上周大家还在猜 DeepSeek V4 正式版什么时候发布,昨天 DeepSeek 就把日期定了:七月中旬。
但真正让人意外的不是发布时间,而是 V4 这次带着全新的定价机制一起亮相——峰谷计价。API 调用按北京时间分时段收费,每天上午 9 点到 12 点、下午 2 点到 6 点是峰时,价格翻倍。其余时段维持基准价。

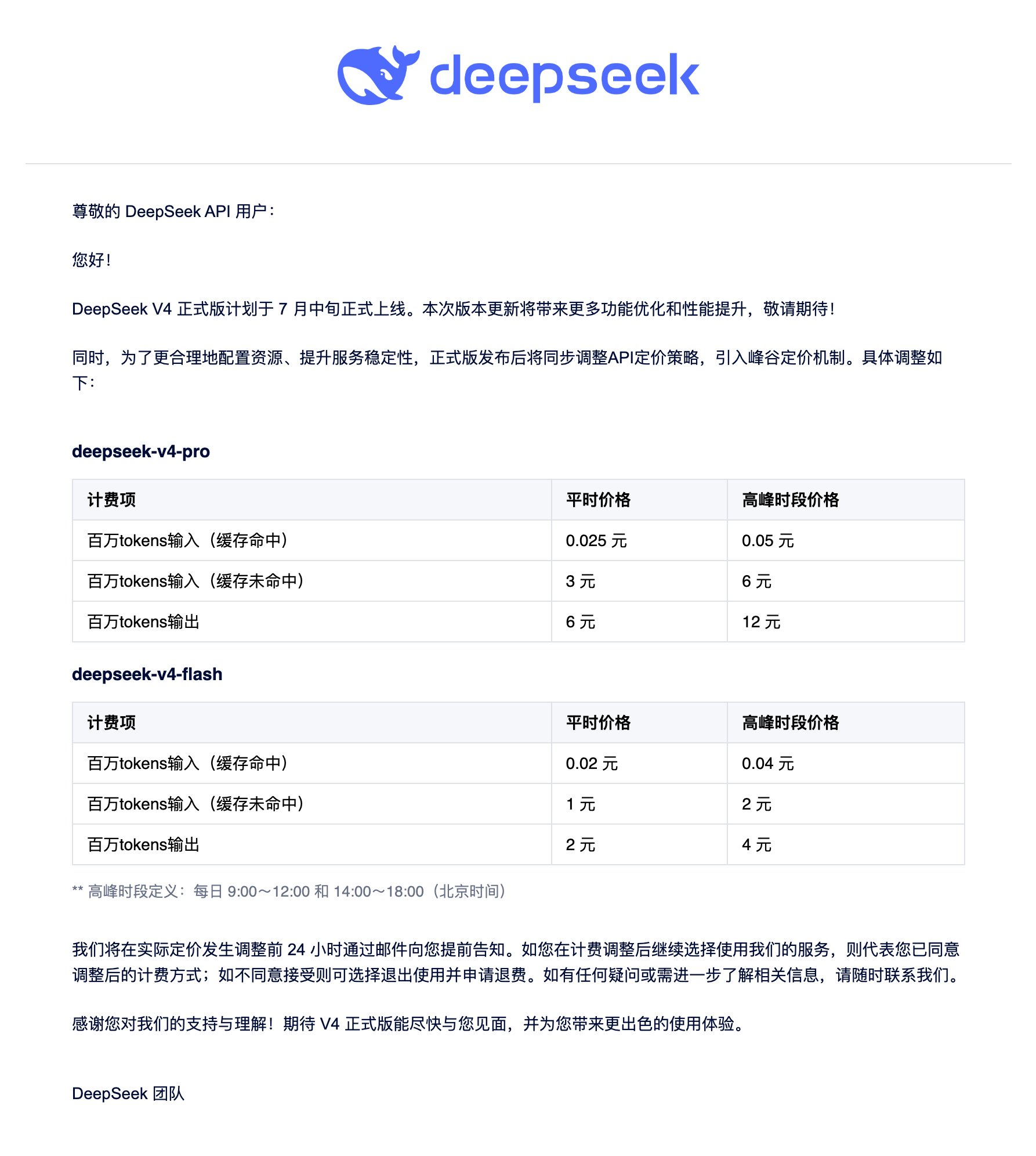
新定价机制的高峰时段价格如下:
deepseek-v4-pro
0.05元人民币/百万token输入(缓存命中)
6元人民币/百万token输入(缓存未命中)
12元人民币/百万token输出
deepseek-v4-flash
0.04元人民币/百万token输入(缓存命中)
2元人民币/百万token输入(缓存未命中)
4元人民币/百万token输出
这事在 LLM API 圈里没有先例。OpenAI、Anthropic、Google 的模型都不看表收钱。DeepSeek 把算力当成电来卖,思路很直白:高峰期资源紧张,涨价压需求;闲时便宜,鼓励用户错峰调用。
DeepSeek V4 正式版首批亮相两个型号:v4-pro 主打高性能,v4-flash 走轻量路线。具体定价(每百万 token,人民币):
- v4-pro 基准价:输入命中缓存 0.025 元,未命中 3 元,输出 6 元。峰时全部翻倍——输出涨到 12 元,输入未命中涨到 6 元。
- v4-flash 基准价:输入命中缓存 0.02 元,未命中 1 元,输出 2 元。峰时同样翻倍到 0.04/2/4 元。
两块多钱的输出价格在同类模型里本来就低,翻一倍也仍然便宜。但峰谷逻辑真正影响的是调用习惯:批量推理、离线 eval、数据清洗这些场景往后挪一两个小时就能省一半,非实时场景没有理由挤在峰时跑。
DeepSeek 团队表示,用户会在计费变更前 24 小时收到邮件通知。目前还没放出技术细节——参数规模、上下文窗口、benchmark 成绩都没公布,这次官宣只讲了定价。
不过峰谷定价这件事本身,可能比 V4 的跑分更有意思。LLM API 从按量计费走到按时段计费,本质上是在承认一个事实:推理算力不是无限的,至少在工作时间不是。
