Apache Cloudberry™ (Incubating) 是 Apache 软件基金会孵化项目,由 Greenplum 和 PostgreSQL 衍生而来,作为领先的开源 MPP 数据库,可用于建设企业级数据仓库,并适用于大规模分析和 AI/ML 工作负载。
GitHub: https://github.com/apache/cloudberry
文章作者:陈亮,酷克数据售后工程师;整理:酷克数据
ZomboDB 是 PostgreSQL 的扩展组件,通过与 Elasticsearch 的集成,为数据库系统引入了高性能的全文检索与文本分析功能。我们对 ZomboDB 进行了兼容性改造与优化,使其能够支持 Apache Cloudberry,从而让 Cloudberry 拥有 Elasticsearch 丰富的全文检索与文本分析能力。通过简单的 SQL 语法,用户即可在已有的 Cloudberry 表上创建 ZomboDB 索引,实现高性能、可事务化的全文搜索。
ZomboDB 实际上是基于 Elasticsearch 外部索引的实现,它可以管理 Elasticsearch 集群上的索引,并确保在事务层面上保持数据与索引的一致性。
此外,ZomboDB 支持大多数 Cloudberry 的 SQL 操作,包括:CREATE INDEX、COPY、INSERT、UPDATE、DELETE、SELECT、ALTER、DROP、REINDEX、(auto)VACUUM 等。
工作原理
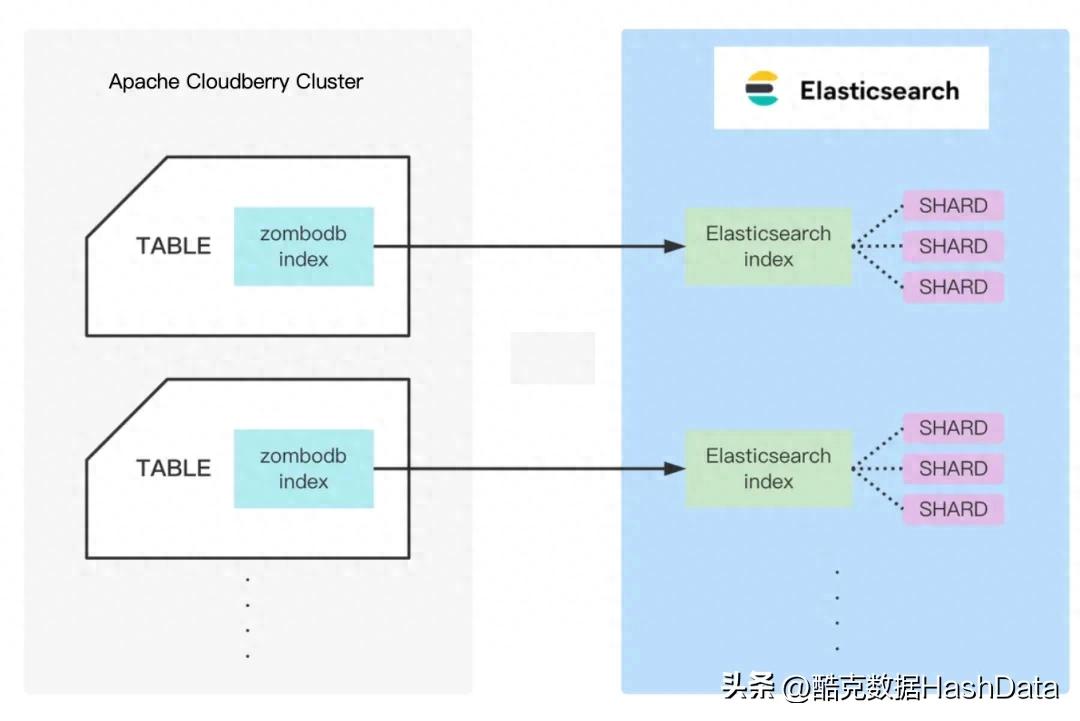
ZomboDB 通过连接 Cloudberry 集群与 Elasticsearch 集群,实现两者的数据同步与检索协作。无论两个集群是否位于同一主机,只需保证网络通信畅通即可正常运行。
Cloudberry 中的每一个 ZomboDB 索引实际上对应 Elasticsearch 中的一个 Index。当数据量较大时,为避免每个 Segment 扫描全量索引数据,ZomboDB 会将不同 Segment 的数据映射到 Elasticsearch 索引下的不同分片(Shard),从而提升并行扫描与查询性能。
创建索引和加载数据流程
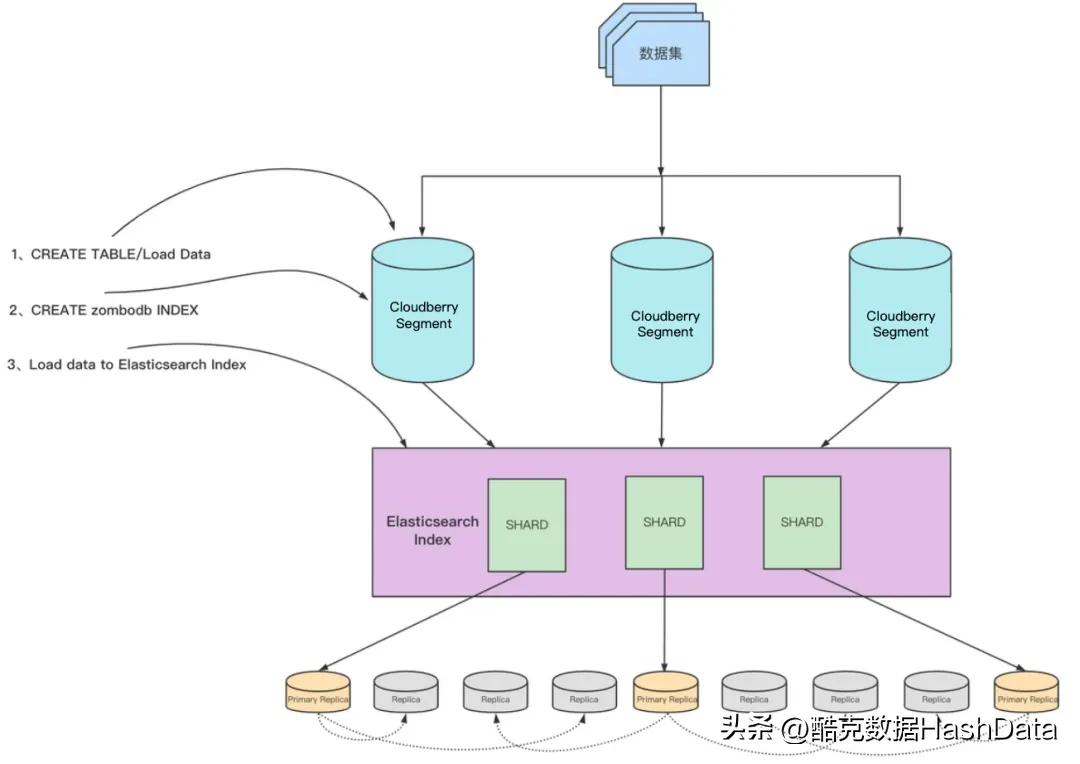
下图展示了数据表创建 ZomboDB 索引,并加载数据的大致流程。
整个过程都是在和 Cloudberry集群中的 Coordinator 节点进行通信和交互。
- 在 Cloudberry集群中创建数据表,并且加载相应的数据。
- 使用 CREATE INDEX 语法创建 ZomboDB 的索引。此时需要保证 Elasticsearch 的集群处于可用状态,并且网络和 Cloudberry集群互通。
- 创建的过程中,ZomboDB 会自动将表中已有的数据插入到 Elasticsearch 中对应的 index 里面,如果发生了错误,或者手动回滚事务,那么也会自动清理 ES 中的数据。
在索引创建完成后,后续有新的数据插入到表中,都会自动将数据插入到对应 Elasticsearch 的 index 里。
查询数据流程
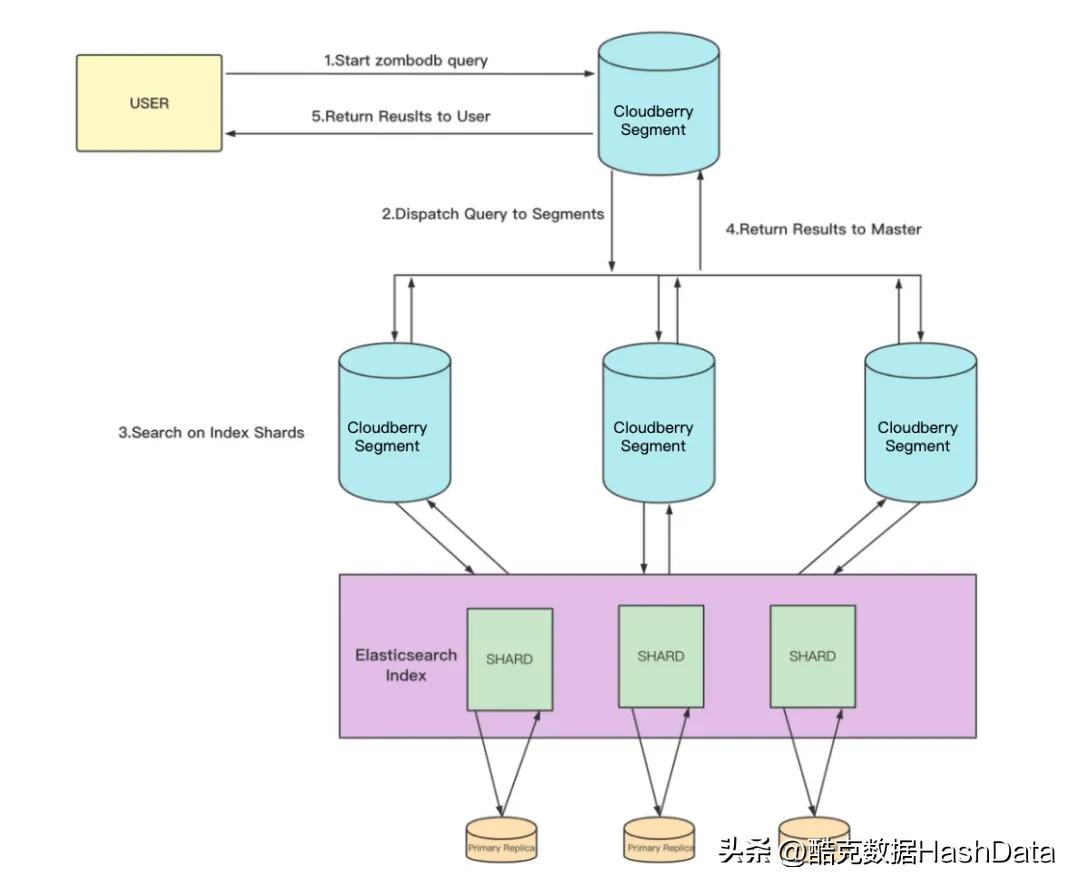
下图展示了存在 ZomboDB 索引的情况下,对数据进行查询的大致流程。
- 用户侧使用 ZomboDB 的查询语法,基于 ZomboDB 的索引进行查询。ZomboDB 的查询和普通的 select 基本上没有区别,只是需要使用 ZomboDB 特定的标识符 ==>。
- Cloudberry集群中的 Coordinator 节点将查询分发给各个 Segment。
- 每个 Segment 各自执行查询,只需要查询对应的 Elasticsearch 的 index 中某个 Shard 的数据。
- 每个 Segment 将查询的结果返回给 Coordinator 节点。
- Coordinator 节点收到 Segment 的结果,进行聚合或者其他操作,并返回给用户。
安装 ZomboDB 插件
注意:当前 ZomboDB 插件尚未开源,此安装方式适用于 HashData Lightning(基于 Apache Cloudberry)版本。
// 通过 psql postgres 进入数据库,创建 zombodb 扩展
postgres=# create extension zombodb;
// 出现如下结果表示安装成功
CREATE EXTENSION
安装 Elasticsearch
- 下载对应平台 elasticserch 安装包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.6.1-x86_64.rpm
- 安装 elasticsearch
yum -y install ./elasticsearch-8.6.1-x86_64.rpm
- 修改/etc/elasticsearch/elasticsearch.yml,设置 xpack.security.enabled 为 false
xpack.security.enabled: false
- 启动 elasticsearch
systemctl start elasticsearch
安装 elasticsearch-analysis-ik 中文分词插件
注意插件的版本必须与 elasticsearch 版本一致。上面的 elasticsearch 版本是 8.6.1,所以这里插件也要使用同样的版本。
有 2 种安装方式:
cd /usr/share/elasticsearch/bin
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v8.6.1/elasticsearch-analysis-ik-8.6.1.zip
- 从这个链接下载对应版本的安装包:https://github.com/medcl/elasticsearch-analysis-ik/releases
- 安装
mkdir /usr/share/elasticsearch/plugins/ik
unzip -d /usr/share/elasticsearch/plugins/ik ./elasticsearch-analysis-ik-8.6.1.zip
- 重启 elasticsearch
systemctl restart elasticsearch
Cloudberry 实现中文检索
- 创建一个名称是'myik'的 analyzer。
SELECT zdb.define_analyzer('myik', '{"tokenizer": "ik_max_word"}');
- 创建 domain
CREATE DOMAIN myik AS text;
- 创建测试表,注意这里列 c1 的数据类型要对应上面创建的 domain 名称。
create table zombodb_t1 (c1 myik);
- 创建索引
create index idx_zombodb_t1 on zombodb_t1 using zombodb((zombodb_t1.*)) with (url='http://localhost:9200/');
- 测试效果
gpadmin=# insert into zombodb_t1 values ('中文测试');
INSERT 0 1
gpadmin=# insert into zombodb_t1 values ('中 文测试');
INSERT 0 1
gpadmin=# select * from zombodb_t1 where zombodb_t1 ==> '中文';
c1
----------
中文测试
(1 row)
gpadmin=# select * from zombodb_t1 where zombodb_t1 ==> '中 文';
c1
-----------
中 文测试
(1 row)
gpadmin=# select * from zombodb_t1 where zombodb_t1 ==> '测试';
c1
-----------
中文测试
中 文测试
(2 rows)
创建 index 报错
在创建 index(例如 create index
idx_fulltext_client_extended_info)时,出现了以下错误信息:
ERROR: code=Some(429),
"error": {
"root_cause": [
{
"type": "es_rejected_execution_exception",
"reason": "rejected execution of coordinating operation [coordinating_and_primary_bytes=...]"
}
],
"type": "es_rejected_execution_exception",
"reason": "rejected execution of coordinating operation [coordinating_and_primary_bytes=...]",
"status": 429
}
从错误信息可以看出,Elasticsearch 在协调节点执行操作时因为内存压力过大而拒绝了请求(
es_rejected_execution_exception),导致索引创建失败。
解决方法:
- 修改/etc/elasticsearch/elasticsearch.yml, 添加如下参数。如果不指定,这个参数的默认值是 10%的 ES heap 内存大小。
indexing_pressure.memory.limit: 8g
- 重启 elasticsearch
systemctl restart elasticsearch
结语
通过将 ZomboDB 与 Apache Cloudberry 深度集成,用户能够在 MPP 架构下直接使用 Elasticsearch 的全文检索与中文分词能力,实现高性能的结构化与非结构化数据混合查询。这种融合方案不仅扩展了 Cloudberry 的应用边界,也为日志分析、智能检索、文本挖掘等场景提供了开源可行的新路径。
未来,随着社区的发展与多语言分词支持的增强,Cloudberry + ZomboDB + Elasticsearch 的组合将成为构建智能数据仓库与搜索分析平台的重要技术基石。