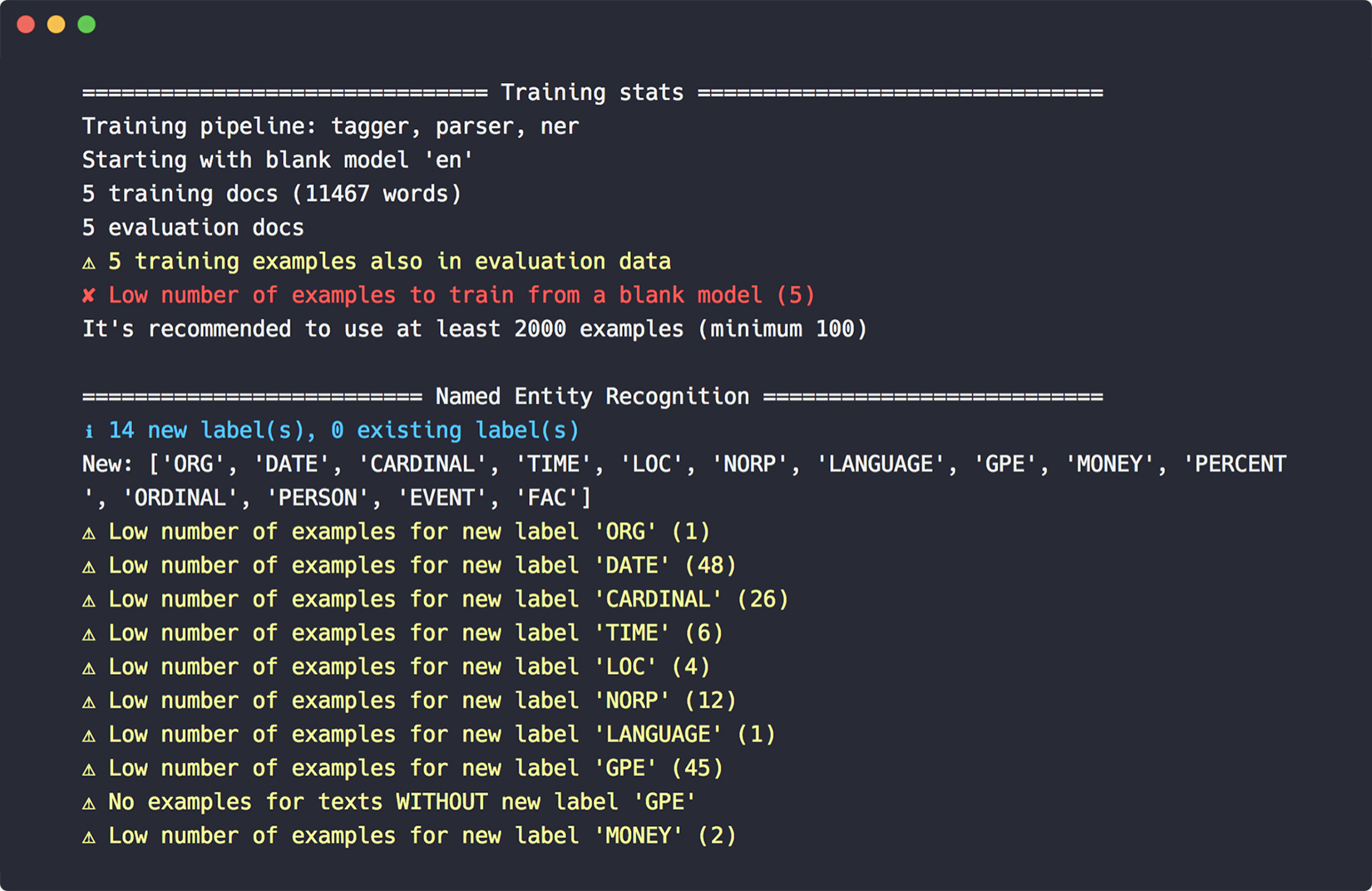
为了使培训更加容易,还引入了一个新的 debug-data 命令,以验证你的培训和开发数据,获取有用的统计数据,并发现诸如无效的实体注释、循环依赖关系、低数据标签等问题。
![]()
更小的磁盘占有,更好的语言资源处理
随着 spaCy 支持更多的语言,磁盘占用也在上升,特别是当添加了对基于查找的 lemmatization 表的支持时,这些表作为 Python 文件存储,在某些情况下变得相当大。此版已经将这些查找表转换为压缩的 JSON,并将它们移到一个单独的包 spacy-look-data 中。
用于高效序列化的 DocBin
高效的序列化对于大规模文本处理是非常重要的,对于许多用例,一种很好的方法是使用 Doc.to_Array 方法将 spaCy Doc 对象序列化为 numpy 数组。然而,这种方法确实失去了一些信息。
新的 DocBin 类帮助你高效地序列化和反序列化 Doc 对象的集合,自动处理许多细节。下面是一个基本用法示例:
import spacy
from spacy.tokens import DocBin
doc_bin = DocBin(attrs=["LEMMA", "ENT_IOB", "ENT_TYPE"], store_user_data=True)
texts = ["Some text", "Lots of texts...", "..."]
nlp = spacy.load("en_core_web_sm")
for doc in nlp.pipe(texts):
doc_bin.add(doc)
bytes_data = docbin.to_bytes()
# Deserialize later, e.g. in a new process
nlp = spacy.blank("en")
doc_bin = DocBin().from_bytes(bytes_data)
docs = list(doc_bin.get_docs(nlp.vocab))
Better Dutch NER with 20 categories
2.2 中引入新的数据集,这将对经过预先训练的 Dutch NER 模型更加有用。然而,之前的评估是对半自动创建的维基百科数据进行的,这使得该模型更容易获得高分。当在模型训练管道中加入预训练词向量和支持 spaCy pretrain 命令时,模型的精度会进一步提高。
![]()
新的视频系列
官方还提供了新的面向初学者的视频教程系列,与数据科学讲师 Vincent Warmerdam 合作。
更多详情见发布说明:
https://explosion.ai/blog/spacy-v2-2