OpenAI正式发布GPT-5.4 mini与nano,据称是其迄今为止能力最强的小型模型。它们将 GPT‑5.4 的诸多优势引入到更快速、更高效的模型中,专为高吞吐量工作负载而设计。
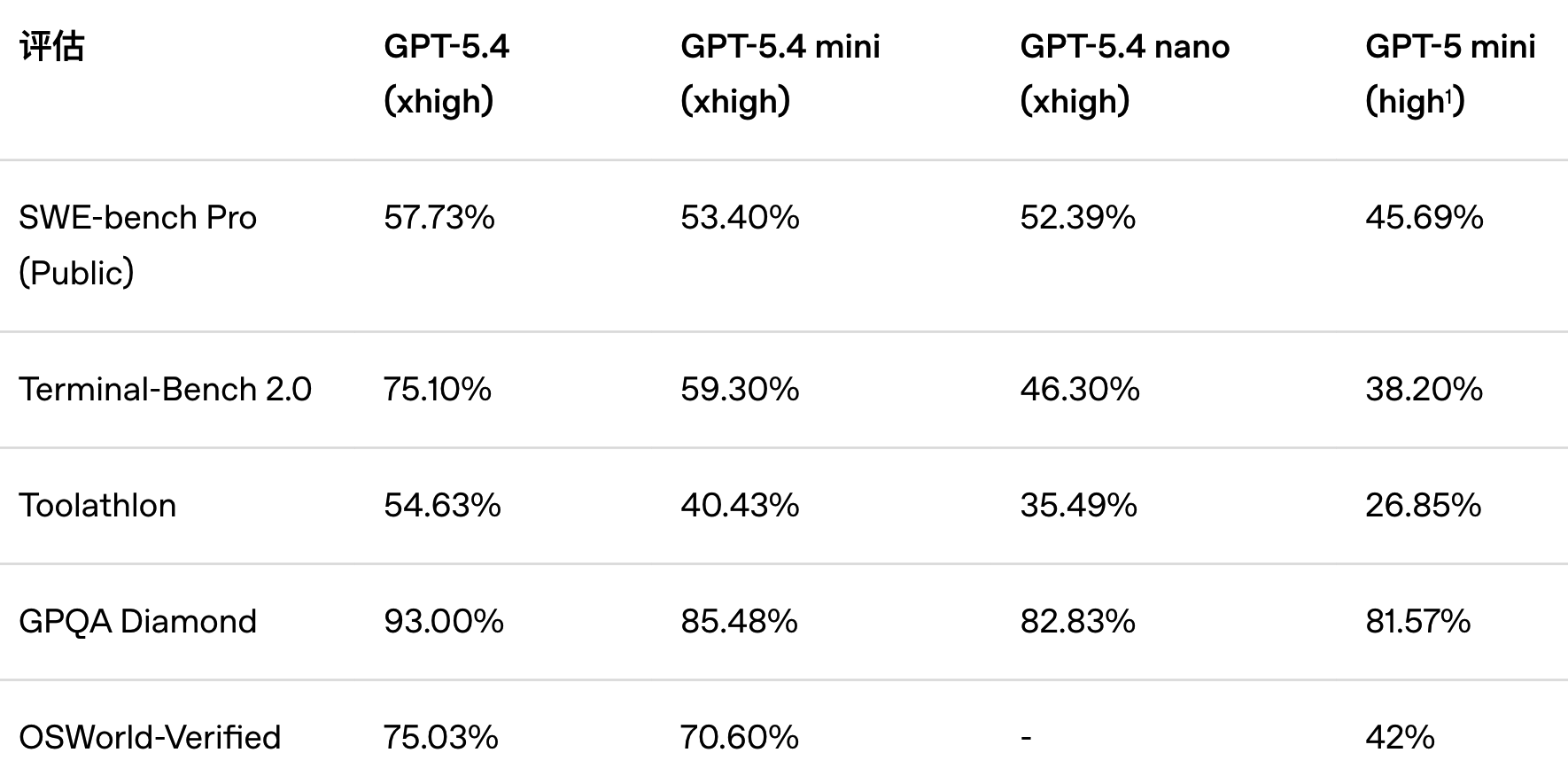
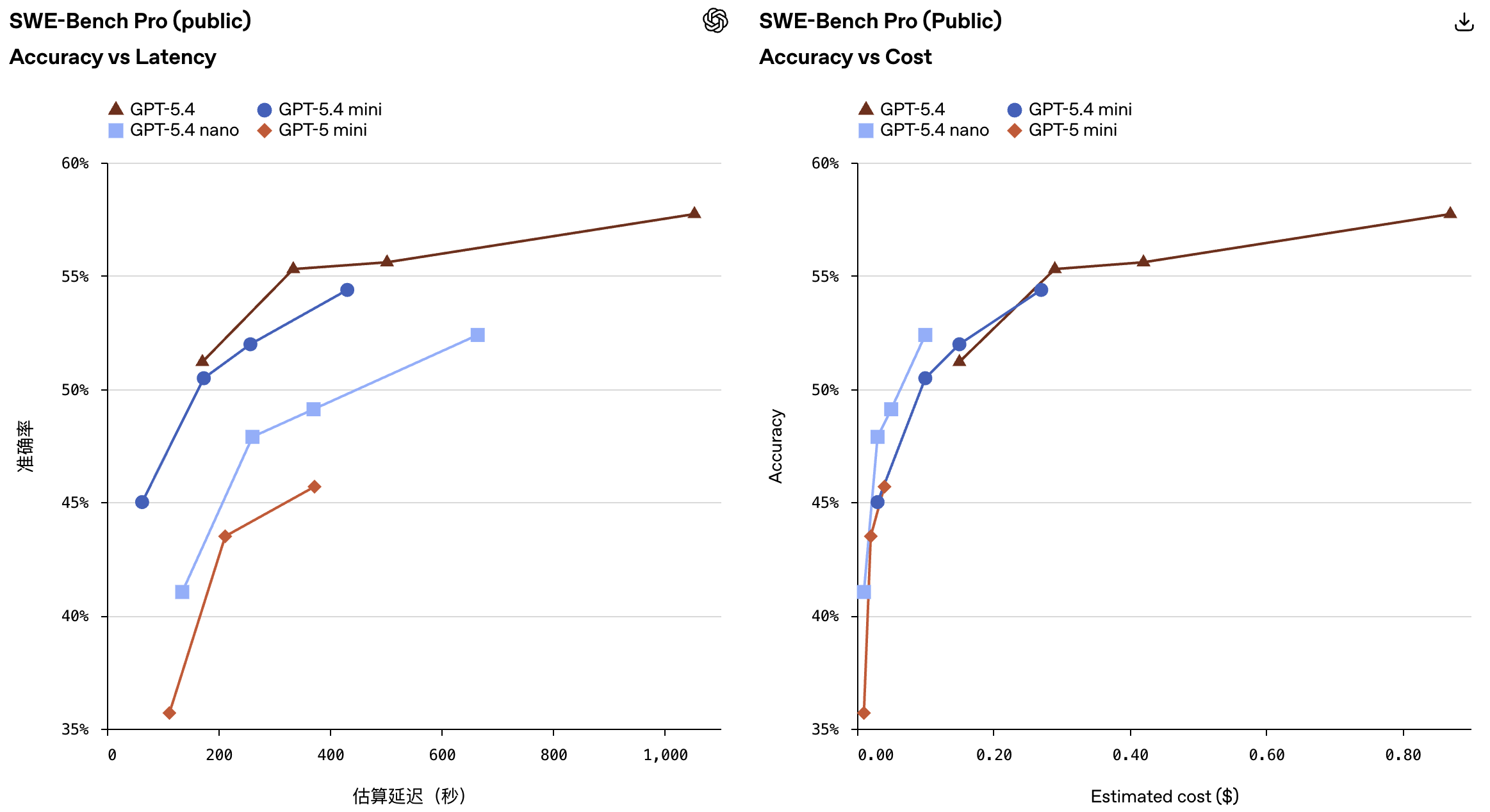
GPT‑5.4 mini 在代码编写、推理、多模态理解以及工具使用方面较 GPT‑5 mini 有显著提升,同时运行速度提高两倍以上。它在多项评估中也接近体量更大的 GPT‑5.4 模型的性能,包括 SWE-bench Pro 和 OSWorld-Verified 基准测试。
![]()
![]()
GPT‑5.4 mini 专为对延迟敏感的应用场景打造,在这类场景中,响应速度直接关系到产品体验:例如需要即时响应的代码助手、能快速完成辅助任务的子智能体、可捕捉并解析截图的计算机使用系统,以及能够实时推理图像的多模态应用。在这些设定下,最好的模型通常不是体量最大的那个,而是能够快速响应、可靠调用工具,并能在复杂专业任务中保持出色表现的模型。
GPT‑5.4 nano 是 GPT‑5.4 最轻量、最快速的版本,专为对速度和成本要求极高的任务而设计。它也是 GPT‑5 nano 的重大升级版本,推荐将其用于分类、数据提取、排序,以及处理简单辅助任务的子智能体。
GPT‑5.4 mini 现已在 API、Codex 及 ChatGPT 中上线。
在 API 中,GPT‑5.4 mini 支持文本与图像输入、工具使用、函数调用、网页搜索、文件搜索、计算机使用以及技能 (skill)。它具备 400K 上下文窗口,定价为每 100 万输入 Token 0.75 美元,每 100 万输出 Token 4.50 美元。
在 Codex 中,GPT‑5.4 mini 已在 Codex 应用、CLI(命令行界面)、IDE 扩展及网页端上线。它仅消耗 GPT‑5.4 配额的 30%,让开发者能在 Codex 中以约三分之一的成本快速处理简单的代码任务。此外,智能体也可以配置为默认使用 GPT‑5.4 mini,从而让那些处理低推理强度工作的子智能体在更经济的模型上运行。
在 ChatGPT 中,免费版与 Go 用户可以通过 “+” 菜单中的 “Thinking” 功能使用 GPT‑5.4 mini。对于所有其他用户,GPT‑5.4 mini 将作为 GPT‑5.4 Thinking 的速率限制备选方案。
GPT‑5.4 nano 仅在 API 中提供,定价为每 100 万输入 Token 0.20 美元,每 100 万输出 Token 1.25 美元。