什么是yaml
YAML是"YAML Ain't a Markup Language"(YAML不是一种置标语言)的递归缩写,早先YAML的意思其实是:"Yet Another Markup Language"(另外一种置标语言),但为了强调这种语言以数据做为中心,而不是以置标语言为重点,而用返璞词重新命名,YAML的官方定义很简单,即一种人性化的数据格式定义语言,其主要功能用途类似于XML或JSON,YAML使用空白字符和分行来分隔数据,且巧妙避开各种封闭符号,如:引号、括号等,以避免这些符号在复杂层次结构中变得难以辨认。YAML的语法与高阶语言类似,可以很简单地表述序列(java中的list)、杂凑表(java中的map)、标量(java中的基本类型等)数据结构,它重点强调可阅读性。
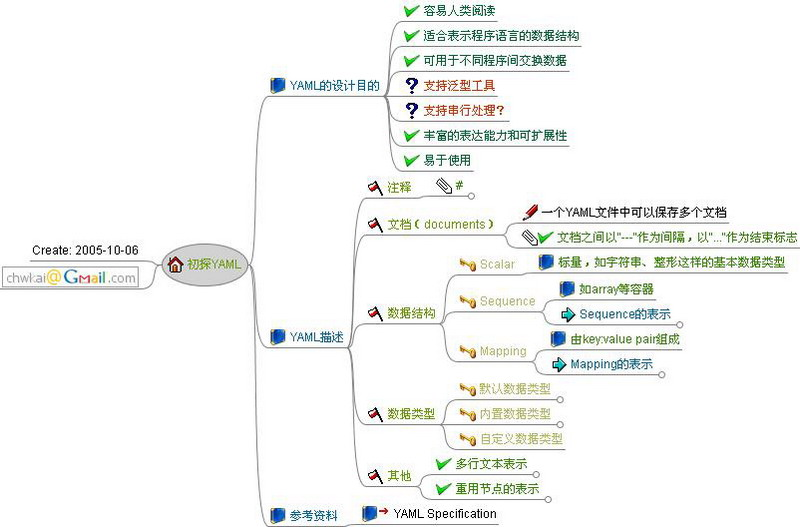
YAML的设计目的
- 容易人类阅读
- 适合表示程序语言的数据结构
- 可用于不同程序间交换数据
- 支持泛型工具
- 支持串行处理?
- 丰富的表达能力和可扩展性
- 易于使用
xml和yaml的代码块:
xml代码块:
<site>
<name>github</name>
<url>https://github.com</url>
</site>
<site>
<name>简书</name>
<url>https://www.jianshu.com</url>
</site>
yaml代码块:
---
site:
name: github
url: https://github.com
---
site:
name: 简书
url: https://www.jianshu.com
---
#或者
---
site:{name:github,url:https://github.com}
---
site:{name:简书,url:https://jianshu.com}
主要标记
# Comment Example
# Profile Of Mary
Mary:
- name: Mary
- age : 19 # age property
# documents example
---
site:
name: github
url: https://github.com
---
site:
name: 简书
url: https://www.jianshu.com
例子:我们用YAML来描述一本书:
# 《单元测试之道-c#版》描述
--- # begin of document
书名 : '单元测试之道-C#版'
出版社: '电子工业出版社'
原作者: ['Andrew Hunt', 'David Thomas']
译者 :
- 陈伟柱
- 陶文
前二章节 :
- 第一章: 序言
- 第二章: 你的首个单元测试计划
#end document
注意:YAML推荐使用空格作为缩进,避免了在不同编辑器中对tab的表示形式不同而可能产生误解。
YAML 与 XML
优势:
- YAML的可读性好
- YAML和脚本语言的交互性好
- YAML使用实现语言的数据类型
- YAML有一个一致的信息模型
- YAML易于实现
上面5条是XML不足的地方,同时,YAML也具有XML的下列优点:
- YAML可以基于流来处理
- YAML表达能力强,扩展性好
YAML类似于XML的数据描述语言,语法比XML简单很多,YAML试图用一种比XML更敏捷的方式,来完成XML所完成的任务。
YAML 与 JSON
JSON的语法其实是YAML的子集,大部分的JSON文件都可以被YAML的剖析器剖析。虽然大部分的数据分层形式也可以使用类似JSON的格式,不过YAML并不建议这样使用,除非这样编写能让文件可读性增加,更重要的是,YAML的许多扩展在JSON是找不到的,如:进阶资料形态、关系锚点、字串不需要引号、映射资料形态会储存键值的顺序等。
YAML用途
脚本语言
由于实现简单,解析成本很低,YAML特别适合在脚本语言中使用。列一下现有的语言实现:Ruby,Java,Perl,Python,PHP,OCaml,JavaScript,除了Java,其他都是脚本语言。
序列化
YAML比较适合做序列化。因为它是宿主语言数据类型直转的。
配置文件
YAML做配置文件也不错。写YAML要比写XML快得多(无需关注标签或引号),并且比ini文档功能更强。
调试
由于其很强的阅读性,用于调试过程中dump出信息供分析也是一种比较方便的做法。
YAML缺陷与不足
YAML没有自己的数据类型的定义,而是使用实现语言的数据类型。一个YAML文件,在不同语言中解析后得到的数据类型可能会不同,由于其兼容性问题,不同语言间的数据流转不建议使用YAML。
YAML语法与范例
- YAML使用可打印的Unicode字符,可使用UTF-8或UTF-16
- 使用空白字符(不能使用<kbd>Tab</kbd>)分层,同层元素左侧对齐
- 单行注解由井字号(<kbd> #</kbd> )开始,可以出现在行中任何位置
- 每个清单成员以单行表示,并用短杠+空白(<kbd>- </kbd>)起始
- 每个杂凑表的成员用冒号+空白(<kbd>: </kbd>)分开键和值
- 杂凑表的键值可以用问号 (<kbd>?</kbd>)起始,表示多个词汇组成的键值
- 字串一般不使用引号,但必要的时候可以用引号框住
- 使用双引号表示字串时,可用倒斜线(<kbd></kbd>)进行特殊字符转义
- 区块的字串用缩排和修饰词(非必要)来和其他资料分隔,有新行保留(使用符号<kbd>|</kbd>)或新行折叠(使用符号<kbd>></kbd>)两种方式
- 在单一档案中,可用连续三个连字号(<kbd>---</kbd>)区分多个档案
- 可选择性的连续三个点号(<kbd>...</kbd>)用来表示档案结尾(在流式传输时非常有用,不需要关闭流即可知道到达结尾处)
- 重复的内容可使从参考标记星号 (<kbd>*</kbd>)复制到锚点标记(<kbd>&</kbd>)
- 指定格式可以使用两个惊叹号 ( !! ),后面接上名称
receipt: Oz-Ware Purchase Invoice
date: 2007-08-06
customer:
given: Dorothy
family: Gale
items:
- part_no: A4786
descrip: Water Bucket (Filled)
price: 1.47
quantity: 4
- part_no: E1628
descrip: High Heeled "Ruby" Slippers
price: 100.27
quantity: 1
bill-to: &id001
street: |
123 Tornado Alley
Suite 16
city: East Westville
state: KS
ship-to: *id001
specialDelivery: >
Follow the Yellow Brick
Road to the Emerald City.
Pay no attention to the
man behind the curtain.
...
这个文件的的顶层由七个键值组成:其中一个键值"items",是个两个元素构成的清单,清单中的两个元素同时也是包含了四个键值的杂凑表。
文件中重复的部分处理方式:使用锚点(&)和参考(*)标签将"bill-to"杂凑表的内容复制到"ship-to"杂凑表。也可以在文件中加入选择性的空行,以增加可读性。
YAML的JAVA实现
YAML已经有了多种语言不少实现,详见YAML官网。
一般YAML文件扩展名为.yaml,比如John.yaml,其内容为:
name: John Smith
age: 37
children:
- name: Jimmy Smith
age: 15
- name: Jenny Smith
age: 12
spouse:
name: Jane Smith
age: 25
由于yaml的超强可读性,我们了解到:John今年37岁,两个孩子Jimmy 和Jenny活泼可爱,妻子Jane年轻美貌,而且年仅25岁,一个幸福的四口之家。
对John.yaml进行java描述,抽象出一个Person类,如下:
public class Person {
private String name;
private int age;
private Person sponse;
private Person[] children;
// setXXX, getXXX方法略.
}
现在我们使用java装配一个Jone:
Person john = new Person();
john.setAge(37);
john.setName("John Smith");
Person sponse = new Person();
sponse.setName("Jane Smith");
sponse.setAge(25);
john.setSponse(sponse);
Person[] children = {new Person(), new Person()};
children[0].setName("Jimmy Smith");
children[0].setAge(15);
children[1].setName("Jenny Smith");
children[1].setAge(12);
john.setChildren(children);
使用SnakeYAML实现
项目主页:http://code.google.com/p/snakeyaml/
使用手册:https://code.google.com/p/snakeyaml/wiki/Documentation
SnakeYAML是一个标准的YAML的java实现,它有以下特点:
- 完全支持YAML 1.1,可以跑通规范中的所有示例
- 支持YAML的所有类型
- 支持UTF-8/UTF-16的输入和输出
- 提供了本地java对象的序列化和反序列化的高层API
- 提供相对合理的错误提示信息
使用SnakeYAML将john dump出来,如果有引用相同对象,则dump出到yaml文件会自动使用<kbd>&</kbd>和<kbd></kbd>进行锚点和引用*:
DumperOptions options = new DumperOptions();
options.setDefaultFlowStyle(DumperOptions.FlowStyle.BLOCK);
Yaml yaml = new Yaml(options);
//Yaml yaml = new Yaml();
String dump = yaml.dump(john);
System.out.println(dump);
内容如下:
!!Person
age: 37
children:
- age: 15
children: null
name: Jimmy Smith
sponse: null
- age: 12
children: null
name: Jenny Smith
sponse: null
name: John Smith
sponse:
age: 25
children: null
name: Jane Smith
sponse: null
现在用SnakeYAML把yaml load进来,如果yaml文件中使用了<kbd>&</kbd>和<kbd></kbd>,则会自动对load出来的对象赋相同的值*:
Yaml yaml = new Yaml();
Object load = yaml.load(new FileInputStream(new File("jhon.yaml")));
System.out.println(load.getClass());
System.out.println(yaml.dump(load));
或
Yaml yaml = new Yaml(options);
Person person = yaml.loadAs(inputStream, Person.class);
System.out.println(person.getSponse().getChildren().length);
如果一个yaml文件中有多个文档,由<kbd>---</kbd>分割,解析如下:
Yaml yaml = new Yaml();
int counter = 0;
for (Object data : yaml.loadAll(input)) {
System.out.println(data);
counter++;
}
保存一个Map对象:
Map<String, Object> data = new HashMap<String, Object>();
data.put("name", "Silenthand Olleander");
data.put("race", "Human");
data.put("traits", new String[] { "ONE_HAND", "ONE_EYE" });
Yaml yaml = new Yaml();
String output = yaml.dump(data);
System.out.println(output);
// or
StringWriter writer = new StringWriter();
yaml.dump(data, writer);
System.out.println(writer.toString());
将多个文档dump出到同一个yaml文件中去:
List<Integer> docs = new LinkedList<Integer>();
for (int i = 1; i < 4; i++) {
docs.add(i);
}
DumperOptions options = new DumperOptions();
//options.setCanonical(true);
options.explicitStart(true);
Yaml yaml = new Yaml(options);
System.out.println(yaml.dump(docs));
System.out.println(yaml.dumpAll(docs.iterator()));
--- [1, 2, 3]
--- 1
--- 2
--- 3
| YAML |
JAVA |
| !null |
null |
| !!bool |
Boolean |
| !!int |
Integer, Long, BigInteger |
| !!float |
Double |
| !!binary |
String |
| !!timestamp |
java.util.Date, java.sql.Date, java.sql.Timestamp |
| !!omap, !!pairs |
List of Object[] |
| !!set |
Set |
| !!str |
String |
| !!seq |
List |
| !!map |
Map |
YAML与java类型对照表:
| YAML |
JAVA |
| !null |
null |
| !!bool |
Boolean |
| !!int |
Integer, Long, BigInteger |
| !!float |
Double |
| !!binary |
String |
| !!timestamp |
java.util.Date, java.sql.Date, java.sql.Timestamp |
| !!omap, !!pairs |
List of Object[] |
| !!set |
Set |
| !!str |
String |
| !!seq |
List |
| !!map |
Map |
集合的默认实现是:
- List: ArrayList
- Map: LinkedHashMap
使用JYaml实现
JYaml(最新版本是2007年的,可以考虑放弃了),使用JYaml把Jone “Dump” 出来:
File dumpfile = new File("John_dump.yaml");
Yaml.dump(john, dumpfile);
下面我们看看John_dump.yaml是什么样子:
--- !yaml.test.internal.Person
age: 37
children: !yaml.test.internal.Person[]
- !yaml.test.internal.Person
age: 15
name: Jimmy Smith
- !yaml.test.internal.Person
age: 12
name: Jenny Smith
name: John Smith
sponse: !yaml.test.internal.Person
age: 25
name: Jane Smith
其中!yaml.test.internal.Person是一些类型的信息。load的时候需要用。
现在用JYaml把Jone_dump.yaml load进来:
Person john2 = (Person) Yaml.loadType(dumpfile, Person.class);
还可以用下面的代码dump出没有类型信息的John.yaml:
Yaml.dump(john,dumpfile, true);
我们再来看看JYaml对流处理的支持,为简便起见,我们只是把同一个john写10次:
YamlEncoder enc = new YamlEncoder(new FileOutputStream(dumpfile));
for(int i=0; i<10; i++){
john.setAge(37+i);
enc.writeObject(john);
enc.flush();
}
enc.close();
下面再把这十个对象一个一个读出来(注意while循环退出的方式):
YamlDecoder dec = new YamlDecoder(new FileInputStream(dumpfile));
int age = 37;
while(true){
try{
john = (Person) dec.readObject();
assertEquals(age, john.getAge());
age++;
}catch(EOFException eofe){
break;
}
}
参考文档:
YAML Specification
YAML 数据类型说明
http://blog.csdn.net/conquer0715/article/details/42108061
http://www.cnblogs.com/chwkai/archive/2009/03/01/249924.html