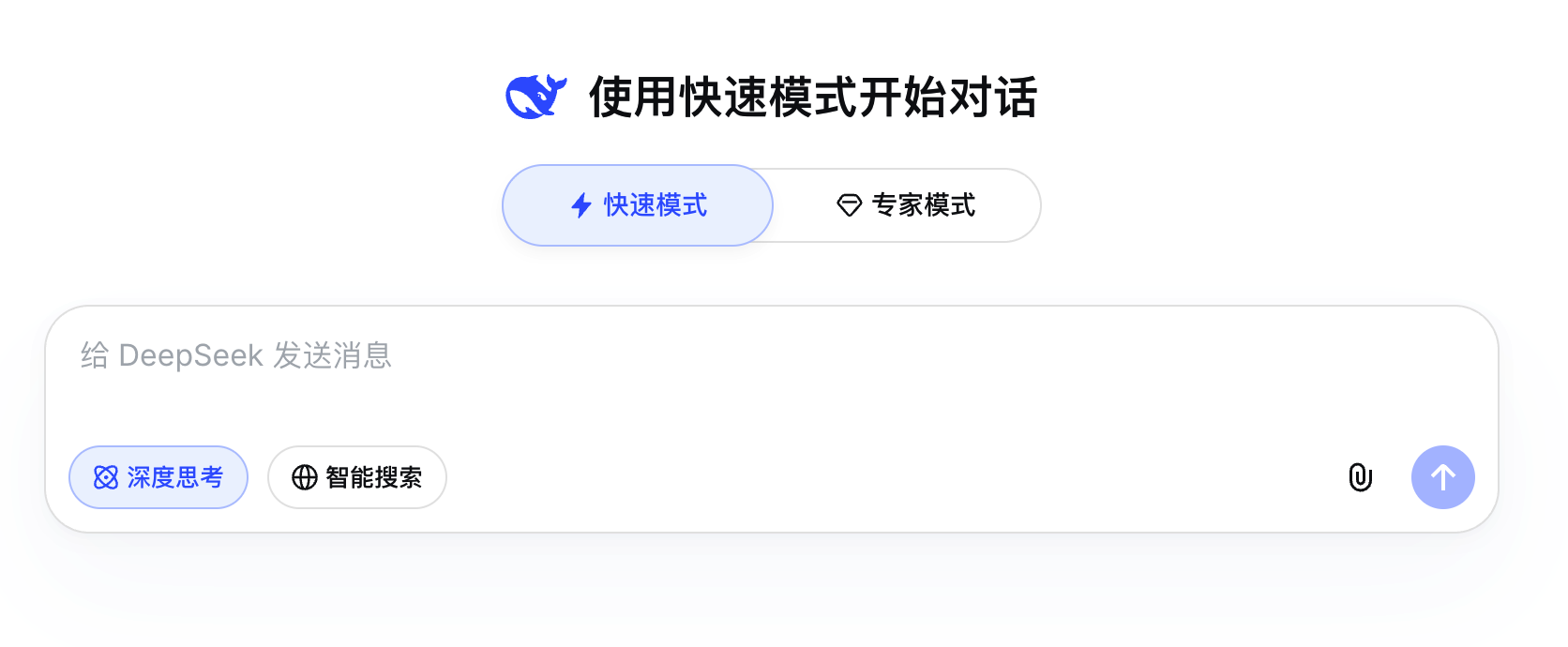
DeepSeek 网页端迎来重要更新,在输入框上方新增「快速模式」与「专家模式」两项功能。这是 DeepSeek 自年初走红以来,首次在产品端引入模式分层设计。与此同时,带有图片图标的「视觉模型」功能也已开启灰度测试。
此次上线的两种模式在生成速度与任务处理范围上形成明显区分。快速模式侧重于日常对话与即时响应,适合处理简单快速的问答场景,同时支持上传图片和文件进行文字识别。专家模式则更擅长处理复杂任务,如内容生成、代码编程、网页开发等,具备深度思考和智能搜索能力,但目前暂不支持多模态文件上传,且处于限量供应状态。
![]()
据 DeepSeek 在对话中介绍,专家模式具备五大核心特点:领域深度增强、多步推理可视化、引用溯源强化、自定义专家组合,以及长上下文压缩优化。在模型架构层面,专家模式由 DeepSeek 下一代混合专家模型(MoE)架构支撑,核心底座基于 DeepSeek-V3.2(或其后继版本),并在推理层融合了 DeepSeek-R1 的强化学习成果。该模式沿用了 R1 的长思维链推理能力,但针对专业领域做了定向蒸馏和微调,使「快思考」与「慢思考」在专业场景内达到更优平衡。
网友实测显示,两种模式在任务处理上存在可感知的差异。在经典的「鹈鹕骑自行车」SVG 代码生成测试中,专家模式在图像元素融合度上完成度相对更高。在俄罗斯方块小游戏生成测试中,两者在游戏基础功能与页面布局上差异不大,均能正常运行,但专家模式在图标精细度等细节处理上表现更优。
值得注意的是,两种模式的效果差距并未如预期般显著拉大。有用户指出,专家模式与快速模式之间的表现差异相对有限,据此推测当前专家模式可能调用的是某个版本的 V4 Lite,完整版 V4 或已临近发布。
关于 DeepSeek V4 的发布传闻已持续数月。早在去年底 V3.2 版本发布后,技术社区便开始热议下一代模型的迭代方向。网络上流传的所谓 V4 详细参数显示,完整版 V4 预计将支持 1M token 的超长上下文,并在多项基准测试中表现优异。
此次专家模式上线后,有网友在直接询问时得到模型「自曝」版本为「V4」的回复,引发广泛讨论。然而,这一说法的可信度存疑。另有用户发现,专家模式的上下文长度限制约为 133K token,与传闻中完整版 V4 的 1M token 超长上下文预期不符,因此也可能是基于 V3.3 等中间版本。
目前,DeepSeek 官方尚未对专家模式背后的具体模型版本及完整版 V4 的上线时间给出任何明确说明。官方平台日志显示,当前对外公布的模型版本仍为 2025 年 12 月更新的 DeepSeek-V3.2。
![]()
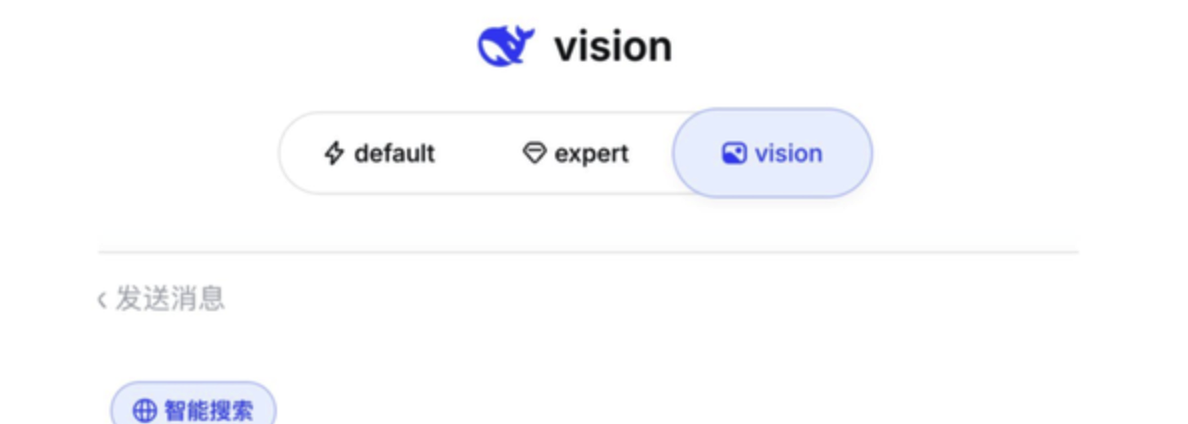
除双模式更新外,DeepSeek 的「视觉模型」功能也已开启灰度测试。该功能在界面中显示为图片图标,预示着 DeepSeek 正在加速布局多模态能力。这一动作与当前大模型行业向多模态融合发展的趋势相契合。
DeepSeek 此次产品更新,无论是否意味着 V4 模型即将落地,都表明其技术迭代正在稳步推进。从快速模式到专家模式的分层设计,体现了 DeepSeek 在用户体验与模型能力之间寻求更精细化平衡的产品思路。随着视觉模型进入灰度测试,DeepSeek 的全模态能力布局也逐渐浮出水面。