小米 AI 实验室新一代 Kaldi 团队(k2-fsa)已推出了 OmniVoice,一款能覆盖 600+ 语种的语音克隆 TTS 模型。目前,OmniVoice 的训练、推理代码以及模型权重已全部开源。
OmniVoice 核心优势有三点:
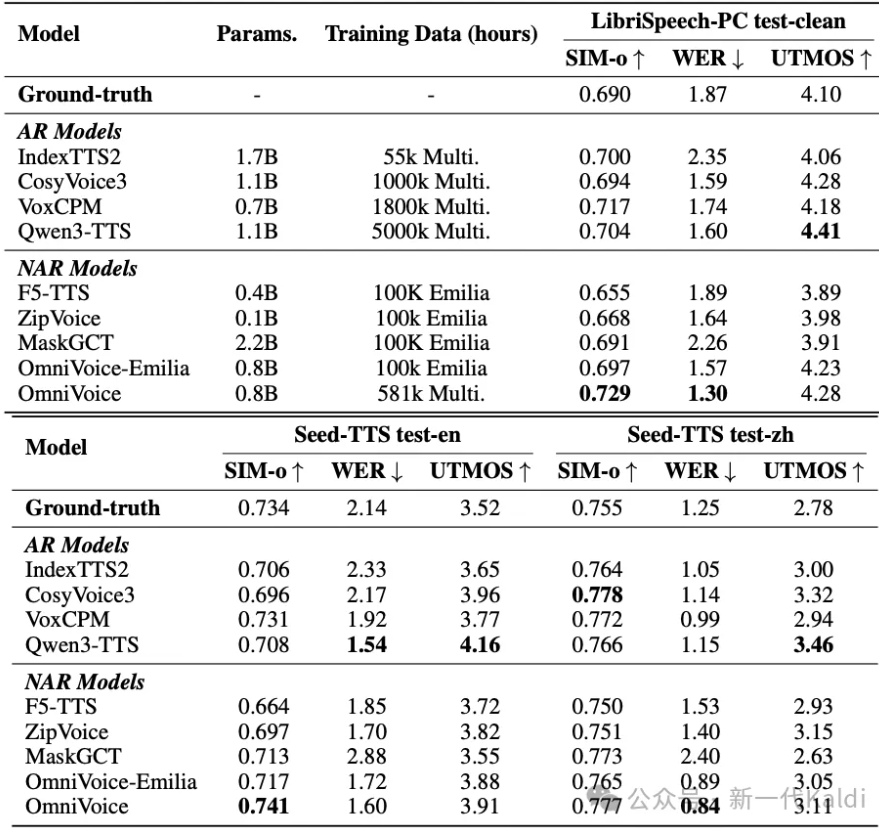
- 极简的超强架构:OmniVoice 是现有非自回归 TTS 模型中最简单的,且合成语音质量最好,同时还具有训练和推理速度上的巨大优势;
- 多语言能力顶尖:覆盖646种语种,在中英文上保持优异能力的同时,让低资源小语种也能实现高质量合成,性能超越商用系统;
- 实用性强:多维度可控,适配多种实际应用场景
![]()
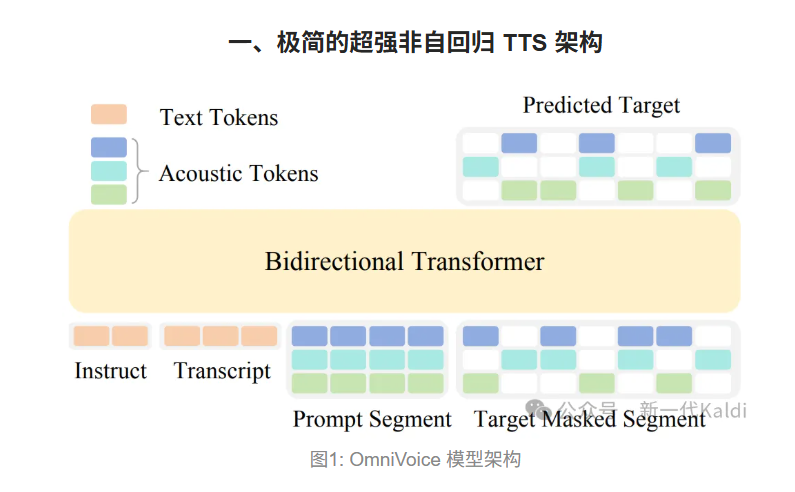
根据介绍,OmniVoice 的模型架构极为简洁,仅包含一个双向的Transformer 网络,模型输入为按顺序排列的文本 token 和多码本声学 token,训练方式就是对多码本声学token进行随机 mask,然后预测被 mask 掉的 token。这可能是目前最简单的非自回归 TTS 模型架构,没有对文本的单独建模,没有 CNN+Transformer 的混合结构,也没有文本到语义 token 再到声学 token 的层级预测。
![]()
OmniVoice 是一个基于离散语音 token 的非自回归 TTS 模型。此前这一类模型通常需要采用两阶段建模,即先预测单码本的语义(semantic)token,再预测多码本的声学(acoustic)token,这种级联方案可以简化每个模块的训练难度,但也会造成级联误差,带来性能瓶颈。近期也有工作尝试将离散非自回归架构修改为端到端的方式,然而,即使采用结合了语义知识蒸馏的复杂方案,其性能依然与两阶段模型存在差距,更不要说超越两阶段模型。
而 OmniVoice 能把单阶段的离散非自回归架构做到超越两阶段的性能,其核心在于两个非常简单易行的技巧:一是使用全码本随机 mask,二是使用预训练 LLM 作为参数初始化。
![]()
为了提高 OmniVoice 在实际场景中的可用性,项目团队进一步为模型增加了多个维度的控制能力。
首先,为模型新增了基于说话人属性的音色设计能力,可通过性别、年龄、音调、方言、口音等控制音色,同时额外支持耳语风格。这一能力的扩展在 OmniVoice 的架构下非常简单,只需在输入序列最前方的指令(instruct)文本中加入对应说话人属性标注即可。
第二,考虑到实际使用场景中,收音设备和录音环境往往并不完美,难以提供音质完美的参考音频。为了解决这个问题,在模型训练中加入了一个参考音频去噪任务,对一小部分训练数据,在语音的提示(prompt)部分添加噪声和混响,而待预测部分则保持原状,同时在指令(instruct)部分给模型添加 <*denoise*> 标签,这样模型就能学到 <*denoise*> 标签时执行去噪任务,提取出带噪语音中的说话人音色。这样,即便提供的参考音频声学环境并不理想,模型也能合成较高质量的语音。
第三,还支持在模型中插入笑声、叹气声等副语言符号,让模型输出更灵活、更有表现力。
第四,模型能力再强,有时也会出现读错字的问题,尤其中文多音字和英文专有名词。为了解决这一问题,其在训练中采用了拼音/音素与文字混合输入的格式,这样在推理时,就可以通过拼音纠正中文错误发音,通过音素纠正英文错误发音,大幅提升模型的可靠性和可用性。