深度求索刚刚发布最新开源模型: DeepSeek-OCR 2,引入了全新的 DeepEncoder V2 视觉编码器。该编码器的架构打破了传统模型按固定顺序(从左上到右下)扫描图像的限制,转而模仿人类视觉的「因果流(Causal Flow)」逻辑。
![]()
项目地址:https://github.com/deepseek-ai/DeepSeek-OCR-2
模型下载:https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
论文地址:https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf
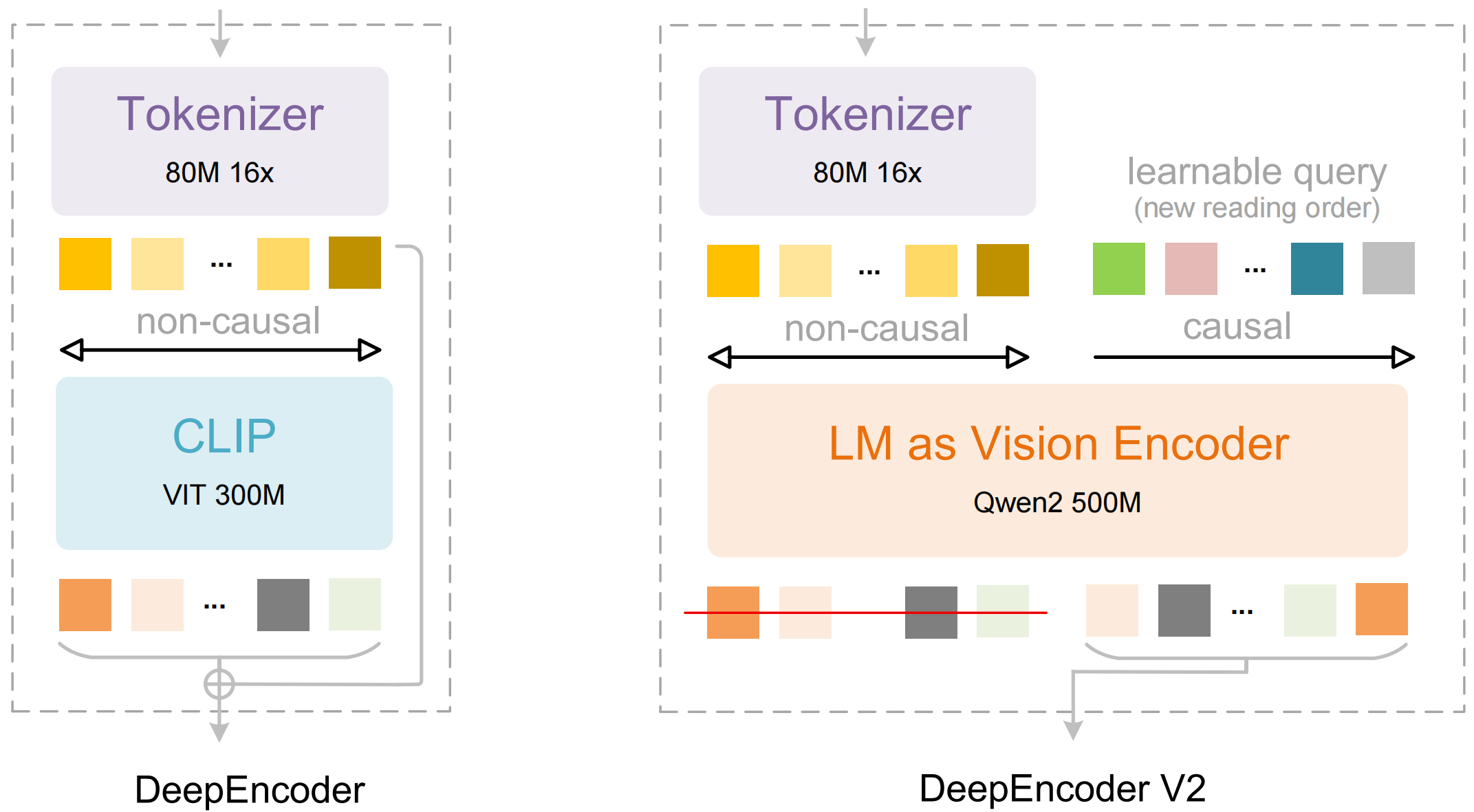
据介绍,DeepEncoder V2 让 AI 基于图像含义动态重新排列图像片段,而非传统的从左到右刚性扫描。这种方法模仿了人类追随场景逻辑流的方式。
传统的 VLMs 通常按固定的光栅扫描顺序(从左上到右下)处理图像,这种僵化的方式不符合我们的视觉感知,人类是基于内容的灵活扫描,而且在处理复杂布局,如表格、公式、多栏文本时会引入错误的信息。
而 OCR 2,就是利用新型编码器 DeepEncoder V2,给了模型「视觉因果流 Visual Causal Flow」的能力,让模型能够根据图像内容,动态地重新排序视觉 Token。
![]()
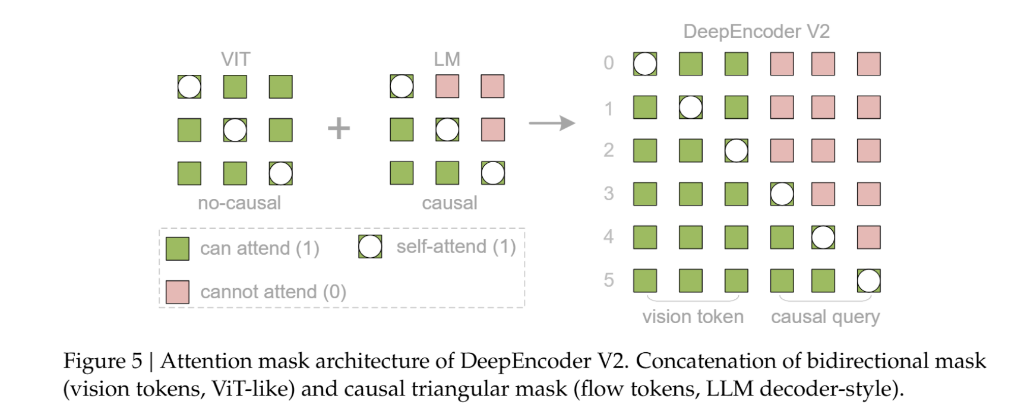
该架构采用了一种定制化的注意力掩码(Attention Mask)策略:
- 视觉 Token 部分:保留双向注意力机制,确保模型能够像CLIP一样拥有全局感受野,捕捉图像的整体特征。
- 因果流 Token 部分:采用因果注意力机制(类似 Decoder-only LLM),每个查询 Token 只能关注之前的 Token。
![]()
通过这种设计,视觉 Token 保持了信息的全局交互,而因果流 Token 则获得了重排序视觉信息的能力。DeepSeek-OCR 2 采用了多裁剪策略(Multi-crop strategy),根据图像分辨率不同,最终输入 LLM 的重排序视觉 Token 总数在 256 到 1120 之间。
DeepSeek 团队认为,这为迈向统一的全模态编码器提供了一条有希望的路径。未来,单一编码器可能通过配置特定模态的可学习查询,在同一参数空间内实现对图像、音频和文本的特征提取与压缩。DeepSeek-OCR 2所 展示的“两个级联的 1D 因果推理器”模式,通过将 2D 理解分解为“阅读逻辑推理”和“视觉任务推理”两个互补子任务,或许代表了实现真正 2D 推理的一种突破性架构方法。
相关阅读
DeepSeek 团队发布最新开源模型 DeepSeek-OCR
由 DeepSeek-OCR 启发的新思路:所有输入给 LLM 的内容都只应该是图像