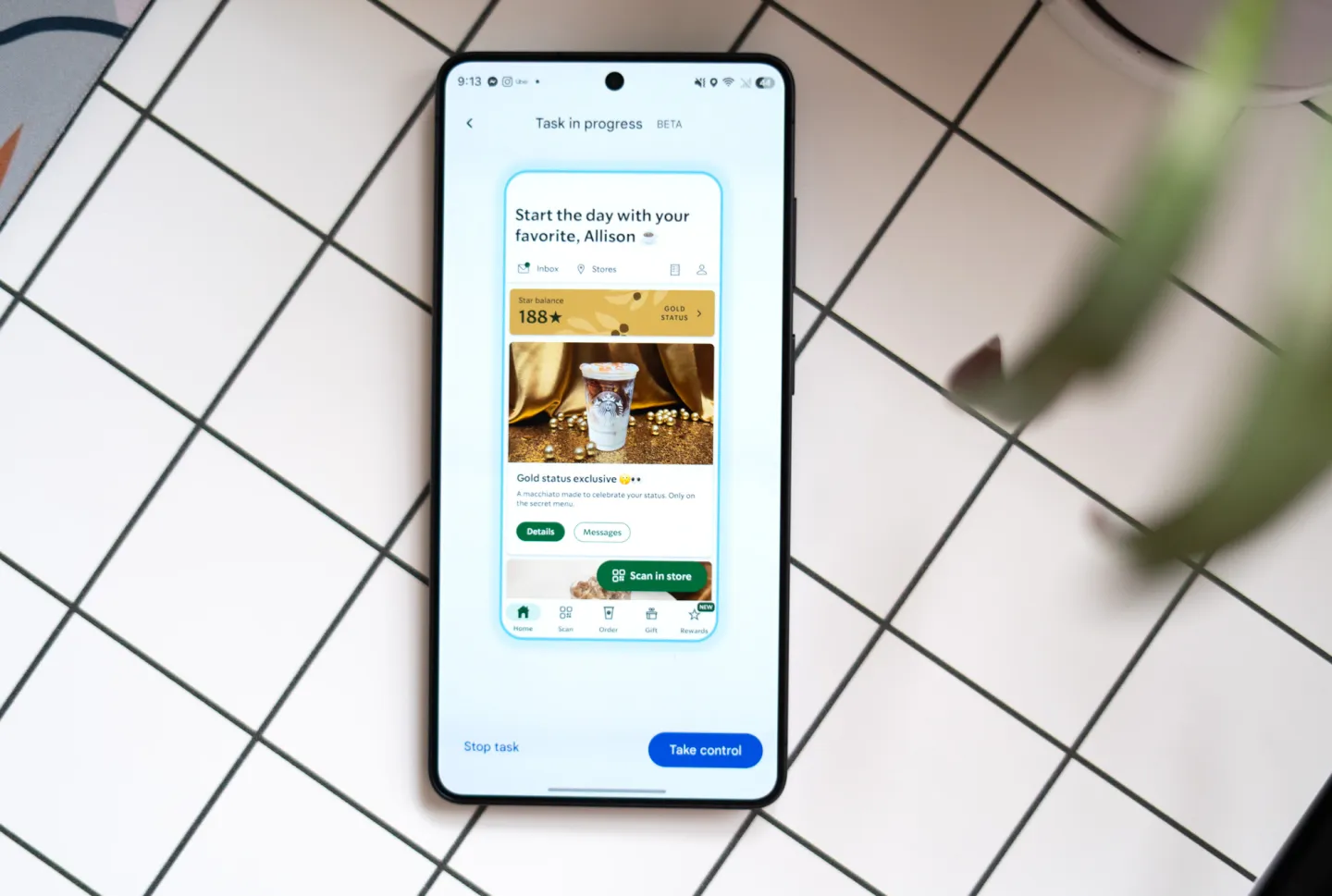
谷歌近日正式在Pixel 10 Pro和Galaxy S26 Ultra上推出了Gemini的任务自动化功能(Task Automation),这是目前主流AI助手中首个能够真正接管手机、替用户完成复杂多步骤操作的功能。虽然当前仅支持Uber、DoorDash等少数几款外卖和打车应用,且仍处于测试阶段,但这一功能的亮相被业界视为AI助手从"对话工具"向"执行代理"进化的重要里程碑。
过去十年间,Siri、Google Assistant、小爱同学等语音助手已经能够回答天气、设置闹钟、播放音乐,但始终停留在"信息查询"和"简单指令"层面。用户想要叫车或订餐,仍然需要亲手打开应用、填写信息、确认支付。Gemini任务自动化的核心突破在于,它首次让AI能够在后台独立完成整套操作流程:理解用户需求、打开第三方应用、填写表单、选择选项、确认订单——用户只需用自然语言描述需求,剩下的全部交给AI。
根据实测体验,Gemini在执行任务时会实时显示操作进度,在屏幕底部以文字形式告知当前正在进行的步骤,例如"正在打开Uber""正在选择目的地""正在选择车型"等。整个过程用户可以全程旁观,也可以切换去做其他事情,Gemini会在后台持续运行直至任务完成。
![]()
The Verge编辑Allison Johnson在测试中描述了一个典型案例:用Gemini点一份DoorDash外卖,全程耗时约九分钟。这个数字对于熟练手机用户而言显然过于漫长——手动操作可能只需两分钟。速度瓶颈主要来自AI需要逐帧识别界面元素、理解内容、做出决策,每一步都涉及大量的云端推理和本地计算。
然而,速度并非这项功能的唯一衡量标准。谷歌的设计初衷是让Gemini在后台异步运行,用户无需守候在屏幕前。你可以一边让AI帮你订餐,一边整理行李、回复邮件或做任何其他事情。这种"委托执行"的模式打破了传统人机交互的即时性约束,开创了"发令-等待结果"的全新交互范式。
目前Gemini任务自动化仅支持少量应用,主要是Uber、DoorDash等结构相对规范、流程相对标准化的服务。这反映出当前AI在复杂UI理解和长链条任务规划上的技术局限:界面元素识别错误、支付环节安全限制、异常流程处理等问题仍是待解难题。
更深层次的技术挑战在于跨应用协作和上下文理解。现实生活中的任务往往涉及多个应用协同——比如先查地图确定餐厅位置,再打开点评应用看评分,最后在打车应用中叫车。这类跨应用、多步骤的复杂任务对AI的规划能力和容错能力提出了更高要求。
Gemini任务自动化的推出,正值全球科技巨头竞相布局"AI Agent"(AI智能体)赛道之际。OpenAI的Operator、Anthropic的Computer Use、苹果的Apple Intelligence均在不同程度上探索让AI从"说"到"做"的跨越。不同的是,谷歌选择从移动端切入,依托Android生态的海量设备和Gemini的深度系统集成,试图率先抢占用户日常高频场景。
分析人士指出,2026年将是AI Agent从概念验证走向实用化的关键一年。谁能率先解决可靠性、安全性和生态整合三大难题,谁就有可能在下一代人机交互平台的争夺中占据先机。谷歌此次推出的功能虽显稚嫩,但已经展示了AI从"助手"进化为"代理"的清晰路径。
对于普通用户而言,Gemini任务自动化代表了一种"未来已来"的体验。第一次看到自己的手机在无人触碰的情况下自动滑动、点击、填写信息,那种科幻感令人震撼。然而,当前的实用性仍然有限——支持的应用太少、执行速度太慢、失败率有待降低。这更像是谷歌向开发者和投资者展示技术实力的"概念产品",而非能够大规模替代人工操作的成熟功能。
但技术的进步往往遵循指数曲线。回想十年前,语音识别的准确率还不足80%,如今已在多数场景达到人类水平。Gemini任务自动化 today's clunky experience 很可能是 tomorrow's seamless norm 的前奏。当AI能够以接近人类的速度和准确度操作任意应用时,手机的使用方式将被彻底改写。
参考来源
- https://www.theverge.com/tech/898282/gemini-task-automation-uber-doordash-hands-on
- https://www.theverge.com/tech/884210/google-gemini-samsung-s26-pixel-10-uber