美团宣布正式发布并开源 LongCat-2.0,一个总参数量达 1.6 万亿、每个 token 激活约 480 亿参数的 MoE 语言模型。LongCat-2.0 相比此前的 LongCat 系列引入了多项架构改进,实现了模型能力的显著跃升。
根据介绍,LongCat-2.0 的完整训练流程与大规模部署均全部使用国产算力集群。预训练在5万余国产算力芯片上耗时月余完成,消费了超过 35 万亿 tokens,全程无回滚、无不可恢复的 loss 突刺。
为强化模型在长程任务上的能力,团队引入 LongCat 稀疏注意力机制,并在数千亿 tokens 的百万上下文长度数据上训练 LongCat-2.0。结合专门的后训练,LongCat-2.0 在编程与智能体任务上表现强劲。
LongCat-2.0 深度适配 Claude Code、OpenClaw、Hermes 等主流 Harness,在代码理解、仓库级修改、自动化任务执行及 Agentic Workflow 等多元场景中表现出色,能够为开发者带来更稳定、更高效的智能协作体验。
LongCat-2.0的模型架构设计继承自 LongCat-Flash ,在参数效率以及长上下文训练与推理速度上更进一步。在注意力机制方面,提出 LongCat 稀疏注意力 (LSA):该机制由 DeepSeek 稀疏注意力 (DSA) 演进而来,通过引入更轻量化的索引器(Indexer),在无损模型质量的前提下显著加速长上下文处理。
同时,为了让每个参数发挥更大价值,团队加入 N-gram Embedding 模块,通过 N-gram token 组合将 embedding 空间扩展超过 100 倍,以更充分地建模局部上下文信息,并提升 token 级表示能力。
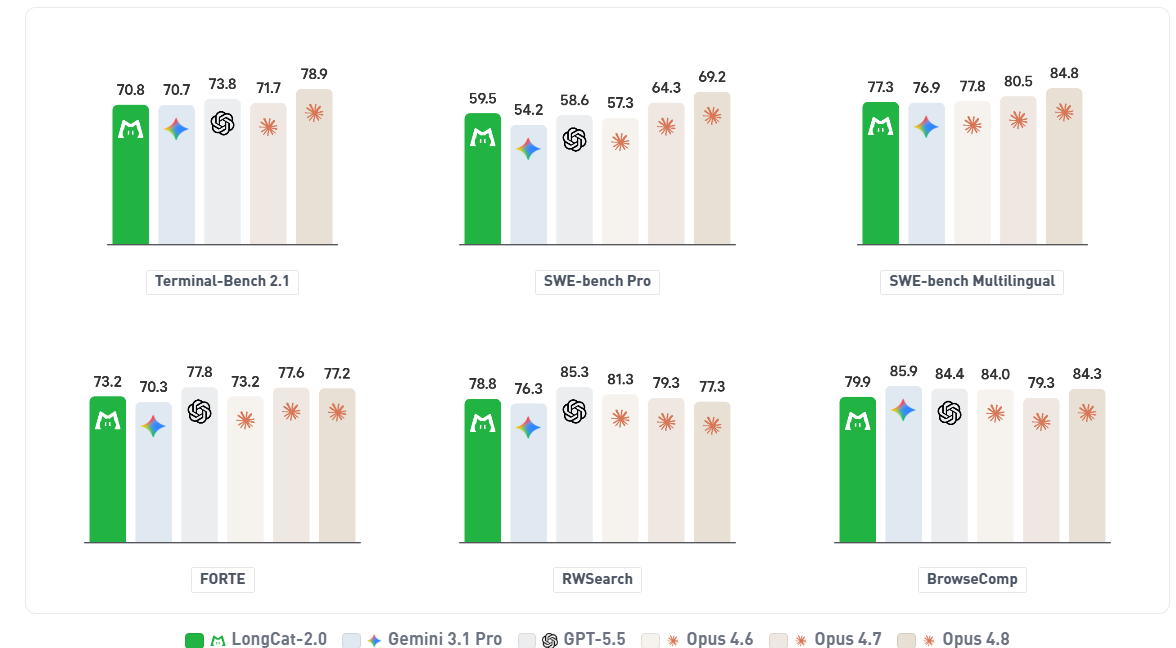
将 LongCat-2.0 在代码、通用 Agent 与基础能力等维度上与领先的闭源模型进行的对比结果如下:
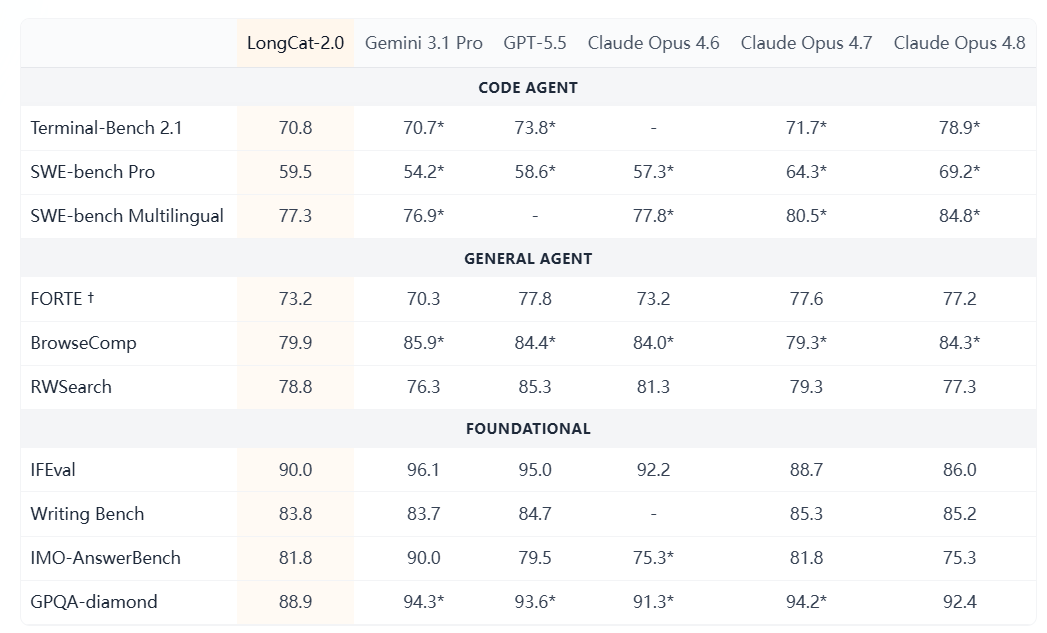
除标注 * 者外,所有分数均在统一的评测框架下由内部测得。
更多详情可查看官方公告:https://longcat.chat/blog/longcat-2.0/
