![]()
先前写过一篇《从 0 到 1 搞懂 Apache SeaTunnel CDC 流程解析》,不少读者反馈理解起来有挑战。这次基于最近在生产环境中用 SeaTunnel CDC 同步 Oracle / MySQL / SQL Server 等场景的实践,结合广大用户的反馈重新编写,希望让大家理解 SeaTunnel 实现 CDC 的过程。本篇主要讲述 CDC 的各个阶段:快照、回填、增量。
CDC 的三个阶段
整体 CDC 数据读取流程可以拆成三大阶段:
- 快照(Snapshot,全量)
- 回填(Backfill)
- 增量(Incremental)
1. 快照阶段(Snapshot)
快照阶段的含义很直观:对当前库表的数据打一份快照,通过 JDBC 全量扫表。
以 MySQL 为例,在快照时会记录当前的 binlog 位点:
SHOW MASTER STATUS;
| File |
Position |
Binlog_Do_DB |
Binlog_Ignore_DB |
Executed_Gtid_Set |
| binlog.000011 |
1001373553 |
|
|
|
SeaTunnel 会把 File 和 Position 记为低水位线(low watermark)。
注意:不是只执行一次,因为 SeaTunnel 为了加速快照,自己实现了分片切分逻辑。
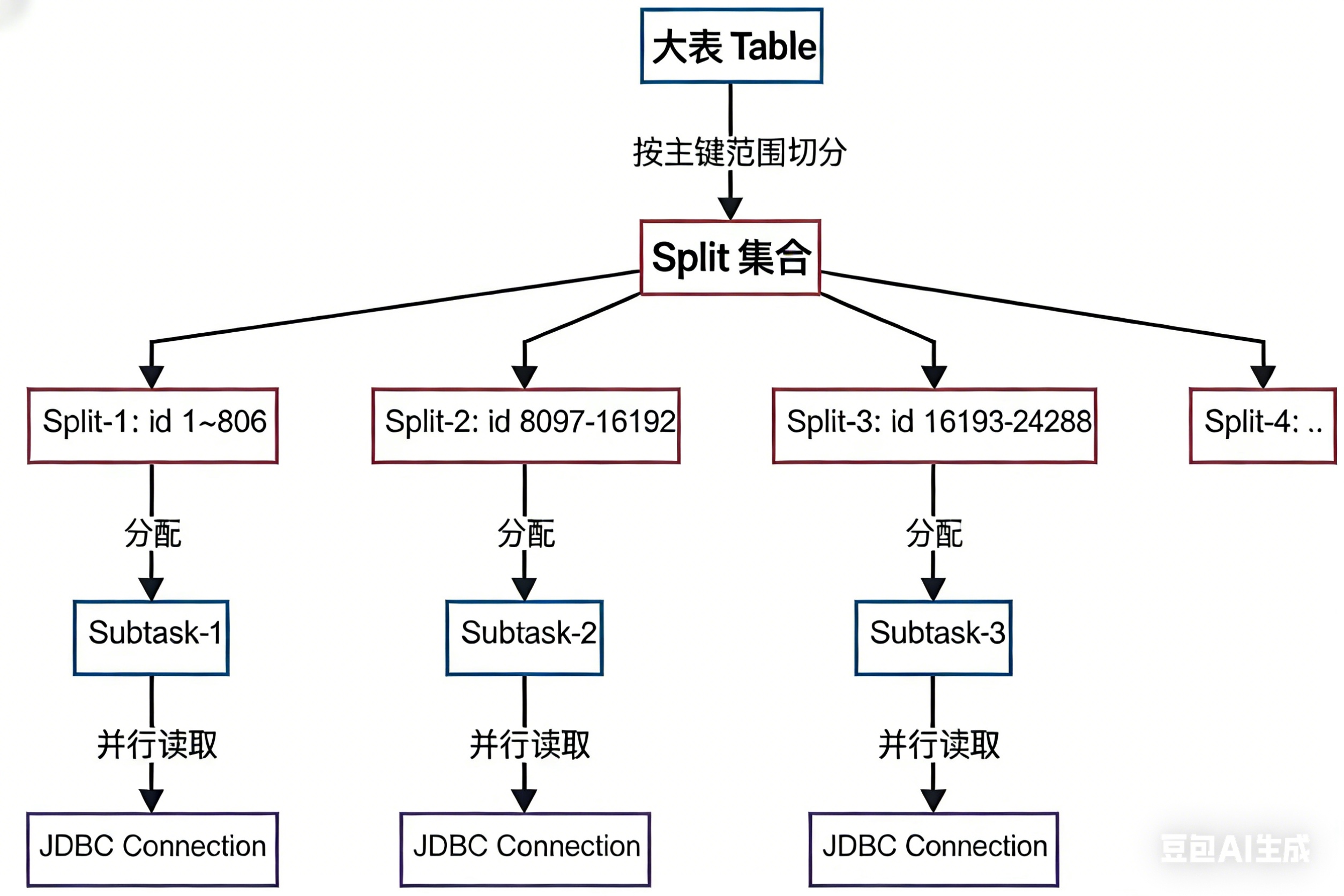
MySQL 快照切分机制(Split)
假设全局并行度是 10:
- SeaTunnel 会先分析所有表及其主键 / 唯一键范围,选择合适的拆分列
- 按这列的最大最小值进行切分,默认
snapshot.split.size = 8096
- 大表可能会被切成上百个 Split,由枚举器按 subtask 请求顺序分配到 10 个并行通道(整体上趋向均衡分布)
![]()
表级别的顺序处理(示意):
// 处理顺序:
// 1. Table1 -> 生成 [Table1-Split0, Table1-Split1, Table1-Split2]
// 2. Table2 -> 生成 [Table2-Split0, Table2-Split1]
// 3. Table3 -> 生成 [Table3-Split0, Table3-Split1, Table3-Split2, Table3-Split3]
Split 级别的并行分配:
// 分配给不同 subtask:
// Subtask 0: [Table1-Split0, Table2-Split1, Table3-Split2]
// Subtask 1: [Table1-Split1, Table3-Split0, Table3-Split3]
// Subtask 2: [Table1-Split2, Table2-Split0, Table3-Split1]
每个 Split 实际就是一个带范围条件的查询,例如:
SELECT *
FROM user_orders
WHERE order_id >= 1 AND order_id < 10001;
关键:每个 Split 单独记录自己的低水位线 / 高水位线。
在 MySqlSnapshotSplitReadTask.doExecute() 中,大致逻辑如下:
// MySqlSnapshotSplitReadTask.doExecute()
protected SnapshotResult<MySqlOffsetContext> doExecute(
ChangeEventSource.ChangeEventSourceContext context,
MySqlOffsetContext previousOffset,
SnapshotContext<MySqlPartition, MySqlOffsetContext> ctx,
SnapshottingTask snapshottingTask) throws Exception {
// Step 1: 获取低水位线(快照开始时的 binlog 位置)
final BinlogOffset lowWatermark = currentBinlogOffset(jdbcConnection);
LOG.info("Snapshot step 1 - Determining low watermark {} for split {}",
lowWatermark, snapshotSplit);
((SnapshotSplitChangeEventSourceContext) context).setLowWatermark(lowWatermark);
// 发送低水位线事件
dispatcher.dispatchWatermarkEvent(
ctx.partition.getSourcePartition(),
snapshotSplit,
lowWatermark,
WatermarkKind.LOW);
// Step 2: 读取快照数据(纯 JDBC)
LOG.info("Snapshot step 2 - Snapshotting data");
createDataEvents(ctx, snapshotSplit.getTableId());
// Step 3: 获取高水位线(快照结束时的 binlog 位置)
final BinlogOffset highWatermark = currentBinlogOffset(jdbcConnection);
LOG.info("Snapshot step 3 - Determining high watermark {} for split {}",
highWatermark, snapshotSplit);
((SnapshotSplitChangeEventSourceContext) context).setHighWatermark(highWatermark);
// 发送高水位线事件
dispatcher.dispatchWatermarkEvent(
ctx.partition.getSourcePartition(),
snapshotSplit,
highWatermark,
WatermarkKind.HIGH);
return SnapshotResult.completed(ctx.offset);
}
实践建议:split_size 不要切太小,Split 太多并不一定更快,调度和内存开销会非常大。
2 回填阶段(Backfill)
为什么需要回填?
想象一下,你在对一张正在频繁写入的表做全量快照(Snapshot)。当你读到第 100 行时,第 1 行的数据可能已经被修改了。如果你只读快照,当你读完时,你手里的数据其实是“不一致”的(一部分是旧的,一部分是新的)。
回填(Backfill)的作用,就是把“快照期间发生的数据变更”补回来,让数据最终一致。
这个阶段的行为,主要取决于 exactly_once 参数的配置。
2.1 简单模式 (exactly_once = false)
这是默认模式,逻辑比较简单粗暴,不需要内存缓存:
![]()
- 快照直发:读取快照数据,直接发给下游,不进缓存。
- 日志直发:同时读取 Binlog,直接发给下游。
- 最终一致:虽然中间会有重复(先发了旧的 A,又发了新的 B),但只要下游支持幂等写入(比如 MySQL 的 REPLACE INTO),最终结果是一致的。
特点:
- 优点:不占用内存,速度极快。
- 缺点:会有重复数据。对于 Kafka 等消息队列,消费者会看到中间状态。
2.2 精确一致性模式 (exactly_once = true)
这是 SeaTunnel CDC 最厉害的地方,也是它能保证数据 “一条不丢、一条不重” 的秘诀。它引入了内存缓存 (Buffer) 来进行去重。
通俗版解释: 想象一下,老师让你统计班里现在有多少人(快照阶段)。但是,班里的同学非常调皮,你正在数数的时候,有人跑进跑出(数据变更)。如果你只是闷头数,等你数完,结果肯定是不准的。
![]()
SeaTunnel 是这么做的:
- 先拍照(快照):先把班里的人数一遍,记在小本本上(内存缓存),先别告诉校长(下游)。
- 看监控(回填):去调取你数数这段时间的监控录像(Binlog 日志)。
- 修正记录(合并):
- 如果监控显示有人刚进来,但你没数到 -> 加上。
- 如果监控显示有人刚跑了,但你数进去了 -> 划掉。
- 如果监控显示有人换了件衣服 -> 把记录改成新衣服。
- 交作业(发送):修正完之后,你手里的小本本就是一份完美准确的名单,这时候再交给校长。
技术实现与源码解析:
SeaTunnel 把这个过程分成了三步走(以 MySQL-CDC 为例,Oracle / SQL Server 路径类似):
第一步:生成“看监控”的任务
当快照读完后,SeaTunnel 会自动生成一个任务,专门去读 “开始数数”到“数数结束” 这段时间的日志。
// 源码位置:MySqlSnapshotFetchTask.java
private IncrementalSplit createBackfillBinlogSplit(
SnapshotSplitChangeEventSourceContext sourceContext) {
return new IncrementalSplit(
split.splitId(),
Collections.singletonList(split.getTableId()),
// 监控录像开始时间(低水位线)
sourceContext.getLowWatermark(),
// 监控录像结束时间(高水位线)
sourceContext.getHighWatermark(),
new ArrayList<>());
}
第二步:看着监控改作业(核心逻辑)
这是最关键的一步。SeaTunnel 会拿着日志(监控录像)去修改内存里的快照数据(小本本)。
// 源码位置:JdbcSourceFetchTaskContext.java(JDBC 类 CDC 源共用)
@Override
public void rewriteOutputBuffer(
Map<Struct, SourceRecord> outputBuffer, // 这就是那个“小本本”(内存缓存)
SourceRecord changeRecord) { // 这是监控里看到的一条变化
// 获取这条变化的主键(比如学号)和内容
Struct key = (Struct) changeRecord.key();
Struct value = (Struct) changeRecord.value();
if (value != null) {
// 看看发生了什么事:是新增(CREATE)、修改(UPDATE) 还是 删除(DELETE)?
Envelope.Operation operation =
Envelope.Operation.forCode(value.getString(Envelope.FieldName.OPERATION));
switch (operation) {
case CREATE:
case UPDATE:
// 【重点】不管是新增还是修改,都把最新的样子记下来
// 哪怕是 UPDATE,我们也要把它伪装成 READ(快照读取),因为对下游来说,这就是初始数据
Envelope envelope = Envelope.fromSchema(changeRecord.valueSchema());
Struct source = value.getStruct(Envelope.FieldName.SOURCE);
Struct after = value.getStruct(Envelope.FieldName.AFTER); // 取最新的数据
Instant fetchTs =
Instant.ofEpochMilli((Long) source.get(Envelope.FieldName.TIMESTAMP));
// 重新包装成一条标准的“读取”记录
SourceRecord record =
new SourceRecord(
changeRecord.sourcePartition(),
changeRecord.sourceOffset(),
changeRecord.topic(),
changeRecord.kafkaPartition(),
changeRecord.keySchema(),
changeRecord.key(),
changeRecord.valueSchema(),
envelope.read(after, source, fetchTs));
// 【修正操作】
// put 的意思是:如果小本本上还没有(新增),就加上;如果有(修改),就覆盖掉旧的
outputBuffer.put(key, record);
break;
case DELETE:
// 【修正操作】
// 如果监控显示这个人走了,直接从小本本上划掉他的名字
// 这样下游就根本不知道这个人曾经存在过,数据就干净了
outputBuffer.remove(key);
break;
case READ:
// 回填阶段不应该出现 READ 事件,如果有就是出 Bug 了
throw new IllegalStateException("不应该出现的情况");
}
}
}
第三步:发送最终结果
等监控录像看完了(回填结束),内存里的 outputBuffer 就是最准确的数据了。这时候 SeaTunnel 才会把它一次性发给下游。
小白总结:exactly_once = true 就是 “先憋着不发,等核对清楚了再发”。
- 好处:下游收到的数据绝对干净,没有重复,也没有乱序。
- 代价:因为要“憋着”,所以需要消耗一些内存来存数据。如果表特别大,内存可能会不够用。
2.3 两个关键疑问解答
Q1: 为什么代码里写 case READ: throw Exception?回填阶段为啥不会有 READ?
READ 事件 是 SeaTunnel 自己定义的,专门用来表示“这是从快照里读出来的存量数据”。- 回填阶段 读的是数据库的 Binlog(日志)。Binlog 里只记录“增删改”(INSERT/UPDATE/DELETE),从来不会记录“某人查询了一条数据”。
- 所以,如果你在回填阶段读到了
READ 事件,说明代码逻辑错乱了,把快照读的数据当成日志读了,这绝对是 Bug。
Q2: 放在内存里,内存能放得下么?会不会 OOM?
这是一个非常好的问题!
- 不是把整张表塞进内存:SeaTunnel 是按**分片(Split)**来处理的。
- 分片很小:默认一个分片只有 8096 行数据。
- 用完即扔:处理完一个分片,发走,清空内存,再处理下一个。
- 内存占用公式 ≈ 并行度 × 分片大小 × 单行数据大小。
举个例子:假设你开了 4 个并发,分片大小 8096,一行数据 1KB。内存占用 ≈ 4 * 8096 * 1KB ≈ 32MB。这对现代服务器来说完全是小意思。
什么时候会爆内存?
- 单行数据极大:比如表里存了高清图片或大 JSON,一行就有 10MB。
- 分片设得太大:你手动把
split.size 设成了 100 万。
- 并行度太高:你开了几百个并发。
优化建议:如果遇到 OOM,优先检查 split.size 是否过大,或者调小并行度。
2.4 关键细节:多分片间的水位对齐(Watermark Alignment)
这是一个非常隐蔽但又极其重要的问题。如果处理不好,就会导致数据要么丢,要么重。
![]()
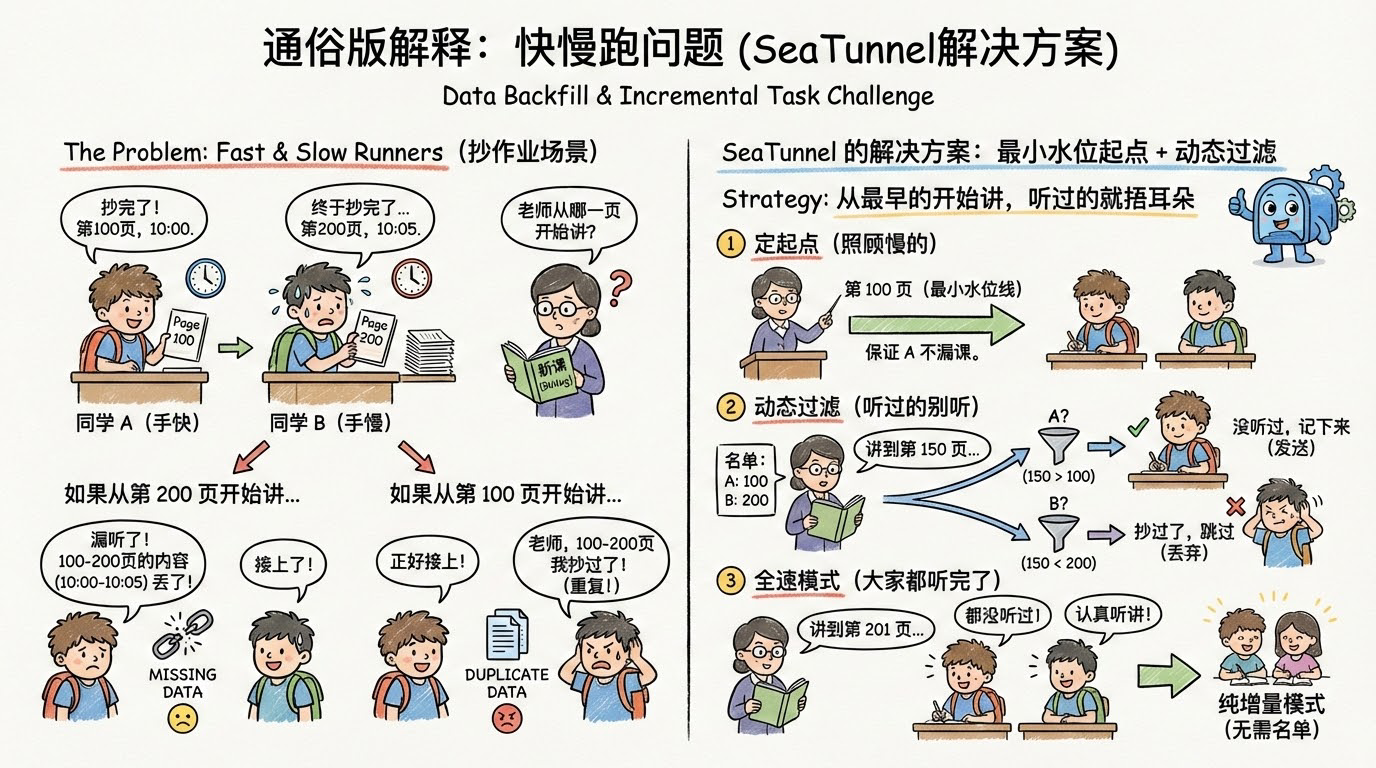
通俗版解释:快慢跑问题
想象一下,有两个同学(分片 A 和 分片 B)在抄作业(回填数据)。
- 同学 A(手快):抄到了第 100 页,就抄完了,此时时间是 10:00。
- 同学 B(手慢):抄到了第 200 页,才抄完,此时时间是 10:05。
现在,老师(增量任务)要接着他们抄的地方继续往下讲新课(读取 Binlog)。老师应该从哪一页开始讲?
-
如果从第 200 页开始讲:
- 同学 B 倒是接上了。
- 但是!同学 A 在 100页~200页 之间漏听的内容(10:00~10:05 期间发生的事),就彻底丢了。
-
如果从第 100 页开始讲:
- 同学 A 开心了,正好接上。
- 但是!同学 B 会抱怨:“老师,100页~200页的内容我刚才抄作业的时候已经抄过了啊!” 这就导致了重复。
SeaTunnel 的解决方案:从最早的开始讲,听过的就捂耳朵
SeaTunnel 采用了一种 “最小水位起点 + 动态过滤” 的策略:
- 定起点(照顾慢的):老师决定从 第 100 页(所有分片中最小的水位线) 开始讲。这样保证同学 A 不会漏课。
- 动态过滤(听过的别听):老师讲课的时候(读取 Binlog),手里拿个名单:
{ A: 100, B: 200 }。
- 老师讲到第 150 页的内容:
- 看看名单,是给 A 的吗?150 > 100,A 没听过,记下来(发送)。
- 看看名单,是给 B 的吗?150 < 200,B 刚才抄过了,直接跳过(丢弃)。
- 全速模式(大家都听完了):
等老师讲到第 201 页时,发现大家都已经没听过了,这时候就不用再看名单了,所有人一起认真听讲(进入纯增量模式)。
![快慢跑问题]()
技术实现总结(对应 exactly_once = true 的路径):
-
Global Start Offset(增量起点)
在 IncrementalSplitAssigner.createIncrementalSplit() 中,会遍历所有快照分片的水位:
exactly_once = true 时使用 HighWatermark;exactly_once = false 时则使用 LowWatermark。
取这些 offset 的最小值作为 IncrementalSplit.startupOffset,这就是增量阶段统一的“起跑线”。
-
Filter Phase(按分片范围 + 高水位过滤)
在增量读取侧的 IncrementalSourceStreamFetcher.configureFilter() 里:
- 会把各个表的
CompletedSnapshotSplitInfo 归类到 finishedSplitsInfo,里面记录了每个分片的 [splitStart, splitEnd, HighWatermark];
- 同时为每张表计算一个
maxSplitHighWatermarkMap[tableId],表示该表所有分片 HighWatermark 的最大值。
shouldEmit(SourceRecord record) 的行为是:
- 如果
!taskContext.isExactlyOnce(),只判断 position.isAfter(splitStartWatermark),完全跳过分片水位的过滤逻辑;
- 如果
isExactlyOnce():
- 若当前表已经进入“纯增量阶段”(
position >= maxSplitHighWatermarkMap[tableId]),直接放行;
- 否则,只在记录属于某个分片键范围,且
position.isAfter(splitInfo.watermark.highWatermark) 时才真正 emit。
-
Phase Finish(切换到纯增量模式)
当某张表的位点追上它所有分片的最大 HighWatermark 后,该表会被加入 pureBinlogPhaseTables;
之后对这张表就不再进行 per-split 过滤,彻底进入“纯增量模式”,持续按 offset 顺序消费日志。
一句话总结:
有 exactly_once:增量阶段会严格按照“起点 offset + 分片范围 + 高水位”的组合来过滤,确保不会把快照已经覆盖过的历史变化再发一遍;
没有 exactly_once:增量阶段就变成简单的“从某个起点 offset 往后顺序消费”,不会为每个 SnapshotSplit 做精细校对。
3 增量阶段(Incremental)
当回填(对 exactly_once = true 而言)或者快照阶段结束之后,就进入纯增量阶段:
- MySQL:基于 binlog(
MySqlBinlogFetchTask + Debezium MySQL streaming)
- Oracle:基于 redo / logminer(
OracleRedoLogFetchTask + Debezium Oracle logminer)
- SQL Server:基于事务日志 / LSN(
SqlServerTransactionLogFetchTask + Debezium SQL Server)
- PostgreSQL:基于 WAL(
PostgresWalFetchTask + Debezium Postgres)
小提示:
当前 SeaTunnel 官方 CDC 连接器主要覆盖 MySQL / Oracle / PostgreSQL / SQL Server / MongoDB / TiDB / openGauss 等,并没有提供 DB2 / Informix 的 CDC 连接器实现。
“DB2 / Informix:基于各自日志机制” 更像是一种“类比说法”——如果未来要支持,大概率也是基于各自的事务日志 / 变更日志来做 CDC。
SeaTunnel 在增量阶段的行为和原生 Debezium 非常接近:
- 按 offset 顺序消费日志;
- 对每个变更构造 INSERT / UPDATE / DELETE 等事件;
- 在
exactly_once = true 时,把 offset 和分片状态一并纳入 checkpoint,配合 IncrementalSplitState 与 IncrementalSourceReader.snapshotState() 实现故障恢复后的“精确一次”语义。
4 总结
SeaTunnel CDC 的核心设计哲学,就是在 “快”(并行快照) 和 “稳”(数据一致性) 之间寻找完美的平衡。
回顾一下整个流程的关键点:
- 切片(Split)是并行加速的基础:把大表切成小块,让多个线程同时干活。
- 快照(Snapshot)负责搬运存量:利用切片并行读取历史数据。
- 回填(Backfill)负责缝合裂隙:这是最关键的一步。它通过记录 Low Watermark 和 High Watermark,把快照期间发生的变更“补”回来,并利用内存合并算法消除重复,实现 Exactly-Once。
- 增量(Incremental)负责实时同步:无缝衔接回填阶段,持续消费数据库日志。
理解了 “快照 -> 回填 -> 增量” 这个三部曲,以及 “水位线(Watermark)” 在其中的协调作用,就真正掌握了 SeaTunnel CDC 的精髓。它不是一个黑盒,而是经过精心设计的分布式高性能数据同步系统。