G行5年来在全栈可观测性建设方面的实践证明,零侵扰采集技术是破解云原生与信创环境下运维难题的关键,其平台通过全栈链路追踪和持续性能剖析,实现了从业务到基础设施的分钟级故障定位,有效保障了系统稳定性与业务连续性。为金融数字化转型中实现自主可控与高效运维提供成功范本。欢迎点击原文「链接」进行阅读。
摘要
应用上云、云原生化是企业全面数字化转型的必要技术基础,G行2020年启动全栈云平台建设,采用云原生集群架构为应用架构服务化改造提供平台支撑,也同步建设了云化系统的全栈可观测性能力:
在技术可控性方面:通过全栈调用链追踪能力,构建性能基线图谱,破解异构环境兼容性验证难题;基于零侵扰采集技术,规避传统插桩方案的安全合规风险,构建覆盖信创技术栈的统一监控范式。
在业务稳定性方面:建立业务指标-技术指标-资源指标三级关联机制,助力实现分钟级故障发现、定位与恢复;通过分布式推理服务链路追踪、剖析等能力,保障应用系统稳定运维。
背景与挑战
2020年以来,《金融行业信息化发展规划(2022-2025)》、《关于银行业保险业数字化转型的指导意见》等文件明确要求金融机构“实现关键核心技术自主可控”,2027年成为金融信创全面落地的硬性时间节点。
银行应用系统同步替换底层数据库、中间件、操作系统、服务器等全栈组件,对技术验证与业务连续性保障带来的压力巨大,在可观测性建设上主要面临如下挑战:
01、在容量预估和故障排查方面
调用链追踪落地难:传统调用链追踪的实现方式可能面临安全合规及稳定性诉求矛盾。APM或日志类方案需要对应用代码改造,落地困难且有合规隐患;NPM类方案需要对云内流量全量引流,开销巨大且数据质量差。
系统容量评估困难:需要高性能、零侵扰的性能评测手段,便于开发迭代过程中随时可以在不同硬件、操作系统、中间件、数据库环境下完成性能测试,为上线后的容量评估提供充足的参考数据。
生产环境性能剖析难:线上性能问题往往难以在测试环境复现,而生产环境中往往由于性能剖析工具缺乏、工具执行权限审批困难、应用进程需要重启、应用代码需要修改而无法获取关键现场数据。
02、在应用性能和业务性能指标方面
性能指标覆盖不全:仅从管理上要求开发项目组和技术产品供应商提供标准化的性能指标数据有很大的挑战,若能从技术上提供零侵扰的全栈黄金性能指标,将极大的降低管理难度。
APM调用链采集性能损耗:基于插码的APM调用链采集能力对应用的性能和稳定性影响不可控,通常不敢在生产环境开启,即使启用也通常会设置较低的采样率。
业务指标和技术指标难关联:传统BPM的引流手段在云环境下落地困难,导致业务指标仅能在云入口处采集,难以和云内应用组件及基础设施服务的技术指标关联。
指标、追踪、日志数据孤岛:不同采集工具的数据颗粒度不一致、数据标签不统一,关联分析低效。
03、在云基础设施可观测方面
基础服务相关故障定界困难:L4、L7云网关的转发链路无法追踪,分布式数据库在代理节点、计算节点、数据节点上的调用链路无法追踪,涉及到基础服务的性能问题难以定界。
微服务访问排障低效:多副本微服务相互的调用链比较复杂,对于概率性发生的性能问题,传统的抓包、找日志的方式极端低效,可能长达数周仍无进展。
跨区域、专线带宽用量难优化:云主机、容器Pod的IP动态性高,跨区域/跨可用区/专线流量使用传统方式采集分析难以和云资源、容器服务关联,带宽利用效率很难分析。
G行全栈可观测平台建设
面对可观测性建设各方面的挑战,G行选择采用基于零侵扰解决方案建设全栈可观测平台,能够零侵扰采集业务语义、系统调用、网络转发、文件读写调用链,并通过收集和关联服务自身的日志链路数据实现调用链的全覆盖。与传统技术方案相比,G行建设方案优势如下:
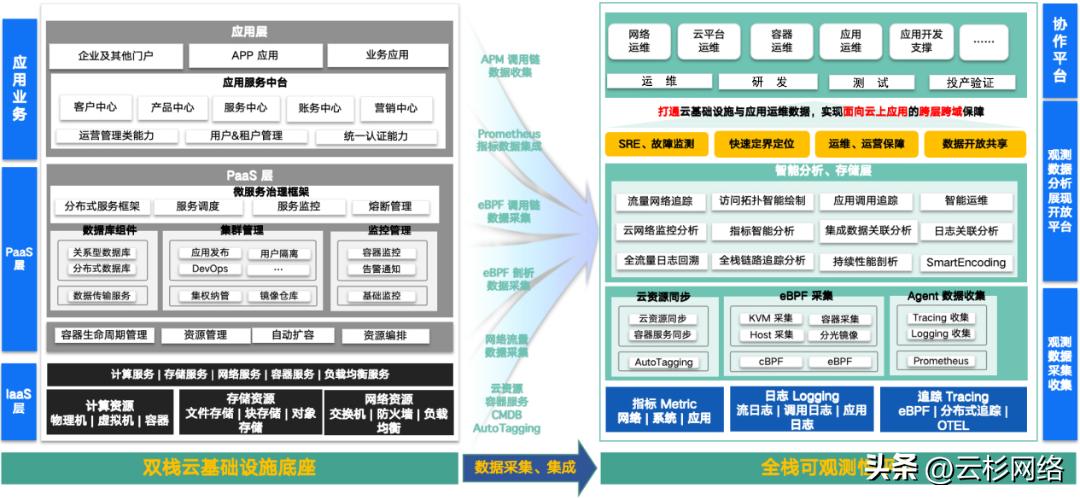
G行全栈观测平台的能力主要包括“业务全景拓扑、全栈调用链追踪、持续性能剖析、跨可用区、Agent资源管理”等五方面,平台架构如下图所示:
![]()
图1 G行全栈可观测性平台
如上图所示,G行全栈观测平台各方面功能介绍如下:
01、全景业务拓扑
全景覆盖:覆盖容器、云主机、物理机。
零侵扰业务语义采集:零侵扰解析Payload中的业务语义。
自动化业务语义标注:通过业务语义标注技术,自动标注云资源、容器服务、CMDB等语义标签,从而自动生成全景拓扑。
02、全栈链路追踪
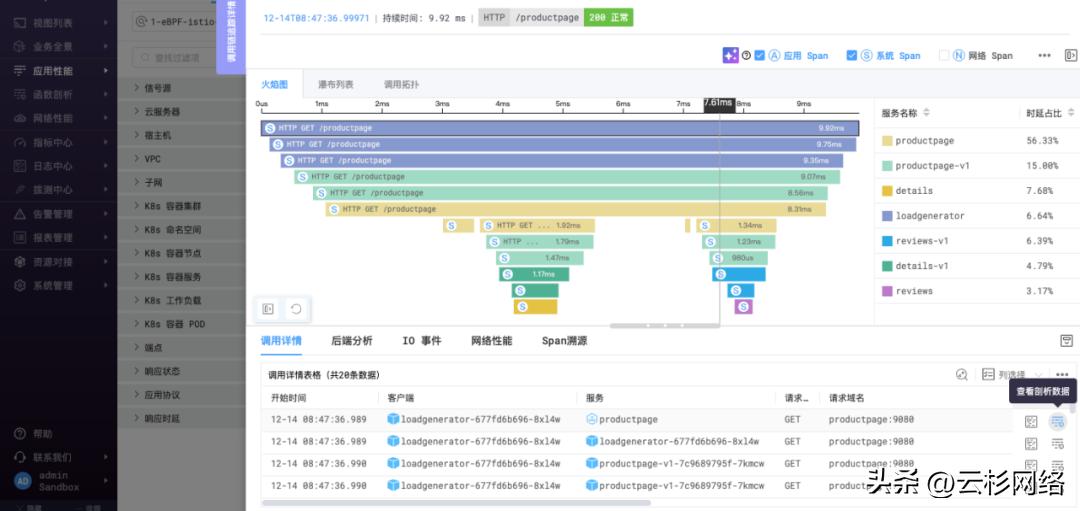
![]()
图2 全栈调用链追踪能力
上图展示了全栈观测平台的调用链追踪页面,其核心的功能特点包括:
零侵扰调用链追踪:基于零侵扰采集能力,无需改变任何代码、无需重编译任何代码、无需重启任何进程,实现了分布式调用链的零侵扰追踪,避免了APM、日志方案中的侵入性问题。
应用、系统、网络全栈链路:自动关联每一笔交易在应用进程、系统调用、网络传输中的Span。
关联瓶颈文件读写操作:自动关联瓶颈文件读写操作,快速定界Nginx静态资源读取、数据库索引文件及数据文件读写相关的业务性能抖动。
深入关联网络性能数据:自动关联每个调用前的DNS解析、TLS握手、TCP握手性能,快速分析网络建连时延、系统协议栈响应时延、网包重传、协议栈零窗等行为对应用调用性能的影响。
深入关联进程内的瓶颈函数:自动关联系统Span与应用进程的On-CPU、Off-CPU、Mem-Alloc、Mem-Inuse等函数粒度性能剖析数据。
多种展示形式:提供开发人员习惯的火焰图、瀑布列表展示形式,同时也提供网络、系统团队习惯的拓扑图展示形式。
03、持续性能剖析
![]()
图3 持续剖析页面
上图展示了全栈观测平台的持续剖析页面,其核心的功能特点包括:
零侵扰、热加载:基于零侵扰剖析技术,无需改变任何代码、无需重编译任何代码、无需重启任何进程,可随时对生产环境中的性能问题进行剖析。
全栈函数:支持展示业务函数、库/框架函数、语言运行时函数、Linux共享库函数、Linux内核函数、NVIDIA CUDA函数的资源消耗。
低资源开销:以On-CPU为例,整机开启仅需消耗1%计算资源,让性能剖析数据能够被持续采集,从而不用担心遗漏难以复现的线上问题的现场数据。
多语言支持:支持JVM虚拟机语言,Python等解释型语言,Golang、C/C++、Rust等编译型语言。
04、多可用区部署架构
G行双栈云部署在多个区域和可用区,银行系统由于其高可用要求运行在多个可用区上。为了呈现应用系统业务的全景拓扑,要求可观测性平台能够呈现多个可用区的观测数据。
![]()
图4 多可用区部署架构
在上图中,每个可用区内的采集Agent仅会将观测数据发送到本可用区的数据节点集群中,消除了数据的跨可用区传输,从而避免了跨可用区的专线带宽开销。另一方面,所有可用区的数据节点构成了一个松耦合的集群,全景拓扑、调用链追踪的查询请求会同时发送到所有可用区,每个可用区将本地的聚合计算结果回传,从而有效降低了查询期的跨可用区带宽消耗。
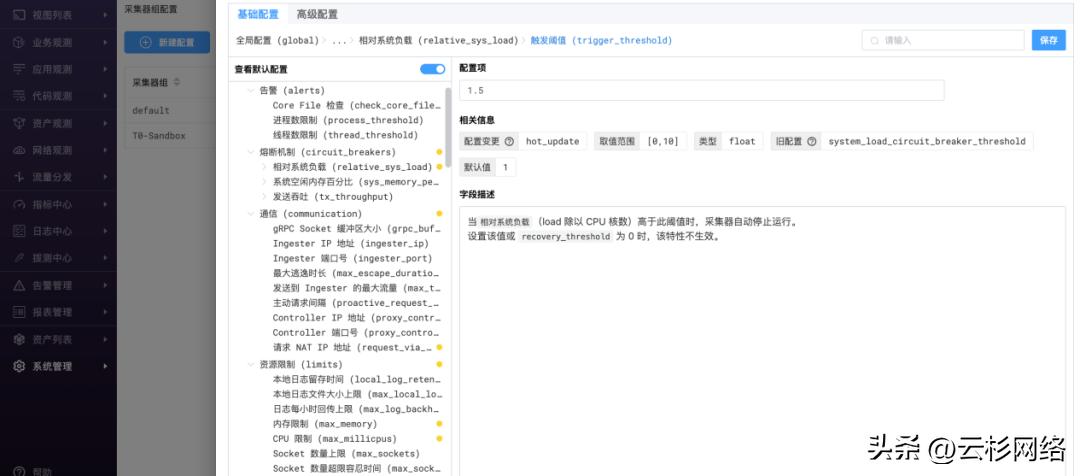
05、Agent的资源限制、自监控和熔断能力
下图中展示了全栈观测平台中Agent自身丰富的资源限制、自监控和熔断能力,这些能力保障了Agent的高效运转,以及在发生最恶劣情况下Agent能够进入熔断状态以避免影响业务运行。
![]()
图5 全栈观测平台Agent的资源限制、自监控和熔断能力
总结和未来展望
随着银行数字化转型进入新的阶段,全栈观测性在提升系统稳定性、保障业务连续性方面将发挥更加重要的作用。全栈可观测性不仅为传统系统引入了高效的监控手段,而且成功解决了多团队协作中的数据孤岛问题,提升了故障定位、性能优化与资源管理的工作效率。
展望未来,随着大模型智能体技术的发展,全栈可观测性平台的应用场景将进一步扩展,大模型的智能分析能力将彻底打破传统运维中因知识和精力瓶颈带来的限制,并在性能调优、容量预估和智能化故障检测方面提供更高效的支持,以及更加精细化和实时的风险防控。