4 月 28 日,DeepSeek 多模态团队研究员陈小康在 X 平台发布了一条意味深长的推文:「Now, we see you.」配图是 DeepSeek 标志性的蓝色鲸鱼 —— 左边戴着海盗眼罩,右边则睁开了双眼。这条推文随后被删除,但「鲸鱼开眼」的隐喻已经传开。
一天后的 4 月 29 日,DeepSeek 正式开启「识图模式」灰度内测。
而到 5 月初,据多家媒体和用户反馈,该功能已大范围开放,「几乎所有测试账号都能看到入口」。不过,入口按钮上至今仍标注着一行小字:「图片理解功能内测中」。
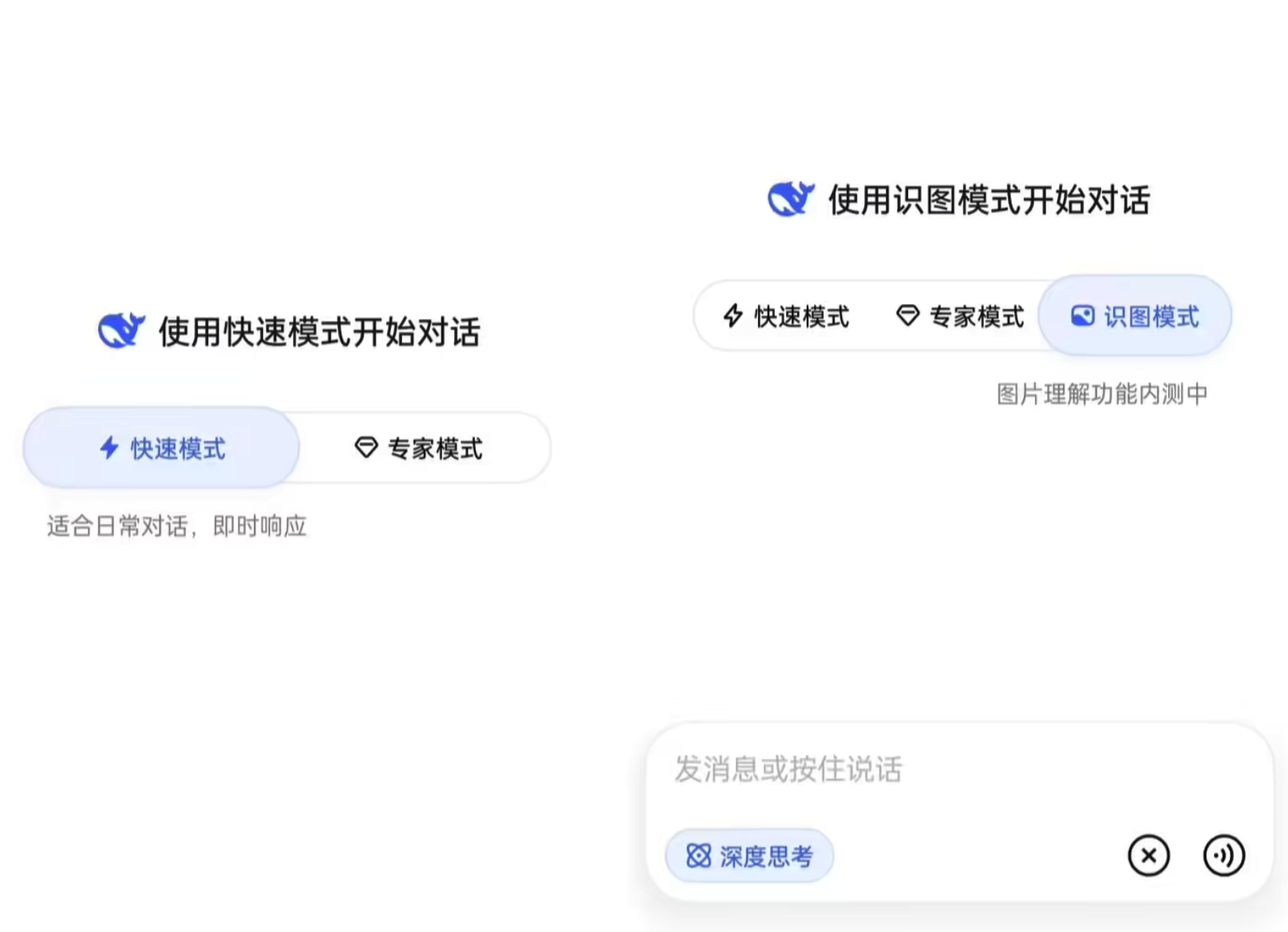
可以看到,在网页端和 App 的对话界面中,「识图模式」作为第三个标签,与原有的「快速模式」「专家模式」并排出现在输入框上方。点击进入后,输入框旁会出现图片上传按钮,支持拖拽、粘贴或点击上传。
与市面上许多「上传图片→提取文字」的 OCR 工具不同,DeepSeek 强调这是深度图像理解 —— 模型不仅能读取画面中的文字,还能理解场景氛围、物体关系、空间逻辑甚至文化语境。
根据灰度用户的广泛测试,识图模式在以下场景表现亮眼:
- 文物鉴定:上传一件玉器照片,非思考模式只能描述外观;开启深度思考后,模型准确识别为「清代痕都斯坦风格」,并给出纹饰和工艺分析。
- 截图转码:上传含 UI 界面的截图,模型能反向生成结构完整、可交互的 HTML 代码,复现按钮和跳转逻辑。
- 空间推理:解答立方体旋转与组装类题目,非思考模式容易出错,但深度思考后能给出正确结论(代价是耗时较长,约 4 分钟)。
- 表情包与梗图:能识别公众人物和动漫角色,并解读其中的幽默逻辑和情绪氛围。
- 地理推断:结合建筑特征和画面中的少量文字,推断出准确的地理位置并给出坐标。

处理效率方面,非思考模式下响应极快,一张 800×800 像素的图像仅消耗约 90 tokens。
多方实测推测,识图模式背后是一个独立于 DeepSeek-V4 Flash/Pro 的视觉理解模型,基于「Thinking with Visual Primitives」框架,属于挂载在 V4 主干上的视觉模块,而非 V4 原生的多模态能力。这也解释了为什么 V4 预览版(4 月 24 日发布)是纯文本模型,识图模式却在短短几天后即开启灰度 —— 这是两条独立的技术线。
识图模式并非万能。在极限测试中,它暴露出明显短板:
- 数手指 / 爱心测试:类似「图中有几只老虎」的计数题,模型容易幻觉,自我博弈后仍可能答错。
- 反色 / 碎块化图片:这类反直觉视觉任务基本失败。
- 复杂行测图形题:非思考模式下错误率较高,深度思考虽能解对但耗时惊人。
- 知识库滞后:对于较新的产品、游戏或机型,模型可能误判(如将小米 15 Ultra 误认为小米 11 Ultra)。
此外,该模式目前不支持图像生成、视频理解、以图搜图和二维码识别,HEIF 等部分图片格式也无法上传。
识图模式的灰度上线,标志着 DeepSeek 从纯文本正式迈入图文交互时代。官方技术报告曾将「将多模态能力融入模型体系」列为未来方向,而灰度上线的识图模式被视为向完整多模态过渡的阶段性产品。后续官方预告的 Vision 版本,可能会承载更原生、更完整的多模态功能。
对于已经获得入口的用户来说,这颗「睁眼的鲸鱼」值得亲自试试。
