
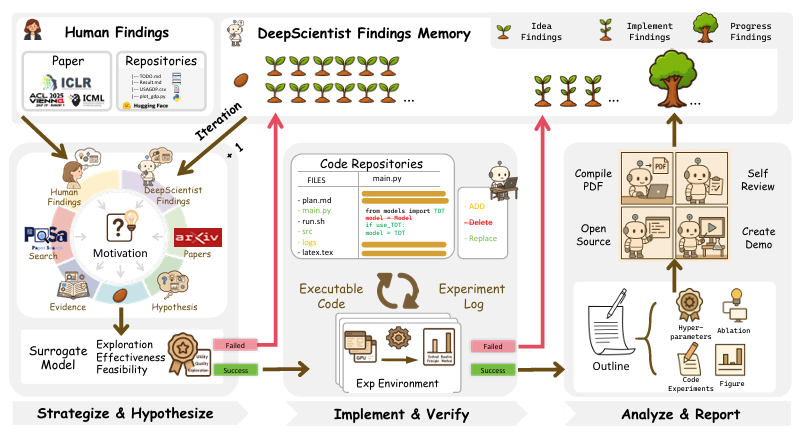

大量 “垃圾” 数据影响大语言模型推理能力
一项新研究表明,大语言模型(LLM)在持续接触无意义的在线内容后,可能会出现显著的性能下降。这项研究表明,这些模型的推理能力和自信心都受到影响,引发了对它们长期健康的担忧。研究团队来自多个美国大学,提出了 “LLM 脑衰退假说”,借鉴了人类在过度接触无脑在线内容时可能造成的认知损害。 为验证这一理论,研究人员进行了控制实验,使用2010年的 Twitter 数据。他们训练了四个较小的模型,包括 Llama3-8B-Instruct 和 Qwen 系列模型,采用不同比例的 “垃圾” 数据与高质量的控制数据进行对比。 研究者们以两种方式定义 “垃圾” 数据。第一种方法(M1)通过互动量来筛选,认为短于30个字且高互动(超过500个赞、转发或评论)的帖子为垃圾内容,而长于100个字但互动少的帖子则作为控制内容。第二种方法(M2)则使用 GPT-4o-mini 根据内容质量进行排序,标记阴谋论、夸大说法和吸引眼球的标题为垃圾内容,更深思熟虑的材料则被视为高质量内容。 研究发现,随着垃圾数据比例的增加,模型在推理准确性上的表现急剧下降。例如,在 ARC 挑战基准测试中,推理准确率从74.9% 降...