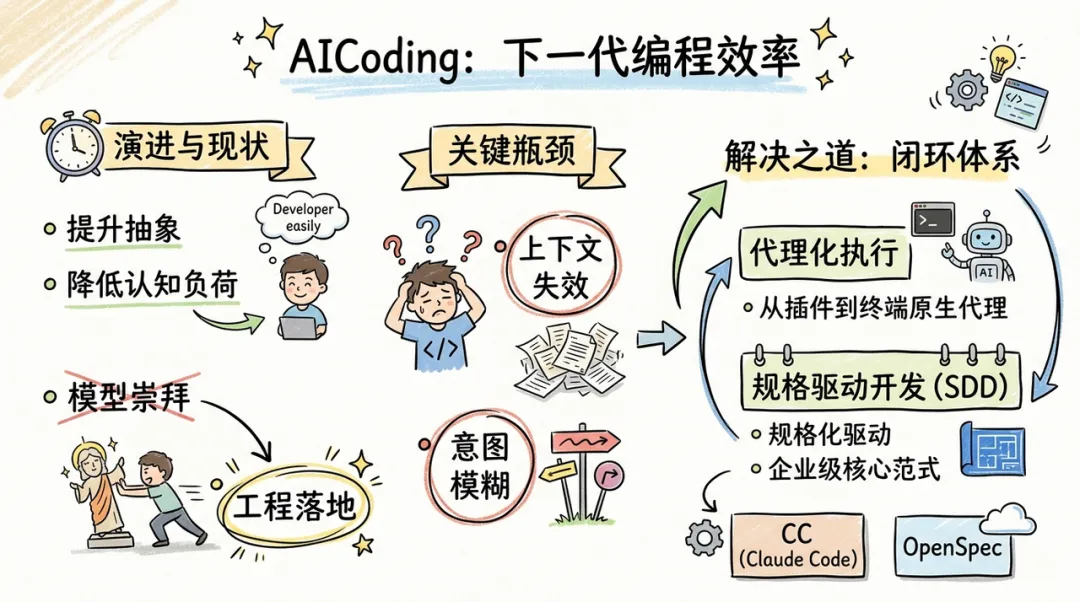
在软件开发的历史进程中,每一次效率的飞跃都伴随着抽象层次的提升。从汇编语言到高级语言,从手动内存管理到垃圾回收,开发者始终在寻求降低认知负荷的方法。进入 2026 年,生成式人工智能(GenAI)已成为编程领域不可或缺的力量。然而,行业正经历从 "模型崇拜" 向 "工程落地" 的深刻转型,单纯依靠增加大语言模型(LLM)的参数规模已无法解决复杂业务逻辑中的幻觉与失控问题。
当前的共识是,AI 编码(AICoding)的真正瓶颈不在于模型的逻辑能力,而在于上下文管理(Context Management)的失效与开发意图(Intent)的模糊。
通过对 Anthropic 推出的 Claude Code(以下简称 CC)与 Fission AI 倡导的 OpenSpec 进行深度解构可以发现,两者正在通过 "代理化执行" 与 "规格化驱动" 双轮驱动,构建一套闭环的 AI 研发体系。这种结合不仅标志着 AI 编程工具从 IDE 插件向终端原生代理(Agentic Tool)的转变,更预示着 "规格驱动开发"(Spec-Driven Development, SDD)将成为企业级 AICoding 落地的核心范式。
![image.png]()
一、破局:AI 编码的真正瓶颈不是模型,是上下文管理
在 AICoding 的早期阶段,开发者普遍认为只要模型足够强大,就能解决所有编程难题。然而,随着项目复杂度的增加,这种观点遭到了现实的挑战。研究表明,虽然 AI 编码助手的使用率在提升,但软件交付的稳定性却在下降。例如,Google 的 DORA 2024 报告指出,AI 采用率每增加 25%,交付稳定性反而下降 7.2%。
生产力悖论与认知负荷
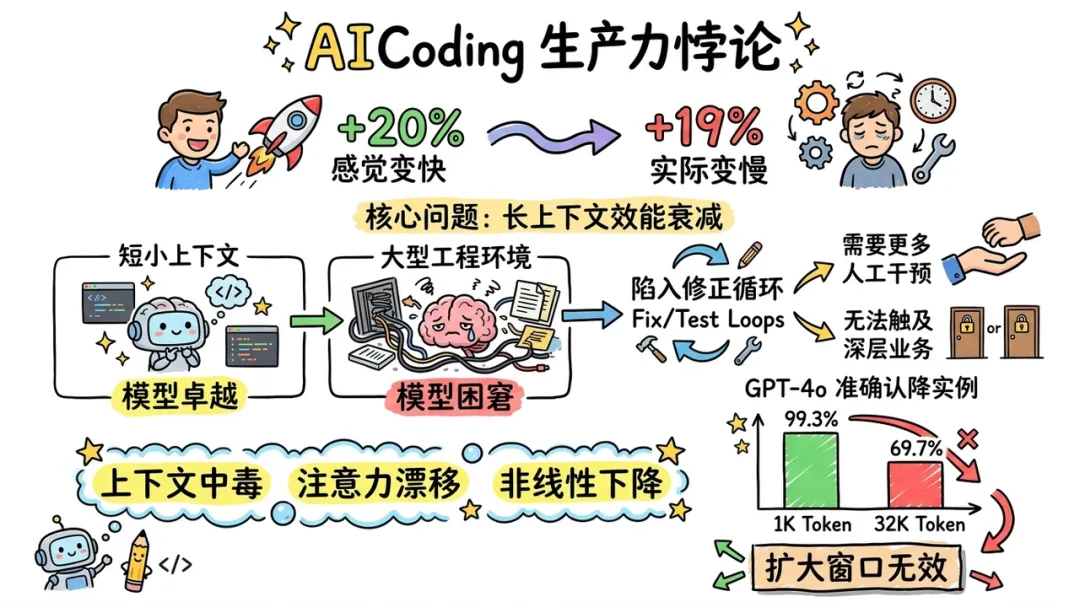
AICoding 领域存在一个显著的 "生产力悖论":开发者在使用 AI 时主观感知速度提升了 20%,但实际完成任务的时间却增加了 19%。这一现象的根源在于 AI 在处理长上下文时的效能衰减。随着任务推移,AI 往往会陷入修正循环(Fix/Test Loops),无法触及深层的业务功能,反而需要更多的人工干预。
模型的逻辑推理能力(Reasoning)在短小上下文中表现卓越,但在大型工程环境中,模型面临的是 "上下文中毒"(Context Poisoning)和 "注意力漂移"(Attention Drift)。当对话历史过长或包含过多无关代码时,模型的性能会呈现非线性下降。例如,GPT-4o 等先进模型在 1K Token 时的准确率为 99.3%,而当上下文扩展到 32K Token 时,准确率会暴跌至 69.7%。这种 "性能断崖" 意味着,单纯依靠扩大上下文窗口(Context Window)并不能解决问题。
![image.png]()
上下文工程的兴起
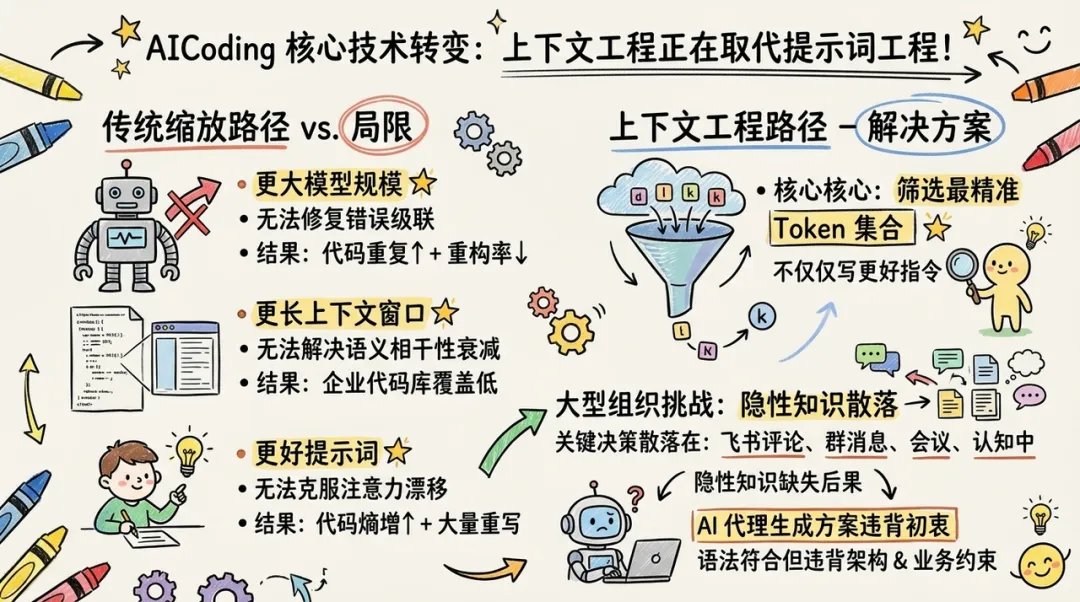
上下文工程(Context Engineering)正在取代提示词工程(Prompt Engineering),成为 AICoding 的核心技术方案。上下文工程的核心不在于 "如何写更好的指令",而在于 "如何为模型筛选最精准的 Token 集合"。
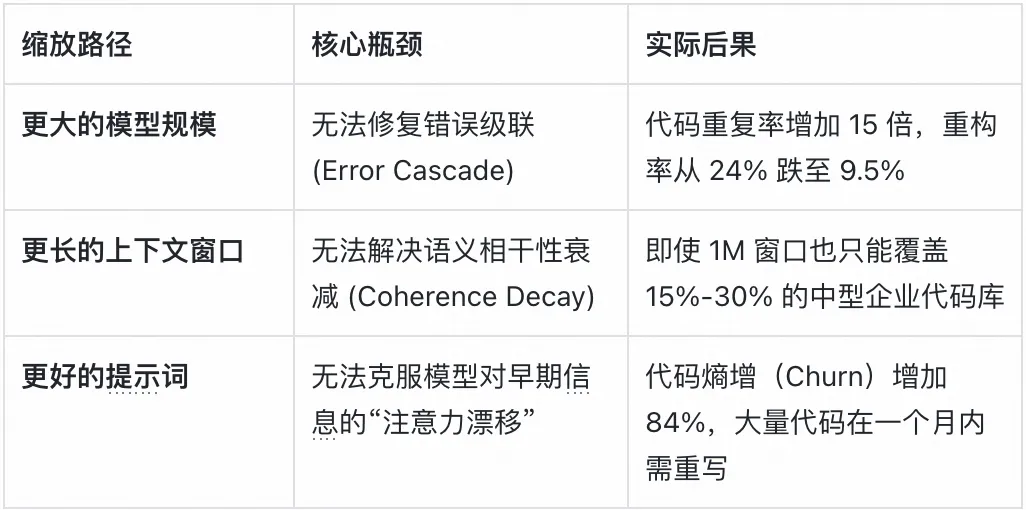
下表对比了传统缩放路径与上下文工程路径的局限性:
![image.png]()
在大型组织中,上下文管理面临更严峻的挑战。很多关键决策并未记录在代码中,而是散落在飞书文档评论、群消息、会议或开发者的认知中。AI 代理在缺乏这些隐性知识(Implicit Knowledge)的情况下,生成的方案虽然符合语法,但却违背了架构初衷或业务约束。
![image.png]()
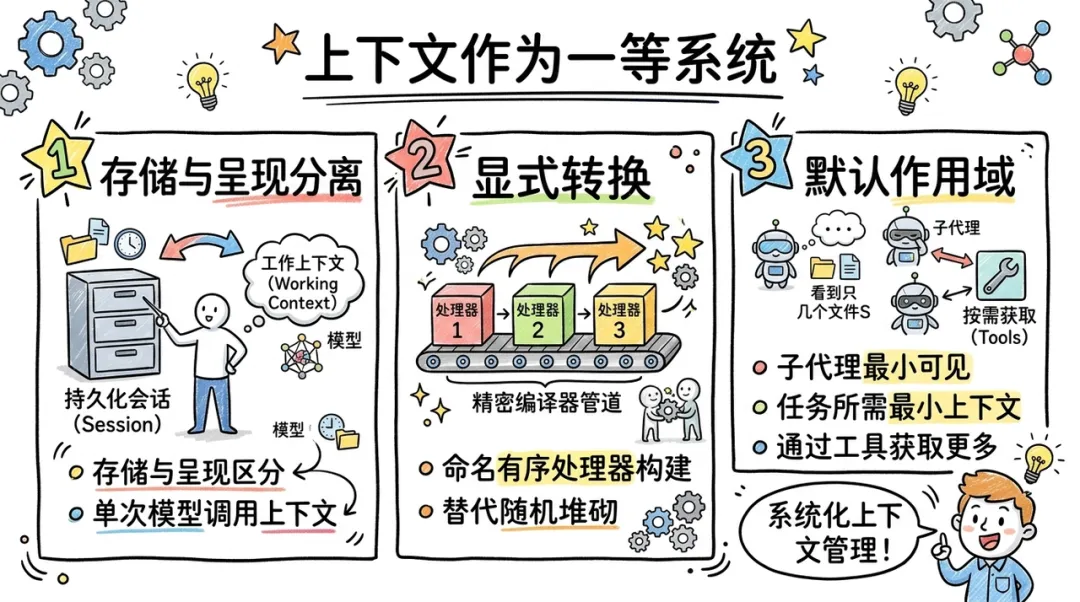
上下文作为一等系统
现代 AI 代理架构开始将上下文视为一种具有自身架构、生命周期和约束的 "一等系统"。在这种视角下,上下文管理不再是临时的字符串拼接,而是一条精密的 "编译器管道":
- 存储与呈现分离:区分持久化的会话状态(Session)与单次模型调用的工作上下文(Working Context)。
- 显式转换:通过命名的、有序的处理器(Processors)构建上下文,而非随机堆砌。
- 默认作用域:每个子代理仅能看到执行任务所需的最小上下文,通过工具(Tools)按需获取更多信息。
![image.png]()
二、Claude Code:把 AI 变成真正懂你项目的编码伙伴
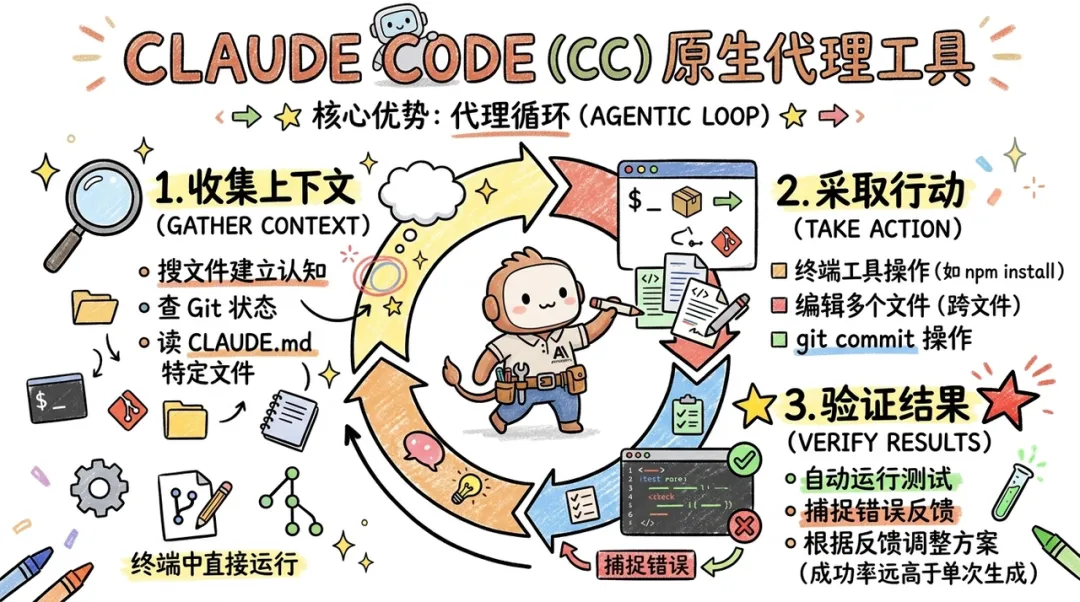
Claude Code (CC) 是 Anthropic 推出的原生代理工具,它直接运行在终端中,具备读取文件、运行命令、执行重构以及自主验证的能力。与传统的 IDE 插件相比,CC 的核心优势在于其"代理循环"(Agentic Loop)和对上下文协议的深度掌控。
代理循环:收集、行动与验证
CC 的工作流程被定义为一个闭环系统,旨在模仿人类工程师的思维过程:
- Gather Context(收集上下文):CC 不会盲目读取整个目录,而是通过文件搜索、Git 状态检查以及读取特定的 CLAUDE.md 文件来建立认知。
- Take Action(采取行动):基于推理,CC 可以跨多个文件执行编辑,或者利用终端工具(如 npm install、git commit)操作环境。
- Verify Results(验证结果):这是 CC 最具杀伤力的特性。它能自动运行测试、捕捉错误,并根据反馈调整方案。研究表明,带有验证步骤的 Coding 生成过程,其成功率远高于单次生成。
![image.png]()
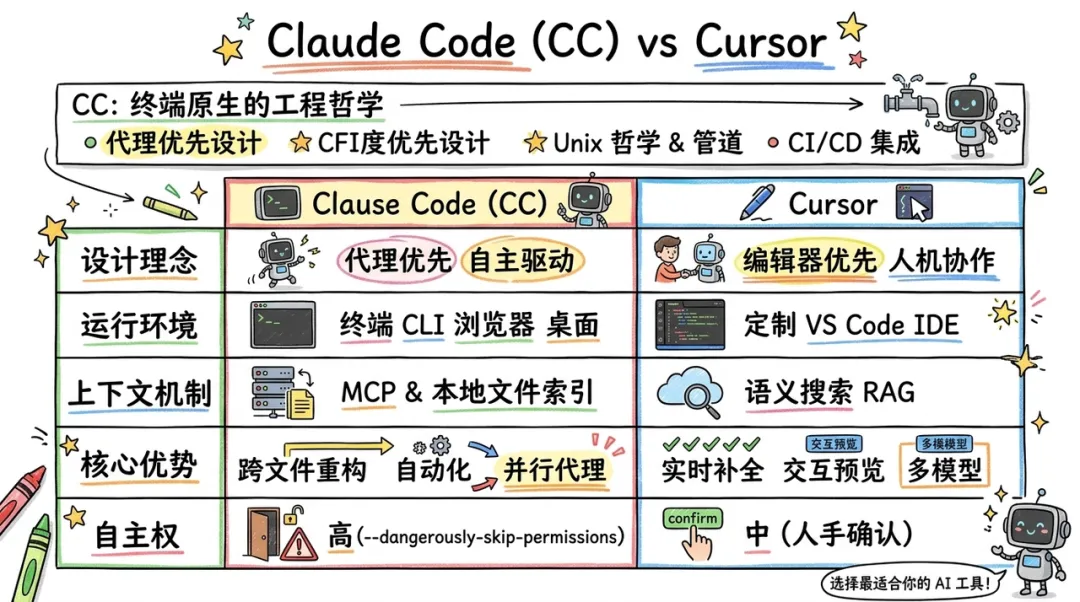
终端原生的工程哲学
CC 选择了终端而非图形界面作为主场,这体现了其 "代理优先" 的设计哲学。CC 遵循 Unix 哲学,支持管道(Pipe)、脚本化和自动化集成。这种设计使得 CC 能够与现有的 CI/CD 流程完美衔接,例如在 GitHub Actions 中自动执行代码审计。Anthropic 最新推出的 Code Review 功能,就是通过 Claude Code 基于 PR 的方式进行 bug 的追踪。
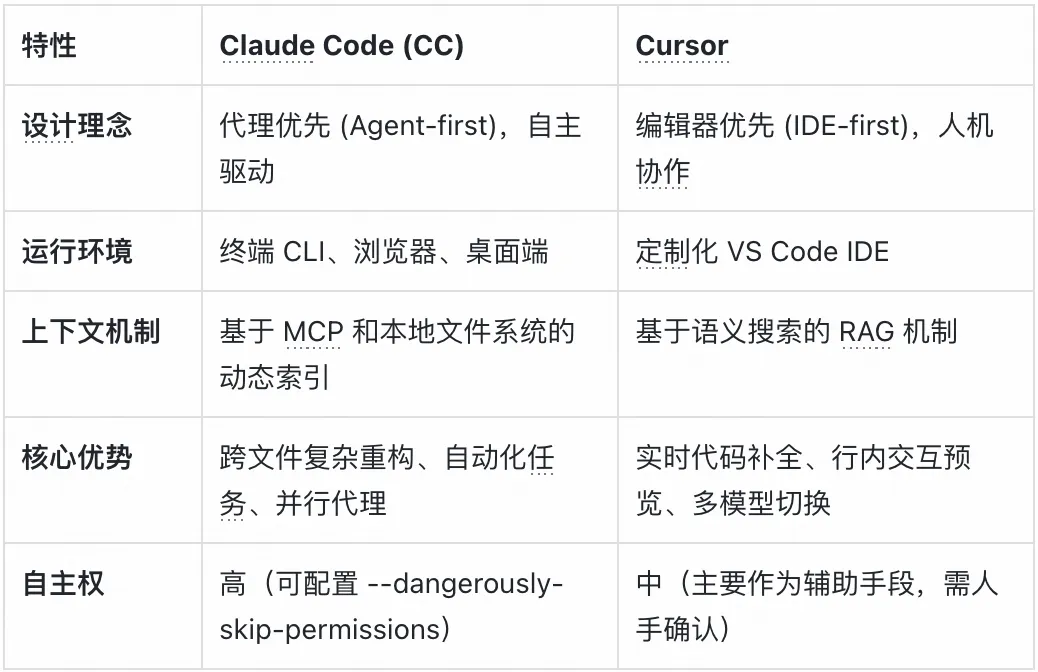
下表详细对比了 CC 与行业领先的 AI 编辑器 Cursor 的差异:
![image.png]()
![image.png]()
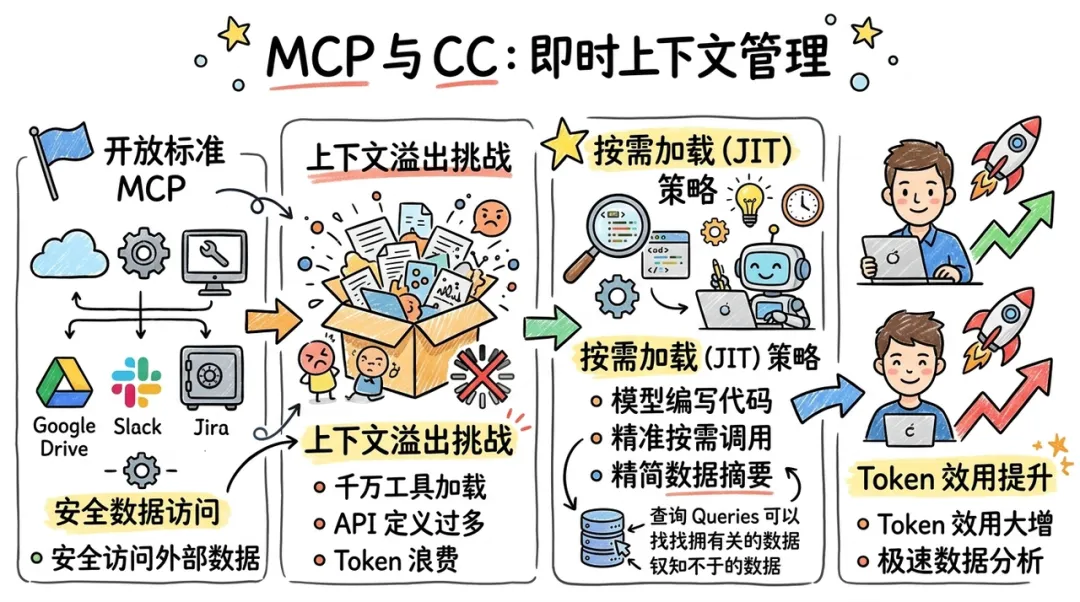
MCP 与"即时上下文"
CC 深度整合了模型上下文协议(Model Context Protocol, MCP)。MCP 是一个开放标准,允许 AI 代理安全地访问外部数据源。
为了应对大规模工具定义导致的上下文溢出,CC 引入了 "工具搜索" 和 "代码执行" 模式。代理不再一次性加载成千上万个 API 定义,而是通过编写代码按需调用 MCP 服务。例如,在分析大型数据库时,CC 不会加载全量数据,而是编写针对性的查询语句,仅将结果摘要读入上下文。这种 "按需加载" 策略极大地提升了 Token 的效用。
![image.png]()
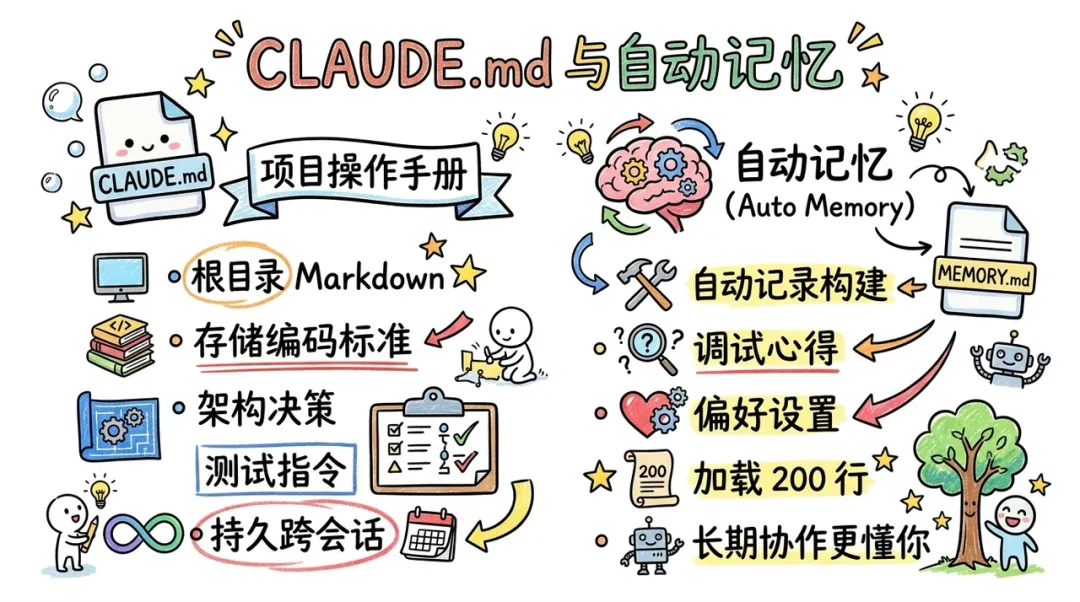
CLAUDE.md 与自动记忆
CC 引入了 CLAUDE.md 文件作为项目的 "操作手册"。这是一个置于根目录的 Markdown 文件,用于存储项目特定的编码标准、架构决策和测试指令。与临时提示词不同,CLAUDE.md 提供了持久的、跨会话的约束。
此外,CC 具备 "自动记忆"(Auto Memory)功能。它会自动在 MEMORY.md 中记录项目的构建命令、调试心得和用户的偏好设置。每当新会话启动时,CC 会加载这些记忆的前 200 行,从而确保 AI 在长期协作中能够 "越用越懂你"。
![image.png]()
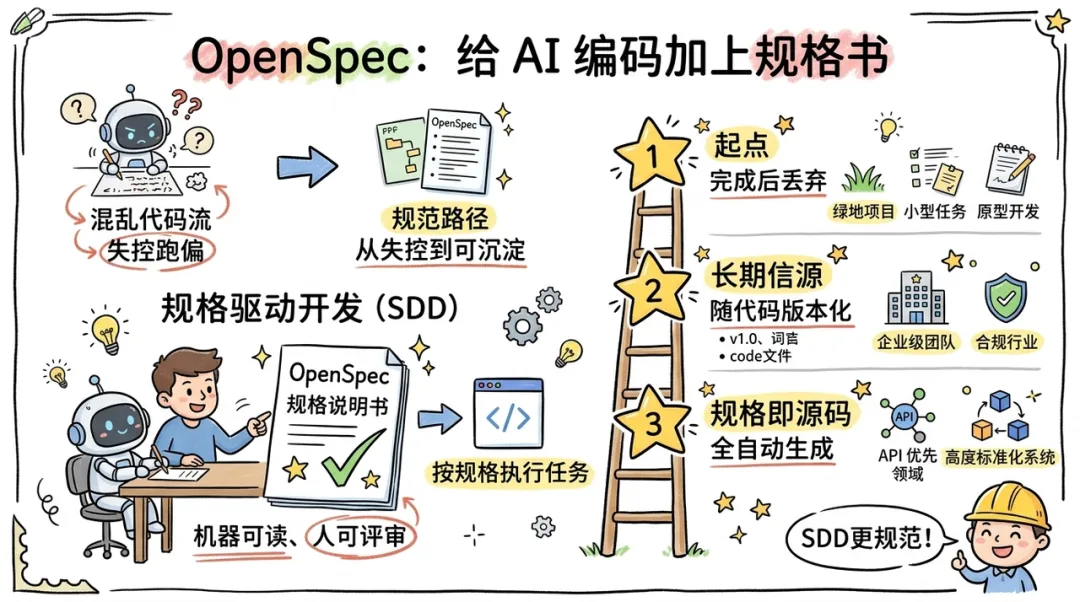
三、OpenSpec:给 AI 编码加上"规格书",从失控到可沉淀
虽然 Claude Code 提供了强大的执行引擎,但在复杂业务中,AI 仍然可能因为意图不明而跑偏,最终导致交付的代码不符合预期。
OpenSpec 的出现为 AI 编码提供了 "规格说明书",将 AICoding 从 "凭感觉写代码" 提升到了 "按规格执行任务" 的高度。
规格驱动开发 (SDD) 的兴起
OpenSpec 倡导的是一种 "规格驱动开发"(Spec-Driven Development)范式。其核心理念是:在写任何一行代码之前,先由人类与 AI 共同协商并锁定一份机器可读、人可评审的规格文档。
下表展示了 SDD 的三个演进阶段:
![image.png]()
![image.png]()
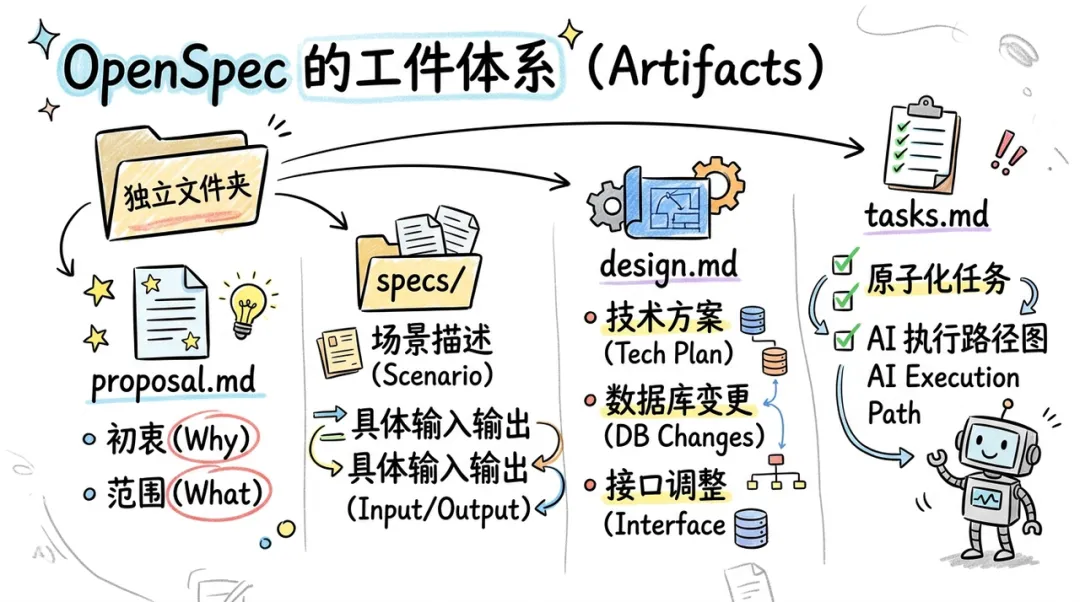
OpenSpec 的工件体系 (Artifacts)
OpenSpec 弃用了笨重的开发文档,转而采用一套轻量级的、面向 AI 优化的 Markdown 工件体系。每个变更(Change)都被组织在独立的文件夹中:
- proposal.md:描述变更的初衷(Why)和范围(What)。
- specs/:具体的逻辑规格,通常包含 "Scenario(场景)" 描述,通过具体的输入输出消除模糊性。
- design.md:技术设计方案,包括本次变更涉及的数据库变更、接口调整等。
- tasks.md:原子化的任务清单,作为 AI 的执行路径图。
![image.png]()
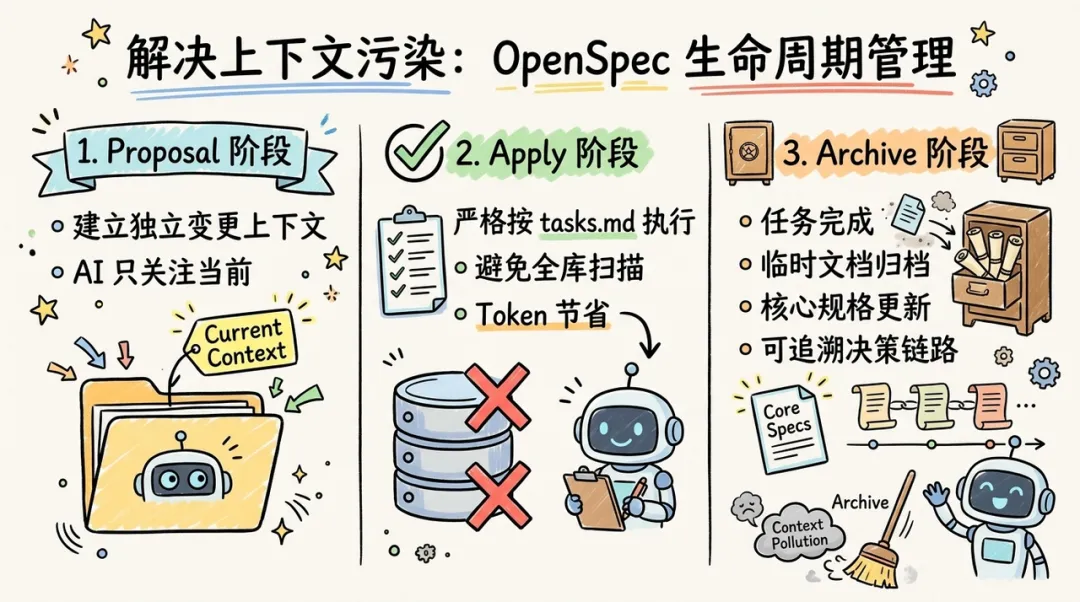
解决上下文污染:提案、应用与归档
OpenSpec 最具洞察力的设计在于其生命周期管理。AI 在处理新任务时,最忌讳被旧任务的陈旧信息干扰。OpenSpec 的 "归档(Archive)" 机制解决了这一问题:
- Proposal 阶段:建立一个独立的变更上下文,让 AI 只关注当前变更。
- Apply 阶段:AI 严格按照 tasks.md 执行,避免了盲目扫描全库导致的 Token 浪费。
- Archive 阶段:任务完成后,临时变更文档被移入归档,核心规格更新至主规格文件。这保证了 AI 始终在一个 "卫生" 的上下文环境下工作,同时也为项目留下了可追溯的决策链路。
![image.png]()
四 、实战:CC + OpenSpec 如何落地真实业务
在实际的企业业务场景中,如何整合这两大工具?答案在于将 OpenSpec 的标准化指令集注入到 Claude Code 的会话环境中。
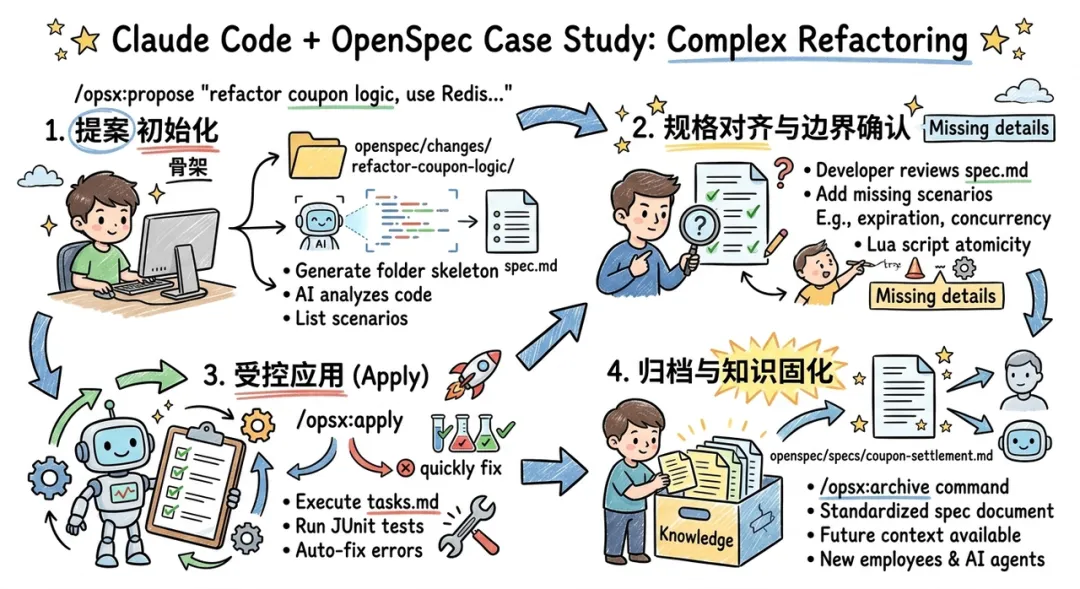
案例实战:复杂业务逻辑的重构
假设一个电商项目需要重构其优惠券结算逻辑。在传统的 AI 辅助下,AI 可能会在修改 CouponService.java 时遗漏分布式锁,或者破坏原有的满减叠加规则。采用 CC + OpenSpec 模式,流程如下:
第一步:提案初始化
执行 /opsx:propose "重构优惠券结算逻辑,引入 Redis 分布式锁并支持多卷叠加"。CC 会在 openspec/changes/refactor-coupon-logic/ 下生成整套骨架。AI 会通过分析现有代码,在 spec.md 中自动列出已知的结算场景。
第二步:规格对齐与边界确认
这时不用急着让 AI 写代码,而是需要先审阅 spec.md。如果发现 AI 没考虑 "优惠券过期临界点" 的并发问题,可以直接要求 AI 修改规格:"在 spec.md 中增加过期校验场景,并要求使用 Lua 脚本保证原子性"。
第三步:受控应用(Apply)
一旦规格通过人工评审,就可以执行 /opsx:apply 了。这时,CC 就变成了完美的执行机器。它不再 "猜" 开发者的意图,而是对照 tasks.md 逐项实施。每一项修改后,它都会运行相关的测试。如果测试失败,CC 会自动分析错误并重新修复,直到该项 Task 标为 "完成"。
第四步、归档与知识固化
任务结束后,执行 /opsx:archive。原本散落在会话记录中的重构逻辑,现在变成了 openspec/specs/coupon-settlement.md 中的标准规格。当下一次另一个 AI 代理(或新入职同事)需要修改此模块时,它只需读取这份规格,即可获得完整的业务语境。
![image.png]()
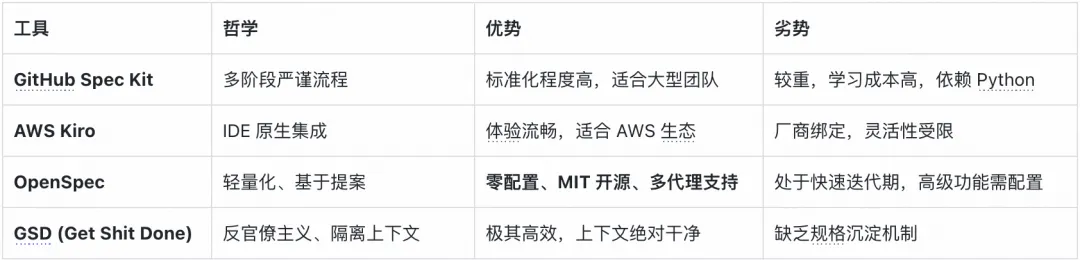
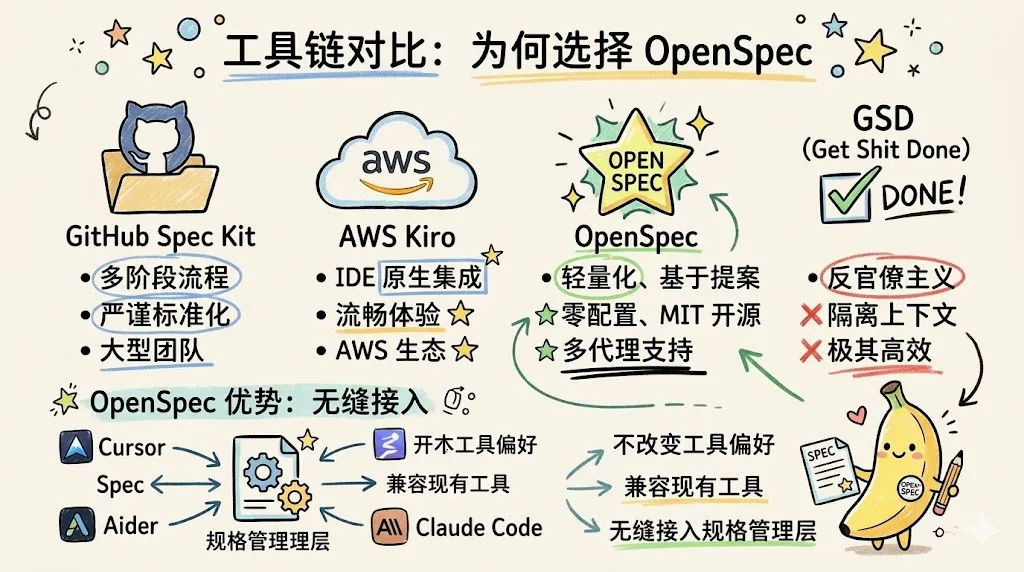
工具链对比:为何选择 OpenSpec
在 SDD 工具链中,OpenSpec 展现出了极高的工程性价比:
![image.png]()
OpenSpec 的优势在于它不试图改变开发者的工具偏好。无论是使用 Claude Code、Cursor 还是 Aider,都可以无缝接入 OpenSpec 的规格管理层。
![image.png]()
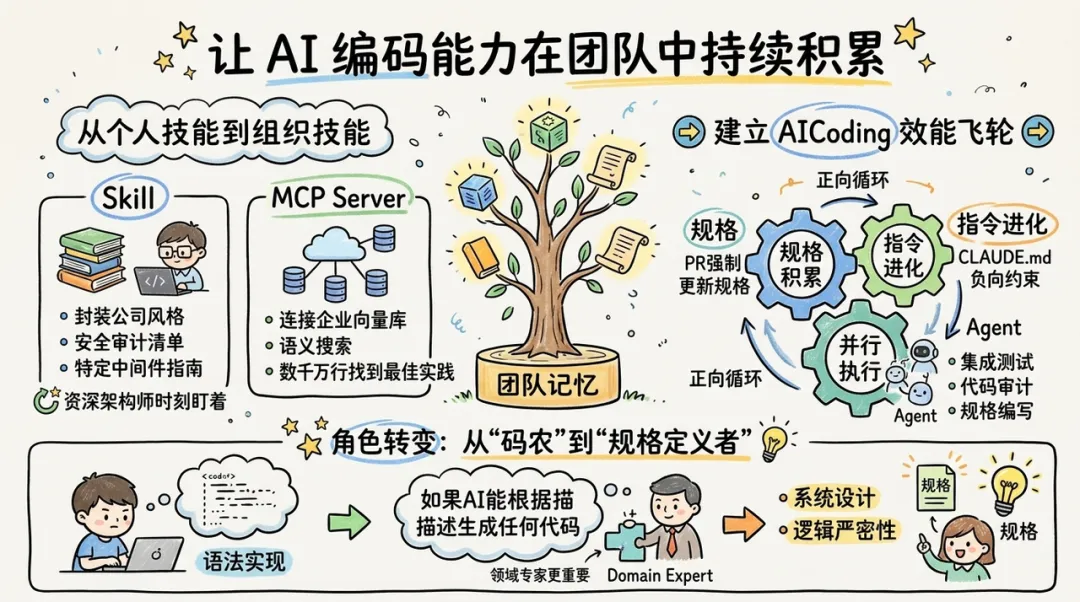
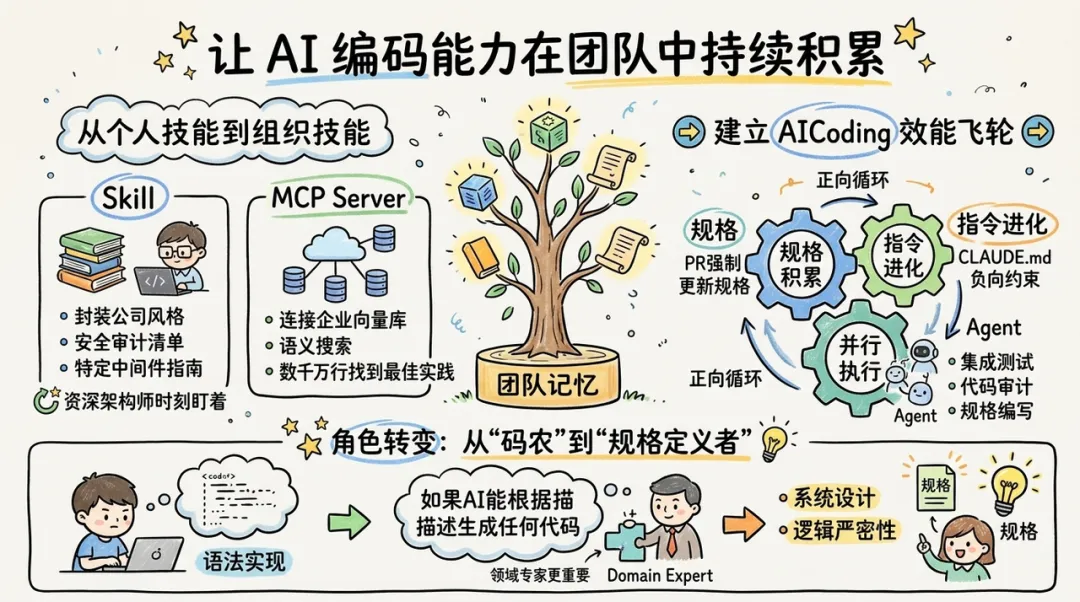
五、沉淀:让 AI 编码能力在团队中持续积累
AICoding 落地的终极目标不是让个体开发者写得更快,而是提升整个团队的知识资产质量。AI 编码能力不应随对话窗口的关闭而消失,而应作为 "团队记忆" 沉淀下来。
从个人技能到组织技能
团队可以通过自定义 Skill 和 MCP Server 来固化组织资产。
- Skill:将公司特有的代码风格、安全审计清单,或者特定中间件的使用指南封装为 .claude/skills/。当团队成员使用 CC 时,AI 会自动加载这些技能,仿佛有一位资深架构师在时刻盯着每一行代码。
- MCP Server:连接企业内部的向量数据库(如基于 Zilliz 的语义搜索),让 AI 代理能够从数千万行历史代码中找到最佳实践。
建立 AICoding 效能飞轮
AICoding 的成功落地需要建立一套正向循环的 "飞轮":
- 规格积累:每完成一个 PR,都强制更新对应的 OpenSpec 规格文件。
- 指令进化:发现 AI 反复犯的错,就将其转化为 CLAUDE.md 中的负向约束(Prohibited rules)。
- 并行执行:利用 CC 的 Agent Teams 能力,让一个代理负责写规格,另一个代理负责审计代码,第三个代理负责集成测试。
![image.png]()
角色转变:从 "码农" 到 "规格定义者"
在 CC + OpenSpec 模式下,软件工程师的角色正在发生质变。如果 AI 能够根据完美的描述生成任何代码,那么 "代码" 本身就变成了编译后的中间产物,而 "规格" 才是核心产品。领域专家(Domain Experts)的重要性显著提升,因为他们能提供最高质量的业务意图描述。这种趋势将迫使开发者从关注 "语法实现" 转向关注 "系统设计" 和 "逻辑严密性"。
![image.png]()
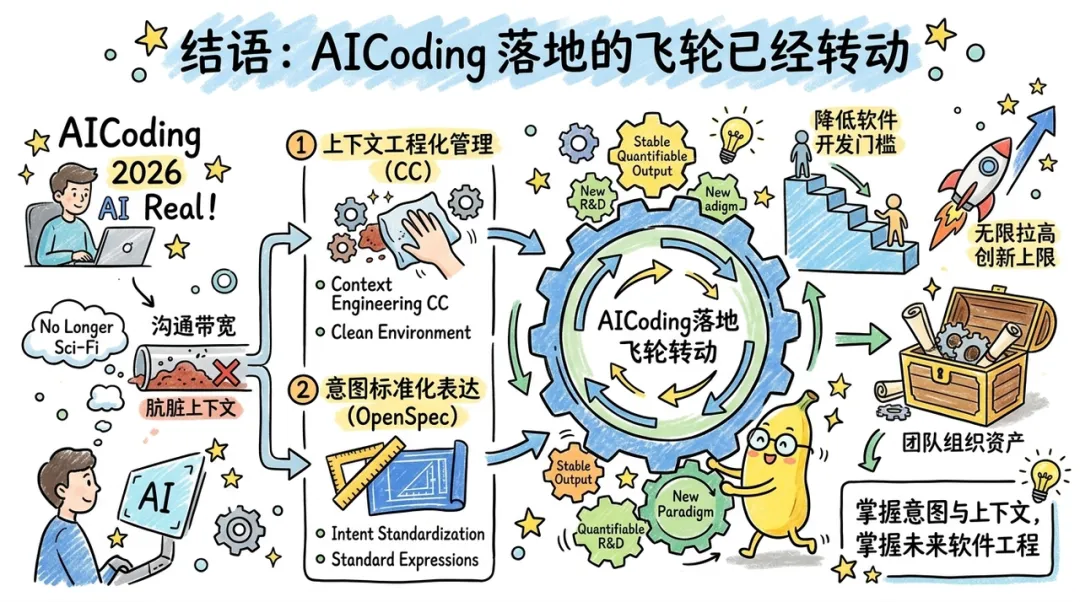
六、结语:AICoding 落地的飞轮正在转动
在 2026 年,AICoding 已不再是科幻。Claude Code 提供的强大代理能力,配合 OpenSpec 提供的精密规格框架,为企业提供了一套可复制、可量化的研发新范式。
我们必须承认,AI 编码的瓶颈从来不是模型不够聪明,而是我们与 AI 之间的 "沟通带宽" 太低且 "上下文" 太脏。通过上下文工程化管理(CC)和意图标准化表达(OpenSpec),我们正在构建一套让 AI 能够长期、稳定产出的工程环境。
随着这一模式的普及,软件开发的门槛将进一步降低,而创新的上限将被无限拉高。AICoding 落地的飞轮已经转动,那些能够率先将 AI 编码能力转化为团队组织资产的企业,将在未来的数字化竞争中占据绝对的先机。毕竟,在 AI 时代,掌握了 "意图" 与 "上下文" 的人,才掌握了软件工程的未来。
![image.png]()
参考文档:
- https://thenewstack.io/context-is-ai-codings-real-bottleneck-in-2026/
- https://github.blog/ai-and-ml/generative-ai/spec-driven-development-with-ai-get-started-with-a-new-open-source-toolkit/
- https://solguruz.com/blog/spec-driven-development-guide/
- https://medium.com/@eran.swears/why-bigger-models-wont-code-better-7e8761ebeb16
- https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
- https://code.claude.com/docs/en/how-claude-code-works
- https://www.anthropic.com/engineering/code-execution-with-mcp
- https://code.claude.com/docs/en/best-practices
- https://dev.to/webdeveloperhyper/how-to-make-ai-follow-your-instructions-more-for-free-openspec-2c85
往期回顾
1.大禹平台:流批一体离线Dump平台的设计与应用|得物技术
2.基于 Cursor Agent 的流水线 AI CR 实践|得物技术
3.从IDE到Terminal:适合后端宝宝体质的Claude Code工作流|得物技术
4.AI编程能力边界探索:基于 Claude Code 的 Spec Coding 项目实战|得物技术
5.搜索 C++ 引擎回归能力建设:从自测到工程化准出|得物技术
文 /后羿
关注得物技术,每周更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。