![SeaTunnel元数据缓存]()
在数据集成领域,面对成千上万的同步任务,性能瓶颈往往不在于数据传输本身,而在于“元数据管理”。类加载器冲突、Checkpoint 压力、以及频繁的数据库元数据请求,是压垮集群的三座大山。作为新一代集成引擎,SeaTunnel Zeta 凭借一套精妙的元数据缓存机制,交出了高可靠、高性能的答卷。
该机制通过智能缓存、分布式存储和自动管理三个维度,解决了传统数据工具在类加载、状态管理和元数据处理方面的性能瓶颈。
![]() SeaTunnel分布式架构下的元数据流转路径
SeaTunnel分布式架构下的元数据流转路径
缓存机制详解
1. 类加载器复用的内存策略
在传统的分布式引擎中,每个作业通常会独立创建一个类加载器。当任务量级达到几千甚至上万时,Metaspace(元空间)会因为加载了大量重复的连接器 Jar 包而迅速爆满,最终导致 OOM 崩溃。
SeaTunnel的类加载器缓存机制通过DefaultClassLoaderService实现了一套聪明的“共享内存”方案。它通过识别 Connector 的 Jar 包指纹,让使用相同连接器的不同 Job 共享同一个 ClassLoader 实例。
核心实现原理:
- 在缓存模式下,所有作业共享相同的类加载器(jobId统一设为1L)
- 使用
classLoaderReferenceCount跟踪每个类加载器的使用情况
- 只有引用计数为0时才真正释放类加载器,避免过早回收
配置方式:
seatunnel:
engine:
classloader-cache-mode: true
这种机制借鉴了内存管理的引用计数思想,只有当所有关联作业都结束且计数归零时,类加载器才会被真正卸载。这种延迟释放的设计,使得核心加载器数量无论在多大作业量下都能保持稳定,极大地节省了系统开销。
2. 分布式 Checkpoint 的容错演进
SeaTunnel 的状态管理基于经典的 Chandy-Lamport 算法,但其创新点在于深度结合了分布式内存网格 Hazelcast (IMap)。与 Flink 等引擎高度依赖外部状态后端(如 RocksDB)不同,SeaTunnel Zeta 将 IMap 作为状态的一级缓存,实现毫秒级的状态存取。数据按照 {namespace}/{jobId}/{pipelineId}/{checkpointId}/ 的严谨层级进行组织。
存储架构:
- 支持HDFS、S3、OSS等多种后端存储
- 检查点数据按
{namespace}/{jobId}/{pipelineId}/{checkpointId}/结构存储
- 支持增量检查点和精确的状态恢复
配置示例:
seatunnel:
engine:
checkpoint:
interval: 300000
timeout: 10000
storage:
type: hdfs
plugin-config:
fs.defaultFS: hdfs://localhost:9000
这种设计不仅支持增量快照以减轻 IO 压力,更重要的是,它通过 SPI 插件化架构实现了存储脱耦。当内存中的 IMap 完成状态更新后,可以异步地将数据持久化到 HDFS 或 S3 中,形成了“内存读取、持久化备份”的双重保障,确保任务在故障后能从精确的位置重启。
3. 目录元数据缓存,化解源库压力
在海量任务并行启动时,频繁请求源端数据库获取 Schema 会导致严重的连接延迟,甚至直接压垮 Hive Metastore 或 MySQL 的元数据服务。SeaTunnel 通过在连接器层(Connector Layer)引入 Catalog 缓存策略,将“高频点对点请求”转化为“引擎侧本地提取”。
-
JDBC 连接器:表结构快照与快速分片 SeaTunnel 通过 CatalogUtils 对目标库进行“结构采样”,将表注释、字段精度及主键约束等全量信息缓存至 JobMaster 上下文。这不仅加速了作业初始化,更关键的是能利用缓存的索引信息直接计算读取分片(Splitting) 的步长,无需多次往返数据库,极大缩短了万级表同步的准备时间。
-
Hive 连接器:卸载 Metastore 单点压力 针对脆弱的 Hive Metastore,HiveMetaStoreCatalog 实现了元数据托管逻辑,批量缓存 Database、Table 及 Partition 的定义。这意味着同一集群下的多个 Pipeline 可共享已加载的表路径和序列化(SerDe)信息。通过缓存分区映射关系,SeaTunnel 将原本集中在 Metastore 的解析压力卸载到 Zeta 引擎节点,显著提升了大规模分区表的同步吞吐。
机制优势总结
1. 资源利用率优化
减少类加载开销:传统工具每次作业都重新创建类加载器,而SeaTunnel通过缓存复用,显著减少了metaspace空间的占用。测试显示缓存模式下类加载器数量控制在3个以内,而非缓存模式会线性增长。
智能内存管理:通过history-job-expire-minutes参数自动清理历史作业数据,默认1440分钟后过期,防止内存溢出。
2. 高可用性保障
分布式状态存储:IMap支持数据在多个节点间的备份和同步,确保单点故障不影响整体系统可用性。
持久化支持:IMap可以持久化到HDFS等外部存储,实现集群重启后的自动恢复。
3. 性能提升显著
线程安全设计:所有缓存操作使用synchronized和ConcurrentHashMap确保线程安全。
精确状态管理:检查点机制只清理已完成的检查点数据,保留未完成的检查点状态,避免不必要的状态重建开销。
效率提升的关键因素总结
1. 架构设计优势
微内核模式:检查点存储采用微内核设计,将存储模块从引擎中分离,支持用户自定义存储实现。
分层缓存:类加载器、检查点、目录元数据分层管理,各层独立优化又协同工作。
2. 智能调度策略
引用计数机制:精确跟踪资源使用情况,避免资源浪费和泄漏。
动态资源分配:支持动态slot分配,根据集群负载自动调整资源使用。
3. 容错机制完善
自动故障恢复:基于检查点的精确状态恢复,确保任务在故障后能够从准确位置继续执行。
数据一致性保障:通过分布式事务和两阶段提交协议,确保元数据的一致性和可靠性。
区别于 Flink 与 Spark 的关键设计
可以看到,SeaTunnel 的缓存机制与 Flink 或 Spark 最大的不同在于“轻量化”与“集成化”。Flink 作为一个流计算平台,其元数据管理更多是为了复杂算子的状态服务,对于成千上万个独立小任务的并发支持并非其首要目标。而 Spark 在处理短作业时,类加载和 Context 初始化带来的延迟非常明显。SeaTunnel 则是典型的“微内核”设计,它将元数据缓存下沉到 Zeta 引擎层,不再为每个作业启动沉重的上下文。通过内置的集群协调器,SeaTunnel 能够更精细地控制每个 Slot 的元数据生命周期,这使得它在处理超大规模、异构数据源的同步任务时,比传统的计算框架更具抗压能力。
通过智能化的类加载器管理、分布式的检查点存储和灵活的目录元数据处理,SeaTunnel构建了一个高效、可靠、可扩展的数据集成平台。其核心优势在于:
- 性能优化:通过缓存复用和智能调度,显著减少了资源开销
- 高可用性:分布式存储和持久化机制确保系统稳定性
- 扩展性:微内核设计和插件化架构支持灵活扩展
这些设计使得SeaTunnel在大规模数据集成场景中表现出色,成为企业级数据处理的理想选择。
生产环境的最佳实践
在实际生产部署中,要发挥这套机制的威力,建议采取“内嵌+独立”的混合策略。对于小规模集群,使用 SeaTunnel 自带的内嵌 Hazelcast 即可;但针对万级任务的超大集群,应考虑调整 hazelcast.yaml 中的备份策略,确保 backup-count 至少为 1,以防节点宕机导致内存元数据丢失。
在监控方面,仅仅关注 JVM 指标是不够的。应当重点监控 Zeta 引擎的指标看板,关注 checkpoint_executor_queue_size(检查点执行队列)和 active_classloader_count(活跃类加载器数量)。如果发现类加载器数量随作业线性增长,通常意味着某些自定义 Connector 未能正确释放。
此外,合理配置 history-job-expire-minutes 至关重要,在保证追溯需求的同时,及时回收不再需要的 IMap 数据,是维持集群长周期运行平稳的关键。
![]() SeaTunnel元数据缓存性能监控看板
SeaTunnel元数据缓存性能监控看板

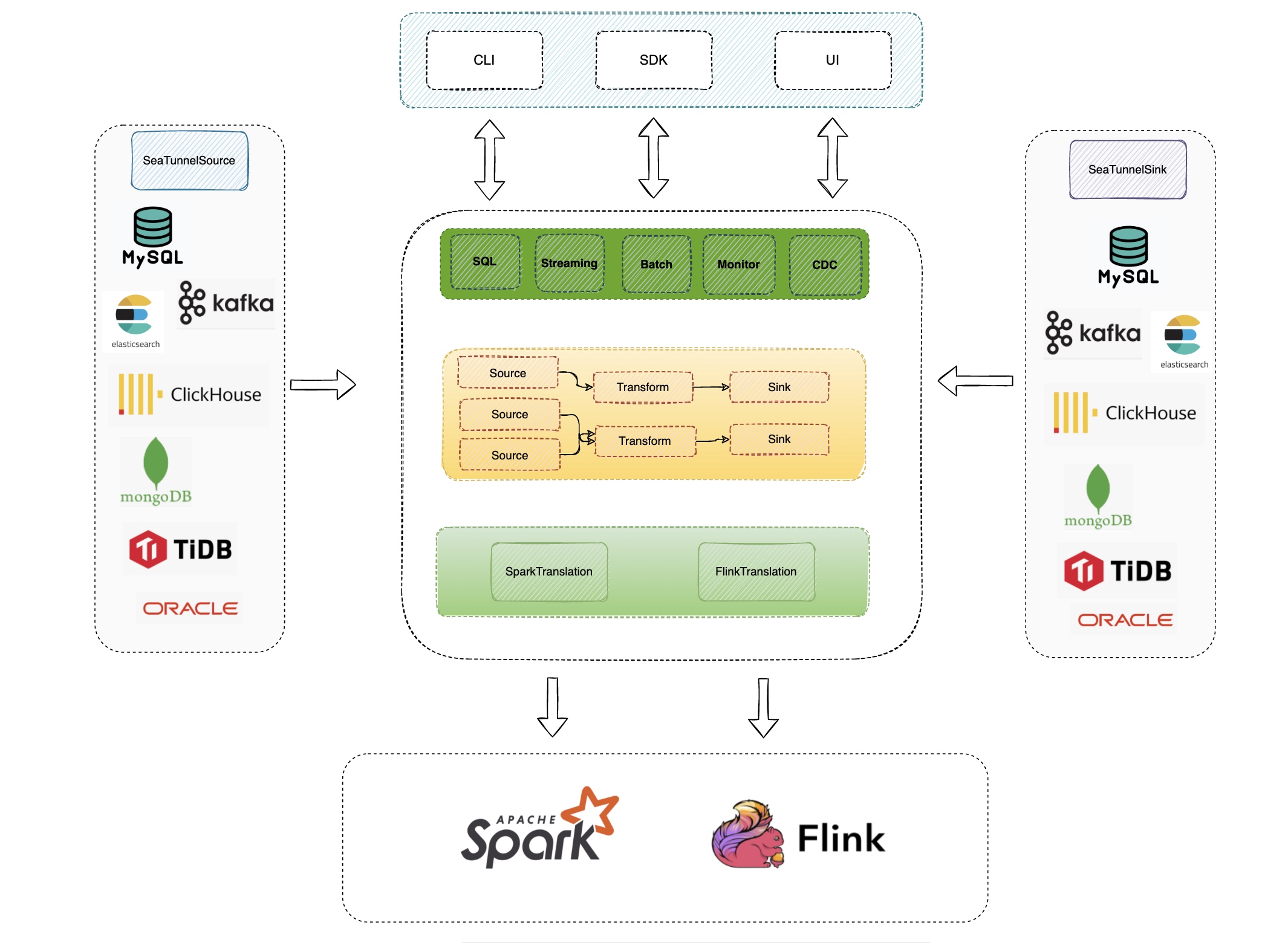 SeaTunnel分布式架构下的元数据流转路径
SeaTunnel分布式架构下的元数据流转路径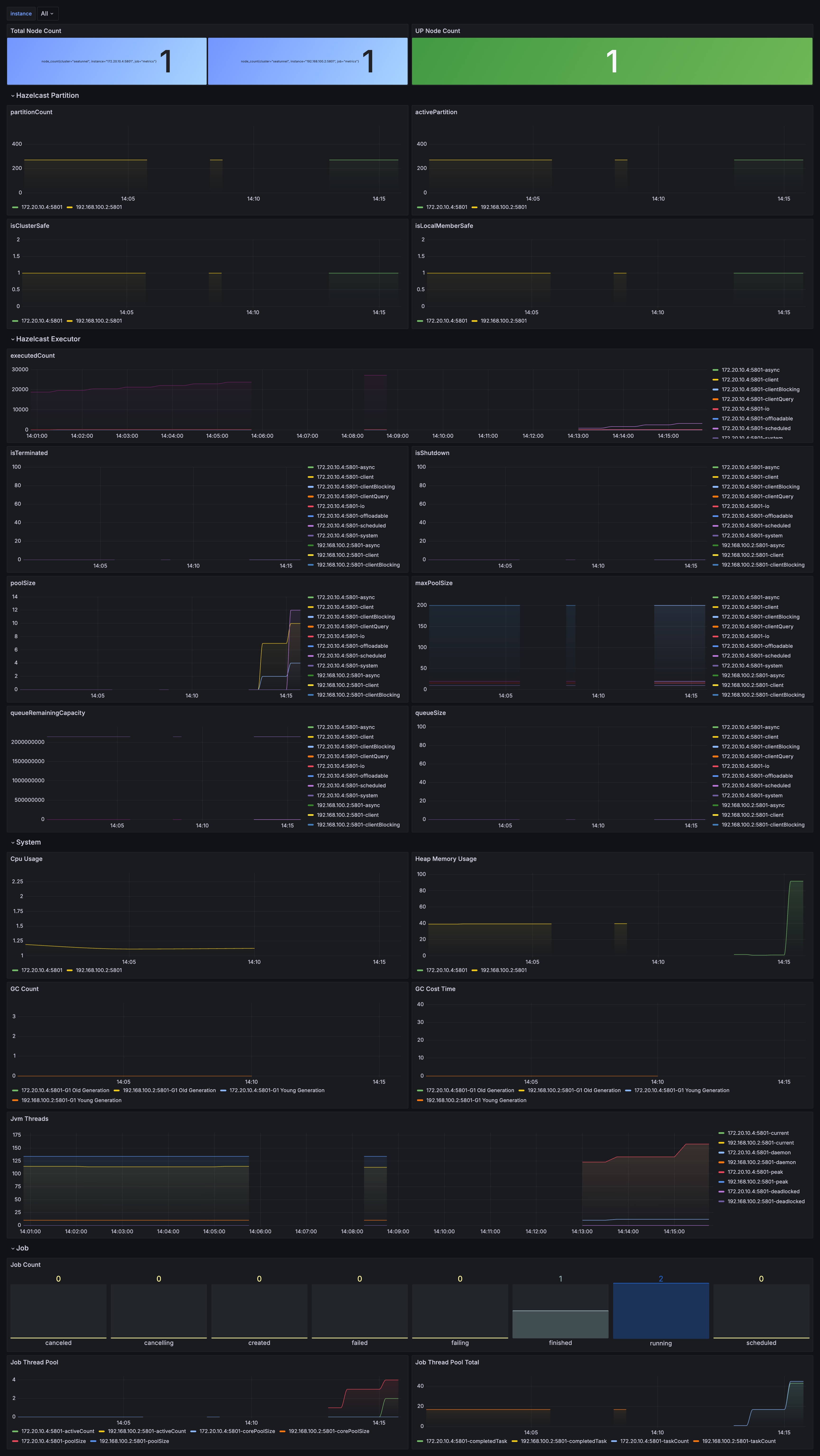 SeaTunnel元数据缓存性能监控看板
SeaTunnel元数据缓存性能监控看板