Deepseek团队近日在GitHub上线了一篇论文,作者栏里有梁文锋的名字。这不是DeepSeek融资5000亿之后的公关动作——这篇论文解决的是一个真实的生产问题:大模型在高并发下怎么保持响应速度。
论文提出的框架叫DSpark,北京大学和DeepSeek联合出品,MIT许可,训练代码和模型权重全在GitHub上的DeepSpec仓库里。

论文标题是《DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation》,6月27日发布。
推测解码不是什么新概念。基本思路是用一个小模型快速生成候选token,再用大模型做并行验证。问题是现有实现有两个明显缺陷:一是草稿模型生成到后面几个token时存活率下降,二是验证环节的算力分配一刀切——不管质量好坏,每个候选token都花一样的预算去验证。
DSpark针对这两个问题各给了一个解法。
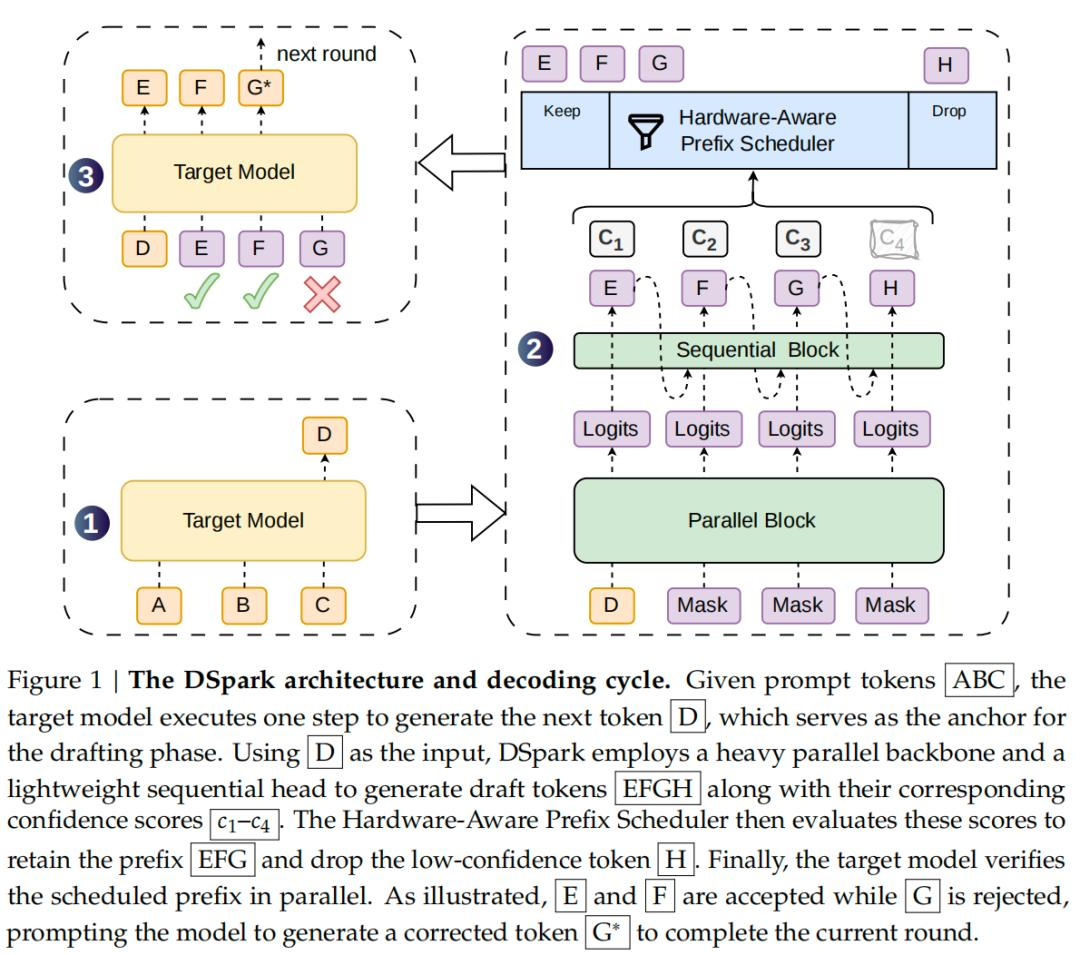
第一个叫半自回归生成。并行主干网络一次性输出候选token的基础特征,然后一个轻量的顺序模块逐token补充依赖关系。结构只有2层Transformer,但候选序列有效生成长度比5层的传统并行模型还长。
第二个叫置信度调度验证。验证调度器根据实时算力负载和前缀的存活概率,动态决定每个请求验证多长的序列。高质量的候选优先验证,尾巴上大概率会被拒的token直接截断。
这两个机制加在一起,在离线基准测试里全面领先了Eagle3和DFlash。以Qwen3-4B为例,单轮有效生成长度比Eagle3高出30.9%,比DFlash高出16.3%。
但更有说服力的是线上。
DeepSeek直接把DSpark部署到了V4-Flash和V4-Pro的预览版引擎上,跑了真实的线上A/B测试。结果是:
V4-Flash在80 token/s的SLA条件下,吞吐量提升51%。把SLA拉紧到120 token/s——也就是要求更高了——吞吐量提升了661%。V4-Pro在35 token/s下提升52%,50 token/s下提升406%。
压力越大,DSpark的效果越明显。高并发场景里节省的算力不是线性的。
单用户生成速度的改善是60%到85%。这在API产品里的含义很直接:同样的模型回答,等待时间几乎减半。
论文还写了一个局限。复杂低适配查询场景下,完整候选块的生成有固定算力开销。并行主干必须生成完整的候选块,即使后面的大部分token被调度器截断,这部分计算也回收不了。这是个已知代价,团队选择在论文里写清楚。
DeepSeek刚完成首轮融资,投后估值5000亿。融资后第一周放出的不是PR稿,而是一篇合作论文加全套开源代码和权重。这个节奏本身传递的信号比任何公告都清楚:在模型推理效率这个赛道上,他们想把它从产品竞争变成基础设施竞争。而开源是最好的推进方式。
参考来源:
