本文整理自 2024 Apache Pulsar 欧洲峰会,由来自 Flipkart 的工程师安尼尔·戈达带来的《Flipkart 异步总线实现不停机从 Kafka 迁移到 Pulsar》的演讲视频。
背景介绍
Flipkart 是印度领先的电子商务平台之一。我们基于 Kafka 打造的异步总线承接了公司海量的 HTTP 调用和消息传输。但随着业务的发展,Kafka 已经不能跟上公司快速变化的业务发展要求。随着调研和测试,我们最终决定使用 Pulsar 替换 Kafka。
我们选择Pulsar 的主要原因,包括:
- Pulsar 原生支持多租户模型:这使得它能够在同一实例中为多个租户服务,而每个租户可以独立管理自己的命名空间和权限。这对于需要隔离不同客户数据的大型系统来说非常重要。
- Pulsar 原生支持的 Geo 跨域传输能力:这使得我们可以直接使用 Geo 打造自己的跨域、多机房业务。
- Pulsar 提供存储和计算的分离架构:这意味着系统可以分别扩展存储和计算资源,根据需要优化性能和成本。
从 Kafka 迁移到 Pulsar 给我们带来了诸多优势。Pulsar 内置的企业级功能,减少了我们自行开发和维护的成本,也降低了系统的总体复杂性。在 Kafka 中,这些高级功能都需要额外构建和维护。
本文中,我们将分三个部分详细讨论 Flipkart 的异步总线如何实现从 Kafka 到 Pulsar 的实时迁移:
- 第一部分是介绍 Flipkart 异步总线的价值所在;
- 第二部分将讨论我们在从 Kafka 迁移到 Pulsar 时面临的挑战;
- 第三部分是我们提出的解决方案,即为我们如何为用户实现实时迁移。
Flipkart 异步总线
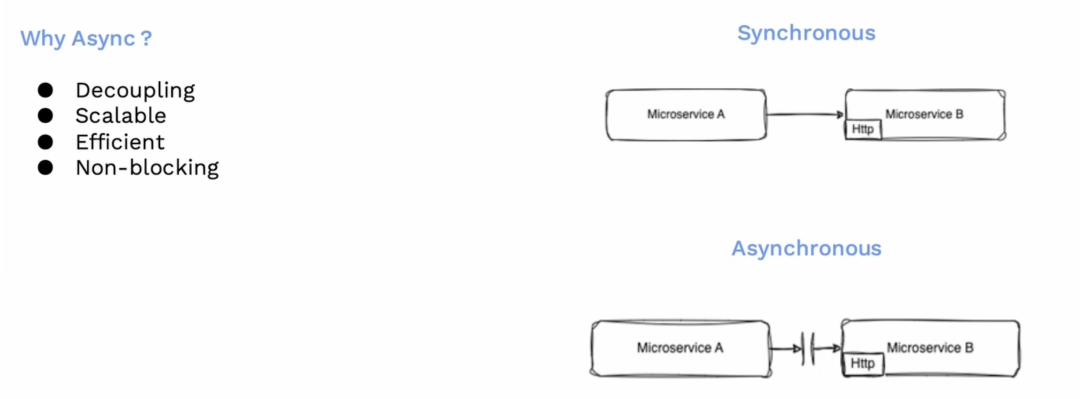
同步 vs异步
在深入探讨之前,我们需要回顾一下同步和异步的区别,以及我们为什么选择异步操作。
![]()
在同步操作中,服务 A 通过 HTTP 连接到服务 B,并等待其响应,直到服务 B 完成请求的处理。然而,这种方式并不可扩展,因为存在阻塞,并且与服务 B 紧耦合。这就是为什么我们使用异步处理:在异步处理中,服务 A 将请求发往服务队列,然后继续执行自己的任务,不会等待服务 B 的响应。服务 B 可以自行决定处理时间,甚至可以延迟处理。这意味着两个服务在职责上是解耦的,它们可以独立地扩展,并且效率高,不会发生锁定。
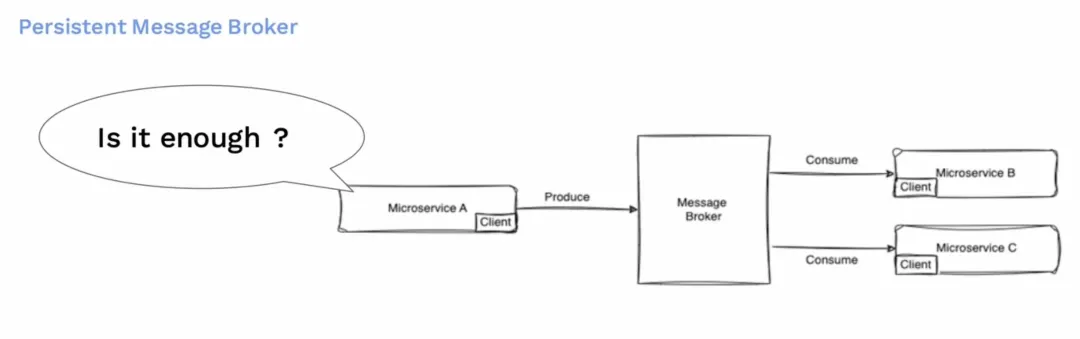
消息代理
我们通常使用可持久的消息队列(消息代理Broker)来实现这一点。消息代理位于服务 A 和服务 B 之间。服务 A 向消息代理生产消息,而服务 B 则从消息代理中消费消息。当有多个消费者或多个服务对同一消息感兴趣时,它们就也会消费相同的主题。
![]()
但问题是,这样就足够了吗?
多样化的需求
![]()
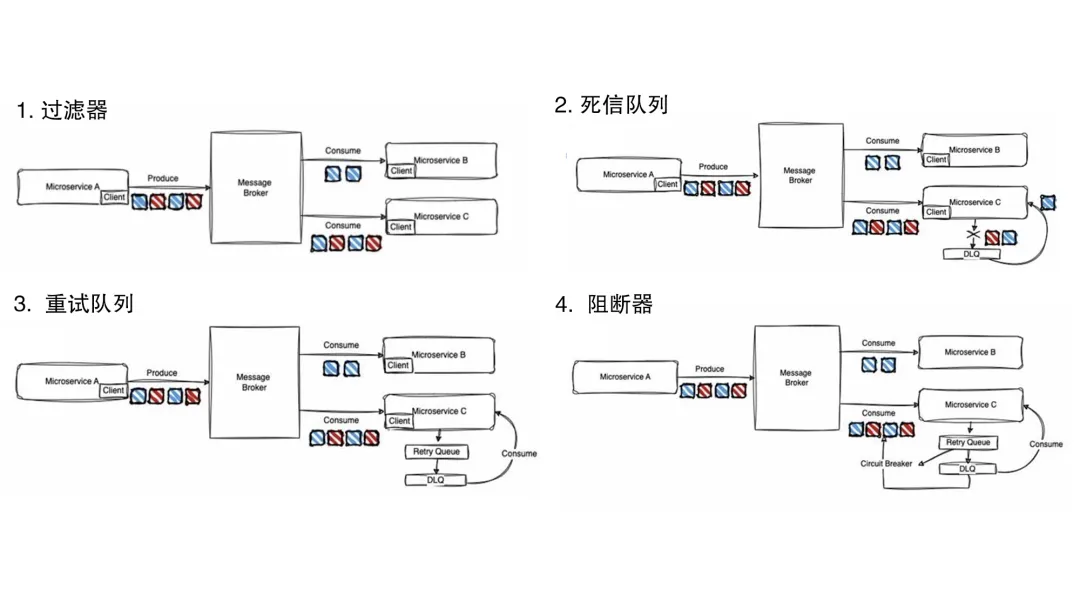
现在的微服务都会围绕消息代理构建多种多样的服务,以满足其端到端的需求。而简单的消息队列,无法满足这类多样化的需求。复杂点的业务都需要考虑失败管理。
- 过滤器需求:我们常见的过滤器,要求相当简单。只是有些服务,需要全量消费,而有些服务又只需要部分消息,这些都是由业务特点决定的。他们同时存在,需要对应满足。
- 死信队列:对于处理失败的消息,有可能需要存储很长时间并稍后消费。你的消费模式,可能是选择性消费,例如需要跳过某些消息甚至跳过所有消息。也可能想要消费所有消息。这完全取决于用例。但你都可能根据需要会需要从死信队列中消费。
- 重试消息:在消息转移到死信队列存储之前,如果你的消息因某些异常而失败,而且该异常可以恢复,你会希望重试这些消息,而不是直接将其标记为失败消息并移至死信队列。
- 消息断路器:对于可能存在的大面积处理失败,你应该还需要准备断路器。如果你的服务依赖于另一个服务,这些服务一旦出现不可用,例如数据存储出现问题,那么你就会知道,大多数消息都会将处理失败。这时候你不会想要继续从消息代理那里拉取更多消息,而是根据失败率控制你从消息代理拉取的消息数量。如果失败率高,你会想减少拉取;如果失败率低,你会想全速运行。
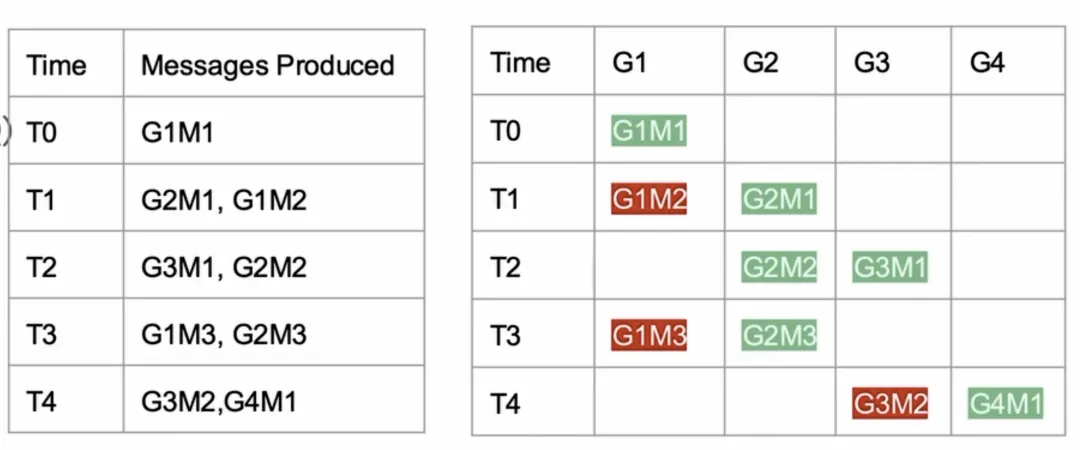
按组排序
组内有序(Group Ordering),这是用户会在消息队列服务中寻找的一个重要特性。在许多消息队列系统中,为了保证同一个组的消息被顺序处理,系统会确保同一组的所有消息都进入到同一个分区。只不过,这时候在同个分区内,也可能有来自不同组的消息。在这种情况下,需要有一种机制来跟踪每个组内的消息处理状态,并确保按顺序处理消息。例如,如果一个组的第一条消息在时间点T0被成功消费,然后同一组的第二条消息在时间点T1失败了,那么在时间点T3来自同一组的第三条消息就不应该被处理,直到问题得到解决。因此你需要维护一个状态管理系统,来记录每个消息的处理结果,并基于这些信息来决定是否处理后续的消息。
![]()
同样,在一个订单系统中,会有多个服务在彼此协同。比如当用户下单时,首先需要确认支付成功,然后再更新库存,最后再由仓库发货。这三个服务虽然是独立的,但实际是相互依赖的:没有完成支付,你就不要更新你的库存;如果库存没有更新,你就不要发货。前一步骤失败了,下一步骤就要中止。这就是用户通常寻求的组内顺序性。同样,这表明需要维护组内消息的状态,需要根据前一个状态,来决定如何处理后一条消息。
额外的复杂性
此外,有相当一部分用户,他们想让微服务A 对微服务 B 进行一个简单的 HTTP 调用,并希望这个过程是异步的,不需要等待响应的。
![]()
通常,我们实际上仍然会引入消息代理来提供异步通信和服务解耦。
不过这会导致客户端过于复杂,同时引入新的问题:
- 用户需要依赖一个消息客户端。
- 维护客户端会带来额外开销,包括集成、维护升级成本
- 用户需要更多消息队列本身相关专业知识等。
Varadhi:Flipkart 异步总线
Flipkart需要的消息代理
因此,基于以上需求,Flipkart 需要的消息代理至少要满足以下特点:
- 支持组内有序
- 支持过滤
- 支持重试队列
- 支持死信队列
- 可选择性消费
- 支持断路器模式
为了解决以上问题,我们推出了 Varadhi,这是 Flipkart 自研的异步总线。
![]()
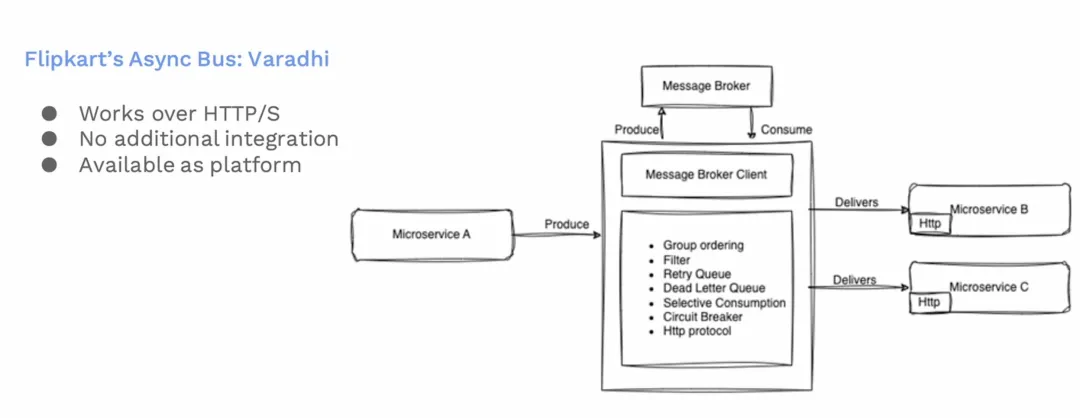
Varadhi 实现了我们上述需要的所有功能要求。Varadhi隐藏了内部的消息队列的实现细节,对外给用户提供完整的平台服务。
目前 HTTP 或者 HTTPS 都是支持的。用户集成也没有任何额外的负担。
Varadhi平台规模
目前Pulsar Varadhi平台支持了:
- 180+ Tenants
- 3500+ Topics
- 9500+ Subscriptions
- ~0.5 Million provisioned QPS
- ~1 Billion messages produced
在 Varadhi平台,目前已经有180多个租户加入,3500多个Topic和9500多个订阅。每天最多约能产生10亿条消息,而且这些消息能在同一天被消费完。
Varadhi组件介绍
![]()
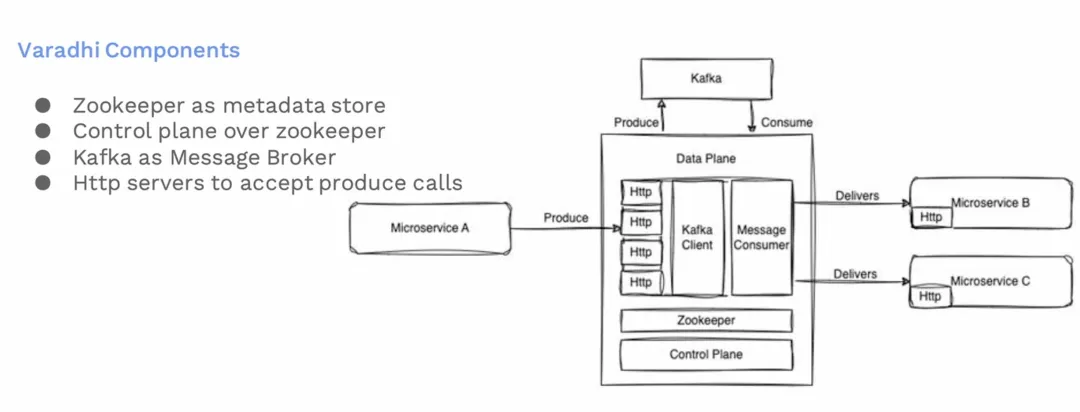
这是Varadhi的组件架构图。其中ZooKeeper 维护元数据。我们有一个控制平面,允许用户配置他们的订阅主题和端点,以及设置他们要从哪里接收消息。我们还有个HTTP服务器,这些服务器处理来自用户的生产请求。这些生产请求随后被持久化在消息代理中。
以下是每个组件的详细说明:
- ZooKeeper:用于维护服务元数据(metadata)的组件。
- Control Plane:控制平面允许用户配置他们的订阅主题和终端点(endpoints)。这是一个用户交互界面,用户可以在这里设置他们要从哪里接收消息。
- HTTP Servers:这些服务器处理来自用户服务的生产请求(produce requests)。这些请求是关于消息的生成和发送。
- Message Broker (Kafka):消息代理组件,之前使用的是Kafka,现在已经被 Pulsar 所取代。它负责存储和管理传入的消息。生产请求在这里被持久化。
- Message Consumer Services:这些服务从Kafka消费消息,然后将消息传递到用户配置的微服务终端点。
这样的架构设计分离了消息的生产、管理和消费过程,增强了系统的扩展性和可维护性,允许我们灵活地处理大量的消息生产和消费请求。同时,通过ZooKeeper确保系统的配置和同步,控制平面也可以为用户提供易于管理和配置的界面。
我们之前还是使用 Kafka 作为消息代理。而现在,里面的 Kafka 系统已经被 Pulsar 取代了。因为我们想利用 Pulsar 原生自带的多租户模型、GEO特性还有存储和计算分离架构。使用这些功能使得我们的平台管理变得更加简单和有效。而在 Kafka 中,需要额外构建这些功能,增加了开发和维护的复杂性。
迁移挑战
迁移要求
![]()
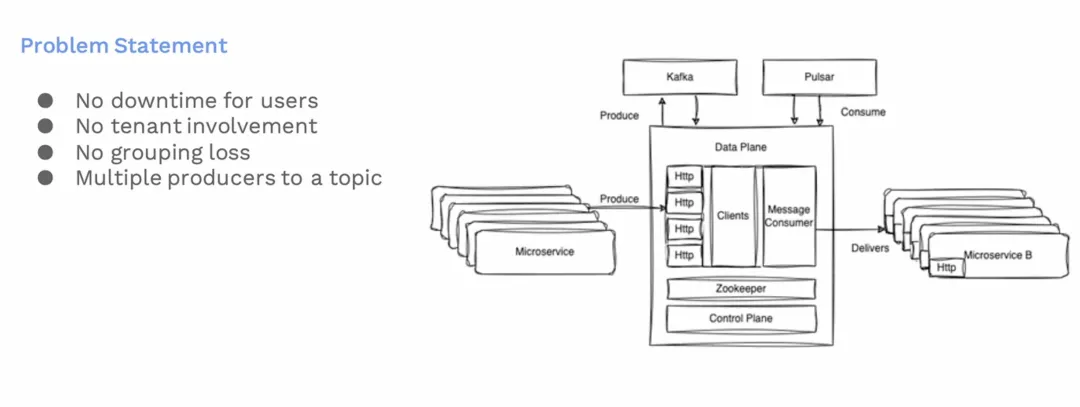
从 Kafka 迁移到 Pulsar 还是会面临很多挑战,我们有以下具体的迁移要求:
- 确保不停机:迁移过程中不能影响现有用户的服务可用性。
- 用户无感知:不希望让用户参与到迁移过程中,以减少复杂性和避免长时间的迁移。
- 维持顺序性:确保在Kafka和Pulsar之间迁移消息时,消息的顺序能维持一致,这对于确保业务流程的连贯性至关重要。
- 支持多生产者模式: 我们需要支持多个生产者向同一主题发送消息的情况,这在我们多服务环境中很常见。
这些要求,体现了迁移的复杂性。对我们保持高可用和数据一致性方面提出了很大的挑战。
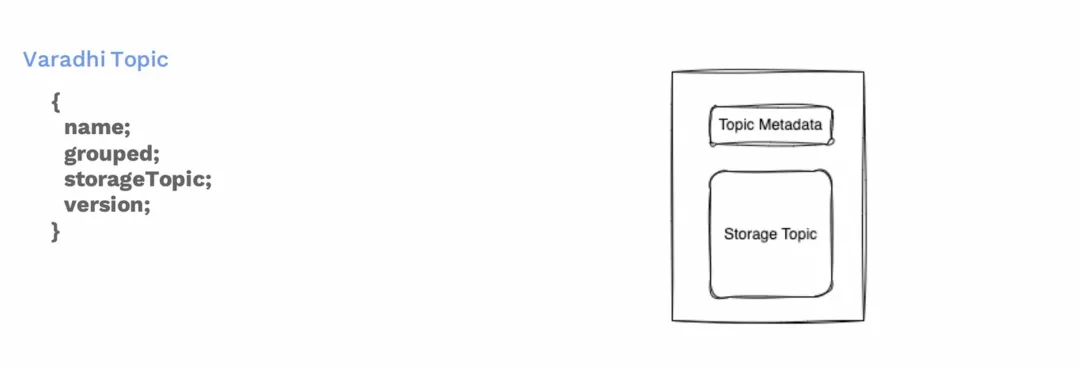
Varadhi topic元数据
![]()
在介绍迁移方案之前,需要先说明下我们自定义了一个 Varadhi 版本的Topic。里面包含 Topic名称,是否分组还是有 Topic 的存储位置,是基于Kafka的或是基于Pulsar的存储。最后还有个 Topic 的配置版本。每次更新Topic时,版本号会递增。
方案 1:整体替换
整体替换存储 topic
![]()
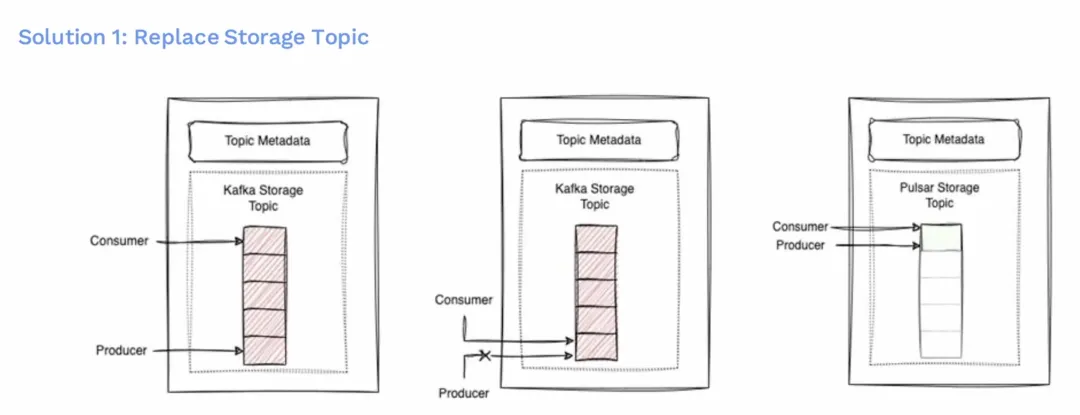
第一个方案是更换存储 Topic,这是最简单的方案。但是要从 Kafka 替换为 Pulsar 的存储主题,我们得先暂停生产,等待消费者追上来。一旦完成同步,也就是说 Kafka 存储主题中的所有消息都被消费了,然后我们就可以用 Pulsar 替换它了。同时生产者和消费者的指针都是切换到 Pulsar。这样就可以从 Pulsar 主题上进行消费和生产了。
优劣势分析
![]()
这个方案的优点是生产者和消费者可以同时进行,这意味着用户的顺序性得到保留。任何生产出的消息将会以产生的顺序被消费,因为迁移没有带来这方面的改变。而且方案很容易实现。然而,也有一些不利因素,由于这些原因,我们无法继续采用这种方法。其中之一是,我们可能会有多个消费者对应一个生产者,一旦其中有消费出现延迟的,就会使我们的生产停机时间变得很长,这是我们不希望让用户经历的。另外,偏移重置不可用,你不能将你的消费指针回退到 Kafka,即使用户已经为该主题设置了某种保留策略。那时候,我们将不得不丢失那些信息,这对我们来说可能是不可接受的。
方案 2:分组替换
分组替换存储 topic
![]()
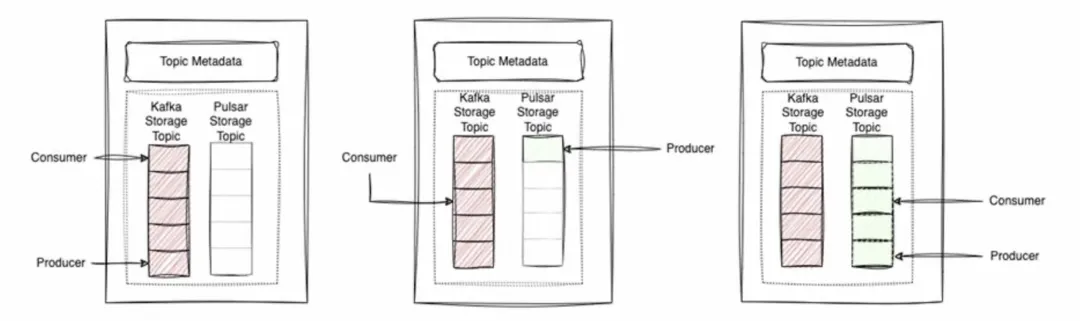
为了克服这个问题,我们决定采用一个分段的Varadhi主题方案。
- 现在一个Varadhi主题可以接入多种存储主题,并且有一个指针指示我们应该生产到哪个主题。
- 单一主题被划分为多个段,每个段被认为是一个新的存储主题。当我们决定创建一个新的存储主题时,前一个段结束,新的段开始。
- 生产和消费可以在不同的段同时进行。
这会出现一个现象:消费的指针总是落后于生产的指针。尽管消费者的指针可能位于不同的存储主题中,但仍然落后于生产者所在的存储主题。
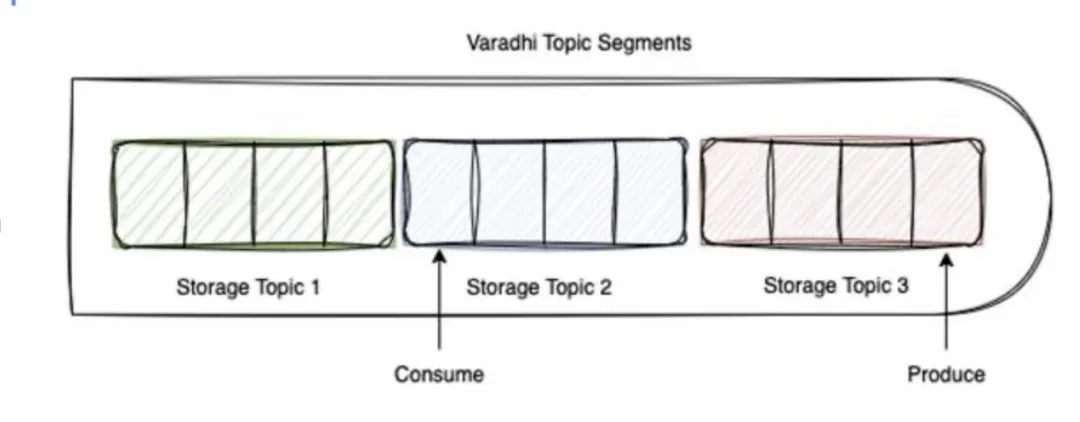
替换示例
![]()
在这个例子中,我们可以看到存储主题1存在了一段时间,然后我们增加了存储主题2,消费仍然发生在存储主题2中。我们将继续生产并移动到存储主题3进行生产。
所以,从一个主题到另一个主题的迁移过程会是这样的:我们设立了一个目标主题,在某一特定时间点,我们尝试更改开关,请求进行迁移,并会告诉生产者现在可以切换到目标主题进行生产。此时,生产者继续前进,开始向目标主题生产,一旦消费者完成从前一个主题的消费,最终也会转移到目标主题上来。
优劣势分析
![]()
这个方案有一些优势。
- 首先这里的生产和消费是异步切换的
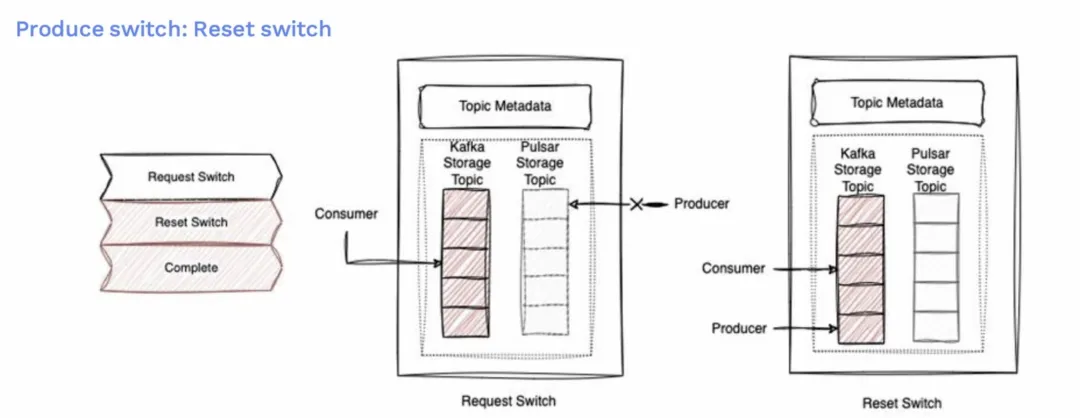
- 用户没有停机时间
- 我们仍然可以支持偏移重置,支持用户将他的消费指针移动到特定点,并从 Kafka 开始再次消费。一旦消费滞后为零,消费者将再次转移到目标主题。
然而,这里也有一个挑战,因为生产者和消费者是异步切换的,生产者之间没有协调。记得我们有多个 HTTP 端口吧。这些异步切换,这会带来一个风险,可能会导致我们组内的顺序性出现问题。
协调生产者切换
![]()
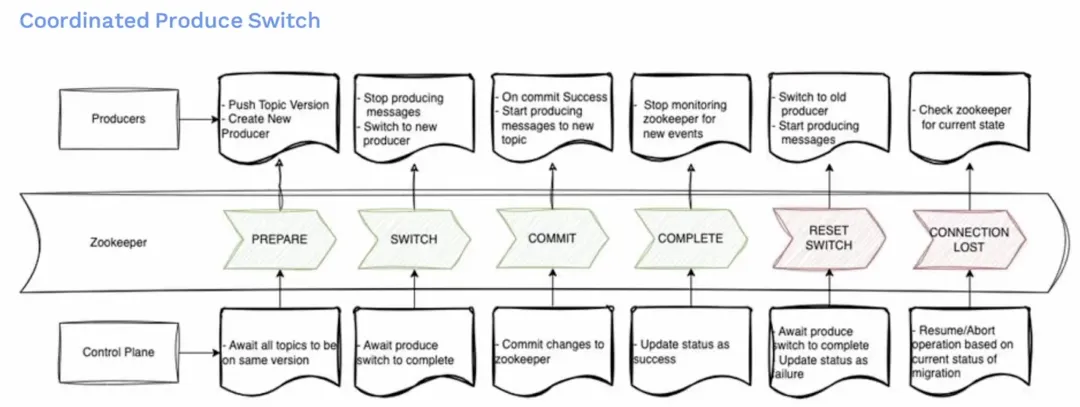
为了克服这一点,我们决定采用一个基于协调的生产切换方案。这里面有两部分非常重要。第一个是控制平面,负责协调整个切换过程。第二个是ZooKeeper ,用来维护迁移过程中的程序状态。生产服务会监听这些状态,并根据获取到的状态做出对应的反应。
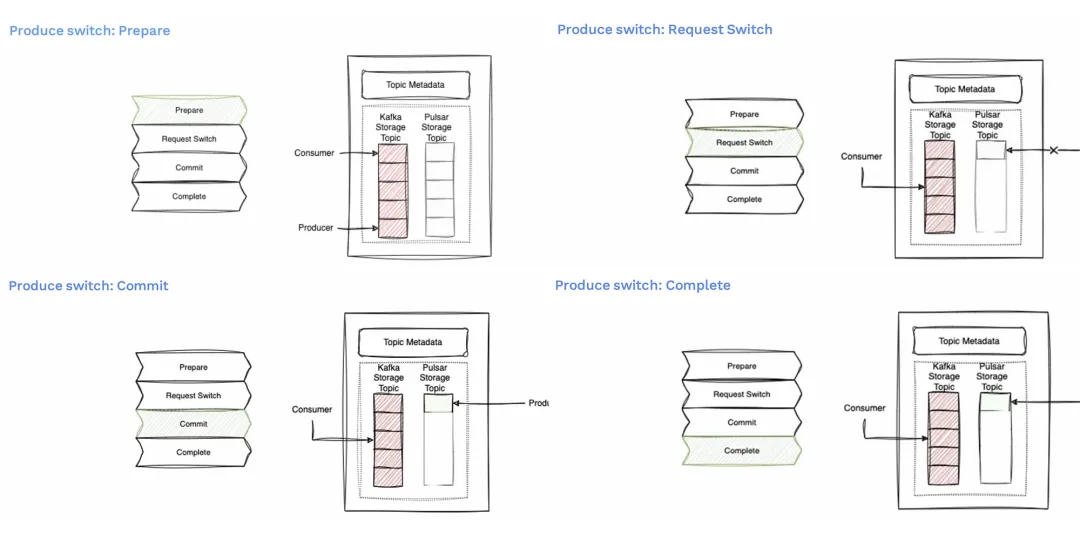
- 第一阶段是准备阶段,我们要求所有的生产者更新他们的主题版本,并创建新的生产者实例。这一阶段不涉及停机。生产者在后台进行初始化和连接验证。这时候生产仍在 Kafka 主题上进行。准备可能需要一定时间,因为需要让控制平面等待所有生产者都准备完成。这包括使用最新版本并准备好连接实例对象。
- 然后我们进入切换阶段。生产者将停止向旧主题发送消息,并准备切换到新主题。在得到控制面通知他们具体的切换指令之前,他们还不会向新主题发送消息。在此阶段,实际的消息生产会暂停,导致短暂的系统停机。这个停机时间通常是非常短的,并且是可控的。
- 之后进入提交阶段。控制面将指针从Kafka主题更改为到 Pulsar 主题,并在Zookeeper中更新状态。生产者在确认更新成功后,将开始向新的主题发送消息。
- 接下来将来到完成阶段。控制平面将状态更新为成功,生产者将停止监控Zookeeper。
然而,如果在任何阶段出现问题,如生产者无法停止发送消息或控制平面无法成功更新Zookeeper,或丢失连接等,系统将回滚到之前的状态。在这些情况下,我们要做的是回滚到 Kafka 主题,限制生产的数量,并且停止迁移,并且将状态更新为失败。控制平面和生产者将根据当前迁移状态决定是恢复还是中止操作。
生产者切换的细节
![]()
- 在准备阶段我们的生产者仍然指向Kafka。
- 在请求切换的状态时我们的生产者指针已经移动到Pulsar的主题,但生产还没有开始,它在等待提交。
- 一旦提交成功,生产指针将会在 Pulsar 主题上开始向前移动并开始在生产。
- 整个操作将被标记为成功完成。
![]()
如果出现失败,例如在请求步骤中,生产者指向了 Pulsar 上,但无法生产消息。这时候将重置切换,生产指针将回到 Kafka 主题,并开始只向 Kafka 发送消息。整个操作将被标记为完成,但状态为失败。
协调消费者切换
![]()
消费的切换是相当直接的。消费者由控制平面指定从哪里消费消息。从指定的消费 ID 开始消费,或者消费主题里面滞后的消息。一旦完成,控制平面将更新消费者主题 ID 并移至下一段,这个时候,消费者就可以发送切换了。
回滚策略
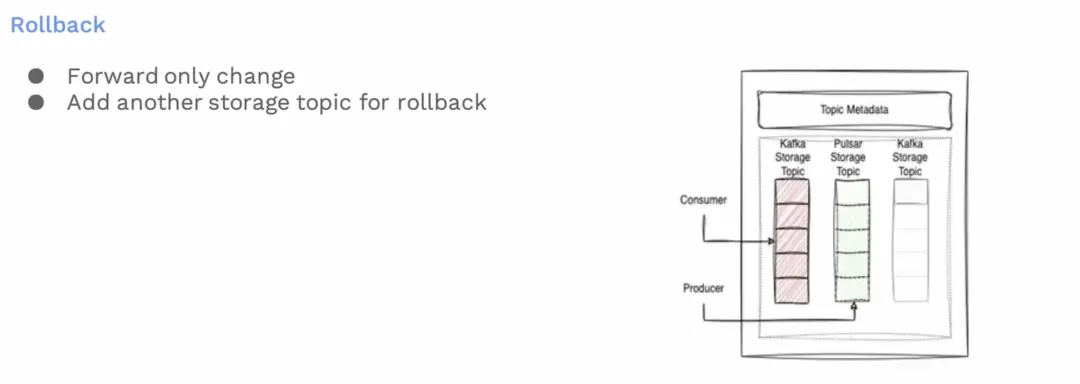
![]()
就故障回滚方面我们采取的策略,假设从 Pulsar 发现问题想要回滚到 Kafka,我们的策略规定不能回到之前的主题,而是必须添加一个新的 Kafka 存储段,并且移动生产指针,或者从 Pulsar 重新迁移一次到 Kafka。这是必要的,我们不能重复使用同一主题。我们本可以将指针从 Pulsar 移回例子中的Kafka 主题一,但这意味着 Pulsar 主题中的消息将被错误错乱,从而导致我们的用户遭受顺序性方面的损失。
因此,即使是回滚也意味着另一次变相的迁移。
额外收益
![]()
我们通过这种迁移策略获得了一些额外的好处。例如,我们现在可以更改主题的命名空间,这在 Pulsar 中本来是不可能的。我们甚至还可以利用这一特性,将主题从一个命名空间迁移到另一个命名空间。我们还可以在 Pulsar 中更新主题的分区数而不会失去消息的顺序性。这是目前任何消息队列都不能提供的。
我们还可以展示主题的使用情况,像一个时间轴一样,毕竟每个段都是被记录的。我们可以看到段1是在 Kafka 中,然后我们移动到 Pulsar,然后从 5 个分区扩容到 10 个分区等等。我们可以用它来看到主题在这段时间的自然演变。
最后,我们正在将 Varadhi 开源。我们现在正在重新审视 Varadhi,做一些彻底的改进。我们正在重写所有的模型,以解决我们在初版 Varadhi 中发现的一些架构漏洞,并希望将其贡献给开源社区。
我们会很高兴听到来自您的反馈。如果您有任何问题,可以联系 Pulsar 社区,或者直接联系我们。感谢大家的时间。