当 AI Agent 应用从研究原型走向真实产品时,开发者面临的核心问题不再是"能不能跑起来",而是:如何管理复杂的状态、如何追踪每一次决策路径、如何在生产环境中可靠地持久化对话历史?Apache Burr(目前处于孵化阶段)试图用一套轻量级 Python 工具集来回答这个问题。
Burr 包括:
- 一个(零依赖)低抽象程度的 Python 库,使您能够使用简单的 Python 函数构建和管理状态机。
- 一个可用于查看执行遥测数据的用户界面,方便进行内省和调试。
- 一系列集成,旨在简化状态持久化、遥测连接以及与其他系统的集成。
Burr 的定位是一个用于构建"会做决策的应用"的框架——聊天机器人、AI Agent、模拟器、实时推理链……这些场景的共同特征是:应用需要维护内部状态、根据输入做出决策、并在执行过程中产生大量需要追踪的中间步骤。
状态机思维与 LLM 的结合
Burr 的核心抽象借鉴了状态机的设计思路。开发者将应用分解为多个"动作"(Action),动作之间通过状态转换串联,每个动作可以调用 LLM、读写外部数据、执行工具调用,或简单地做条件判断。状态在转换过程中被完整记录,这意味着整个应用执行链路都是可追溯的。
这种设计对于 AI Agent 开发者尤为重要。当一个 Agent 在多轮对话中调用了多个工具、多次 LLM、并根据返回结果做出分支选择时,Burr 能将这些步骤完整地记录下来,生成一张可审计的执行图。开发者不仅可以事后回放任意时间点的状态,还能对特定分支进行调试。
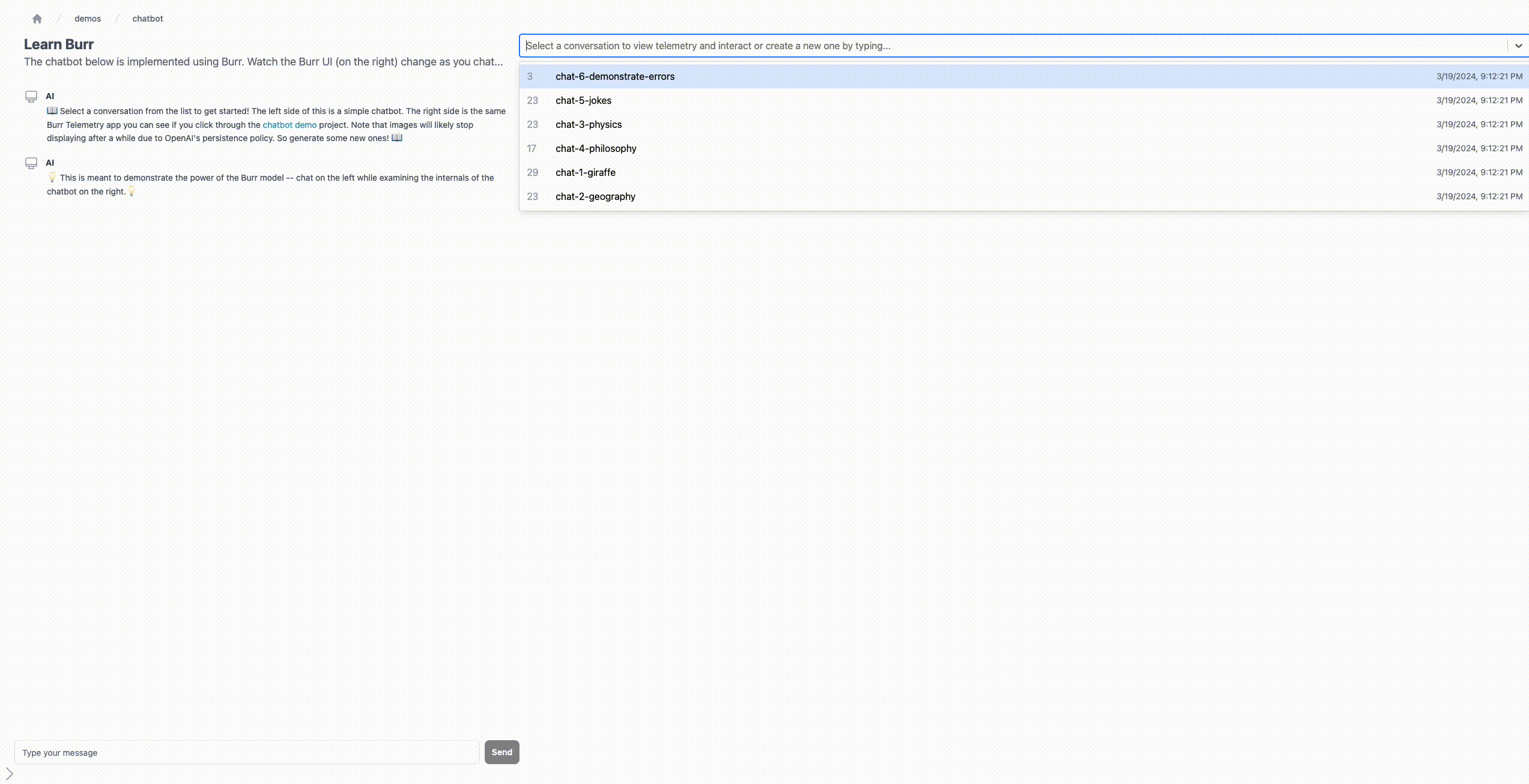
实时追踪与可视化
Burr 提供了一个开箱即用的 Web UI,用于实时监控应用的执行状态。开发者在本地启动 Burr 应用后,可以通过浏览器访问本地端点,查看当前状态机所处的节点、所有变量的当前值,以及每一次状态转换的输入输出。这个 UI 的设计目标很明确:让调试 AI 应用像调试传统 Web 服务一样直观。
与 LangChain 的 Rizon 之类工具类似,Burr 的追踪能力旨在解决 LLM 应用开发中的"黑盒"问题。但 Burr 的不同之处在于,它的追踪是与应用状态机深度绑定的——每一次 LLM 调用不是孤立的 API 请求,而是状态转换链条中的一个环节。
状态持久化:Agent 应用的生产化门槛
将 AI Agent 从 demo 做成产品,最大的工程挑战之一是状态管理。在传统 Web 应用中,用户会话的持久化有成熟方案;但 AI Agent 通常包含大量的中间状态(内存中的对话历史、工具调用结果、推理链的中间步骤),这些状态既需要高效存储,又需要在应用重启后能完整恢复。
Burr 通过可插拔的持久化层(Pluggable Persister)来解决这个问题。开发者可以选择将状态存储在本地文件、数据库或向量数据库中,切换存储后端不需要修改应用逻辑。官方的示例展示了如何将对话历史持久化到 SQLite,并在重启后从断点恢复——对于需要长时间运行的 Agent 应用,这个能力直接决定了它能否用于生产环境。
技术栈与生态定位
Burr 目前主要由 Python 实现(占 63%),其余部分为 TypeScript(用于 Web UI)。作为一个 Apache 软件基金会孵化项目,它目前拥有 2.3k Stars、163 个 Forks和 73 个发布版本,最新版本为 v0.42.0-incubating(2026 年 5 月 10 日发布)。
在 AI 应用开发工具的生态中,Burr 处于什么位置?它不像 LangChain 或 LlamaIndex 那样提供丰富的 LLM 调用封装,它的定位更接近于"应用骨架":当你需要认真构建一个需要状态管理、决策追踪和生产级持久化的 AI 应用时,Burr 提供了一个经过设计的起点,而不是让你从状态机重新搭起。
与其他框架的差异
如果用建筑来类比:LangChain 更像提供了各种现成家具和电器的精装房,Burr 则更像提供了一套承重结构和管道线路的毛坯房。开发者需要在 Burr 之上自行选择和接入 LLM 提供商、向量数据库和部署环境,但换来的是对应用架构的完全掌控和极高的定制灵活性。
这种取舍与当前 AI 应用开发领域的分化趋势一致:对于快速原型和概念验证,LangChain 等框架的开发效率更高;对于需要长期维护、生产级可靠性、以及复杂状态管理的 AI 产品,Burr 这类底层框架提供了更坚实的工程基础。
Apache Burr 仓库地址:https://github.com/apache/burr
