

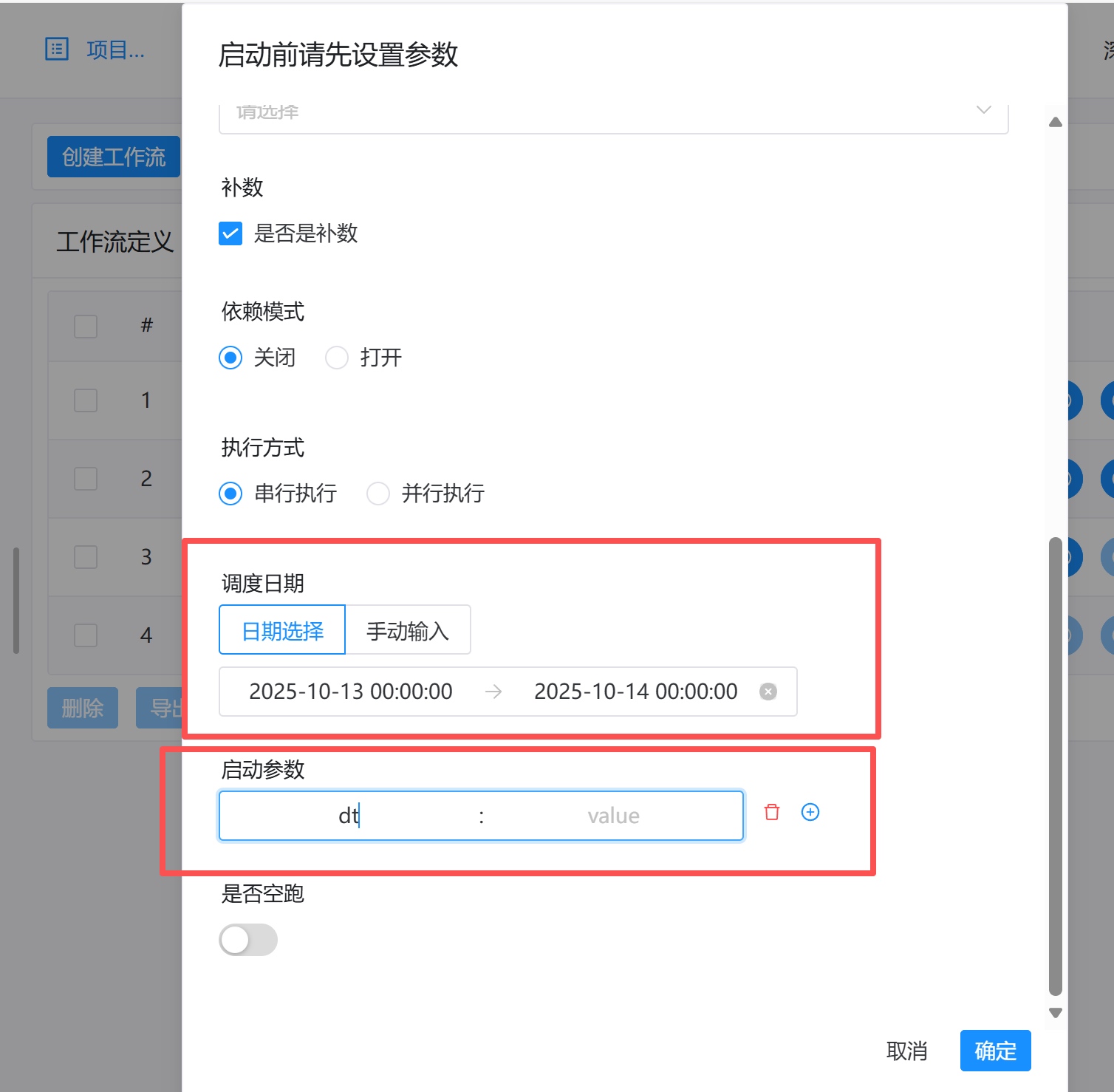
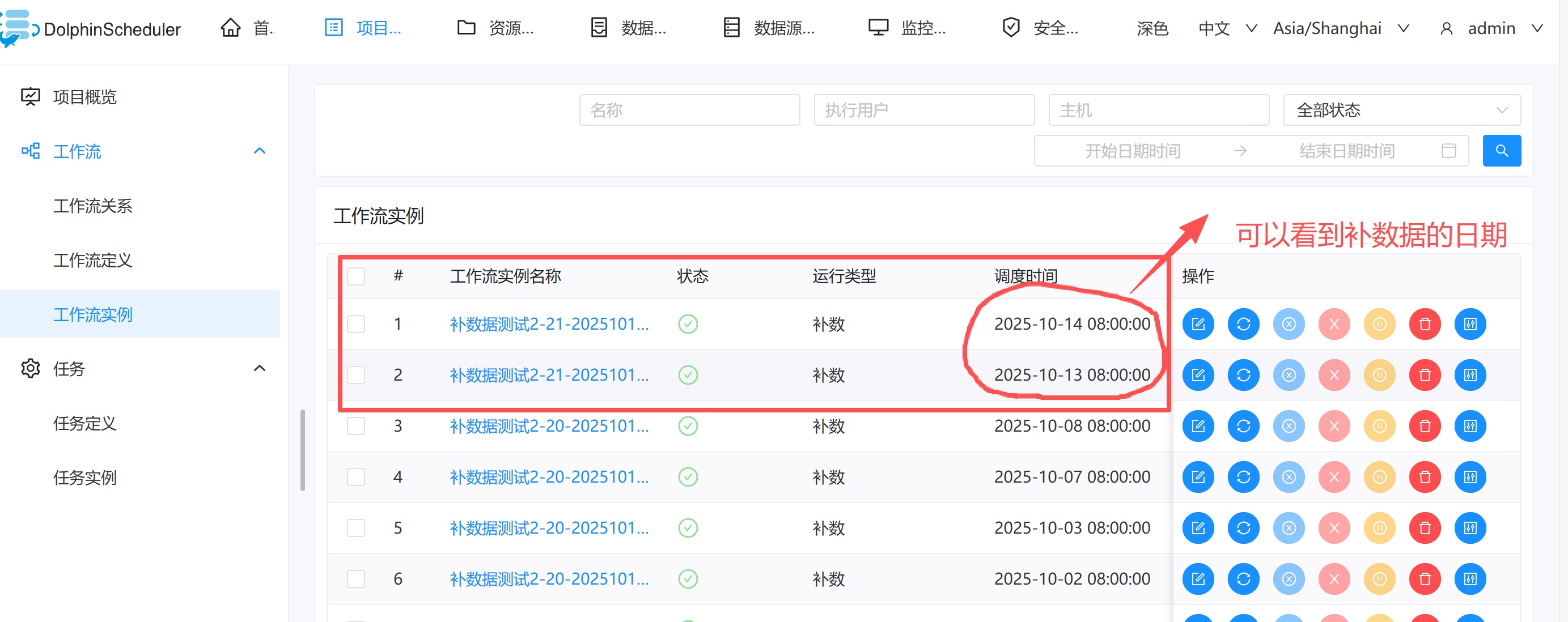


无需改动一行代码!看G行如何利用eBPF,实现全栈可观测性追踪
G行5年来在全栈可观测性建设方面的实践证明,零侵扰采集技术是破解云原生与信创环境下运维难题的关键,其平台通过全栈链路追踪和持续性能剖析,实现了从业务到基础设施的分钟级故障定位,有效保障了系统稳定性与业务连续性。为金融数字化转型中实现自主可控与高效运维提供成功范本。欢迎点击原文「链接」进行阅读。 摘要 应用上云、云原生化是企业全面数字化转型的必要技术基础,G行2020年启动全栈云平台建设,采用云原生集群架构为应用架构服务化改造提供平台支撑,也同步建设了云化系统的全栈可观测性能力: 在技术可控性方面:通过全栈调用链追踪能力,构建性能基线图谱,破解异构环境兼容性验证难题;基于零侵扰采集技术,规避传统插桩方案的安全合规风险,构建覆盖信创技术栈的统一监控范式。 在业务稳定性方面:建立业务指标-技术指标-资源指标三级关联机制,助力实现分钟级故障发现、定位与恢复;通过分布式推理服务链路追踪、剖析等能力,保障应用系统稳定运维。 背景与挑战 2020年以来,《金融行业信息化发展规划(2022-2025)》、《关于银行业保险业数字化转型的指导意见》等文件明确要求金融机构“实现关键核心技术自主可控”,202...