OpenAI 发布技术文章系统拆解了其编程 Agent 产品 Codex CLI 背后的 “Agent loop” 核心机制,展示了 LLM Agent 如何在软件开发任务中高效协作与自我迭代。
![]()
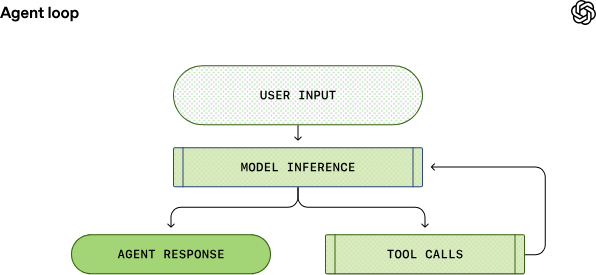
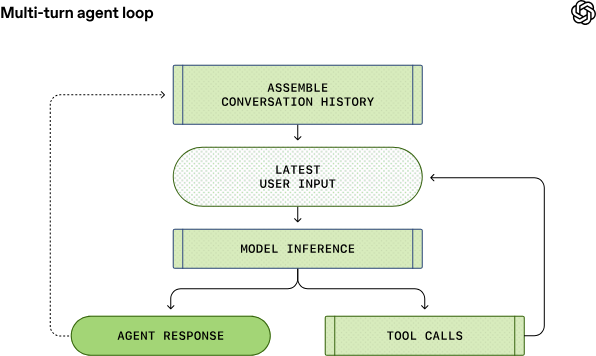
“Agent loop”是 Codex 在处理用户指令时的核心执行流程:从接收用户输入开始,Codex 不仅让大模型进行推理,还引导模型反复调用工具、执行动作、观察输出,并最终生成准确回复(或代码更改)。这一循环持续进行,直到模型返回最终结果。
关键步骤包括:
- 构建 Prompt(提示词):将用户输入和上下文信息打包成用于模型推理的指令集。
- 模型推理(Inference):将 Prompt 转换为 token 并送入模型生成输出。
- 工具调用:模型可能发出工具请求,如执行 shell 命令或访问文件系统,Agent 执行后将结果反馈给模型。
- 重复循环:根据新信息重组 Prompt,再次请求模型,直到输出终结信息交付用户。
相比传统单向对话系统,这种循环整合了推理+动作执行+反馈整合,使得 Codex 能够自主完成更复杂的编程任务,而不仅仅是生成文本回复。
![]()
面向 Responses API 的构建方式
Codex CLI 借助 Responses API 与 LLM 通信,其支持多种部署环境:
- 使用 ChatGPT 登录:通过 ChatGPT 后端 API 接入。
- API key 认证:调用标准 OpenAI Responses API。
- 本地 open-source 模型:支持如 ollama、LM Studio 的本地服务。
这种可配置性让开发者可以在本地部署、云端托管或混合架构中运行 Codex,实现更灵活的开发集成。
Prompt 构建细节与角色分层
OpenAI 详细解释了 Prompt 的组成与权重机制:
- system / developer / user / assistant 角色区分不同来源与优先级的信息。
- 系统自动注入权限、安全沙箱规范、开发者指令等多层内容。
- 环境信息(如当前工作目录、shell 类型)也被编码进 Prompt。
这些细节有助于精细控制 Agent 行为、规范权限边界,并提升模型调用的可靠性。
性能与上下文管理
随着对话或任务执行的循环次数增长,Prompt 会不断膨胀。OpenAI 指出:
- Prompt 缓存能显著提升性能,但仅在完全前缀匹配时生效。
- 为避免上下文窗口耗尽,Codex 会自动调用新的 Responses API 压缩上下文(compaction),用摘要表示早期对话内容以节省 token。
这些策略对于长期工程任务(如复杂代码编辑、多轮推理)至关重要。
完整内容查看原文:https://openai.com/index/unrolling-the-codex-agent-loop/