DeepReinforce 团队上周末开源了 Ornith-1,一套专门做编码 Agent 任务的推理模型,MIT 许可,四个规格:9B、31B、35B MoE、397B MoE。全系在 SWE-bench 上拿出了同尺寸最好的成绩。

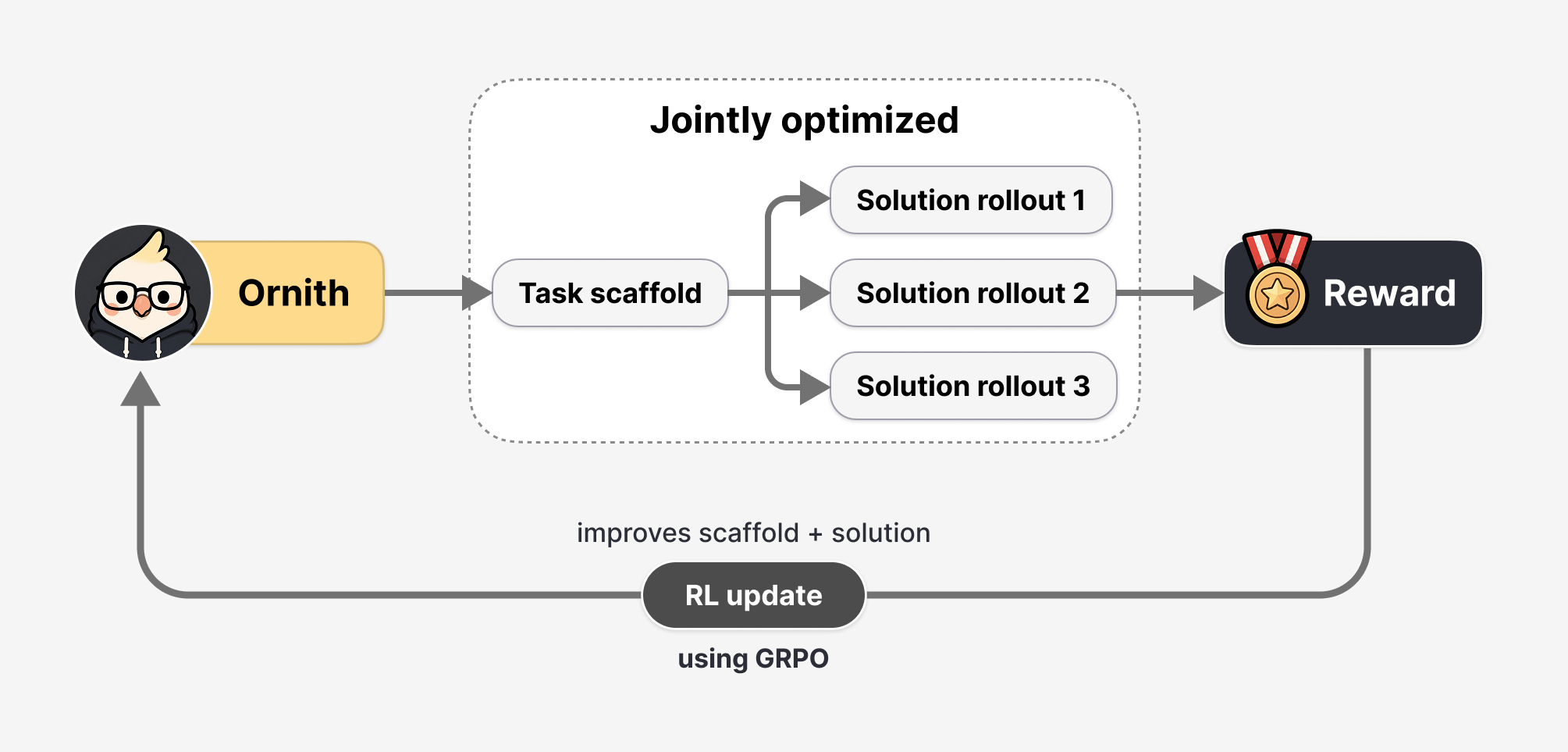
路线不是从零训练。基座用了 Gemma 4 和 Qwen 3.5,然后做 RL post-training,方向是让模型学会"自改进"——训练中不仅生成代码方案,还生成驱动编码过程的"脚手架"。通过联合优化脚手架和最终产出,模型自己探索出了更好的搜索路径。团队管这个叫 self-improving。
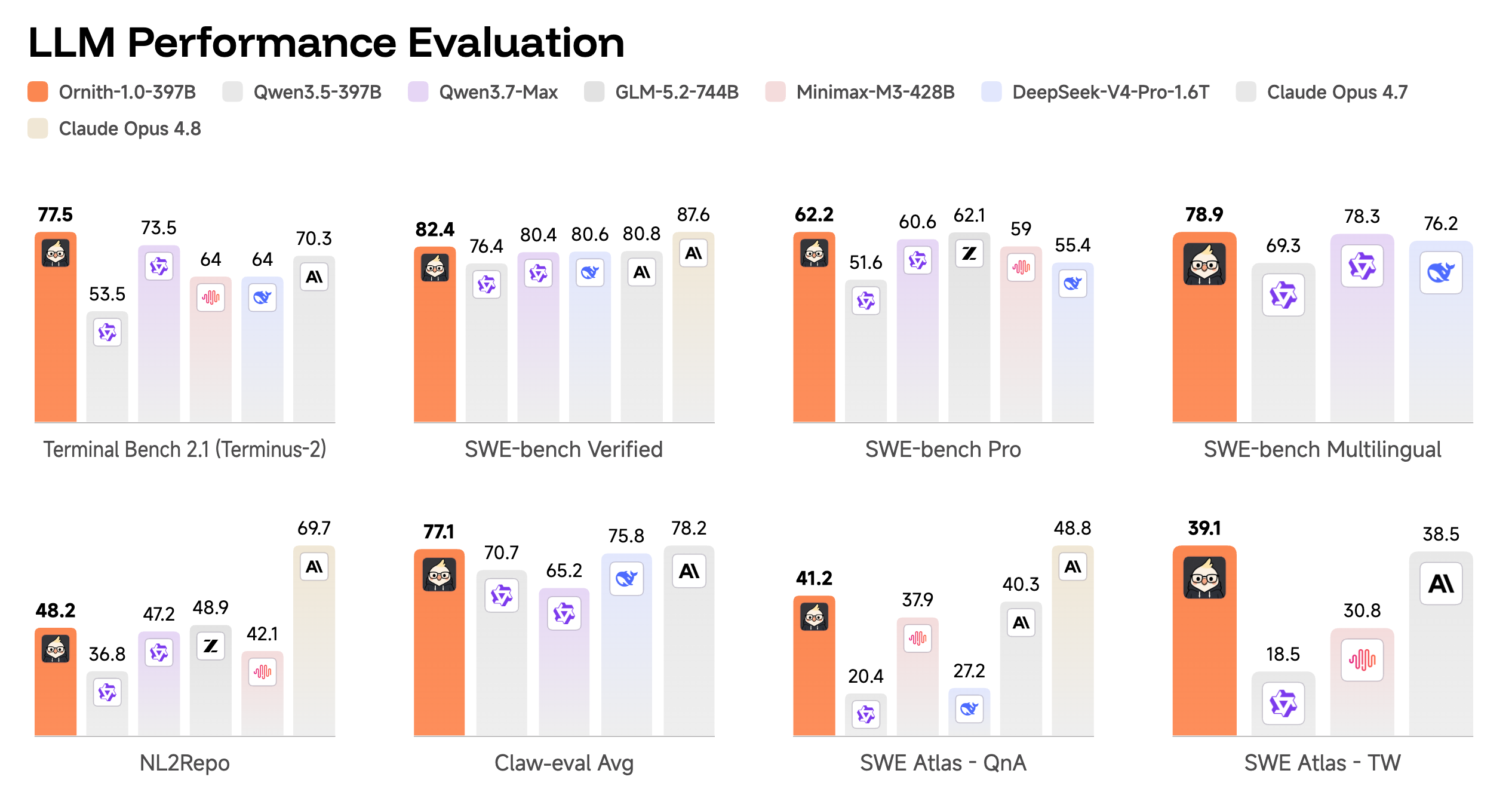
数字很直观。397B 版 SWE-bench Verified 82.4%。同一个 Qwen 3.5 397B 基座原版是 76.4%,Claude Opus 4.8 是 87.6%。Terminal-Bench 2.1 上跑 Terminus-2 拿了 77.5%,Qwen 3.5 397B 只有 53.5%——提了近 24 个百分点。SWE-bench Pro 端到端修复 62.2%,多语言版 78.9%。
小模型上的提升比大模型更值得看。9B 版 Terminal-Bench 43.1%,两倍大的 Gemma 4 31B 是 42.1%,而 Qwen 3.5 同尺寸只有 21.3%。35B MoE 版 64.2%,Qwen 3.5 35B 原版是 41.4%。提升幅度随模型变小而增大——这套 RL 方法压缩的似乎是推理能力而非知识储备。
工程上考虑得很细。256K 上下文窗口,输出带 <think> 推理块(chain-of-thought 放在 reasoning_content 字段里),<tool_call> 块解析出来是标准 OpenAI tool_calls 格式。兼容 vLLM 0.19.1+、SGLang 0.5.9+、Transformers 5.8.1+,提供了 bf16、FP8、GGUF 三种精度。GGUF 版可以在 llama.cpp 和 Ollama 上本地跑。推荐采样参数 temperature=0.6、top_p=0.95、top_k=20。
这套模型的意义不在绝对分数——82.4% 离 Claude Opus 4.8 的 87.6% 还有距离。意义在于路线:一个团队拿公开基座模型,纯靠 RL post-training 榨出近 6 个点的 SWE-bench 提升,而且模型越小提得越猛。代码、权重、训练方法全开源。
参考来源:
