
百度智能云开源视觉理解模型 Qianfan-VL
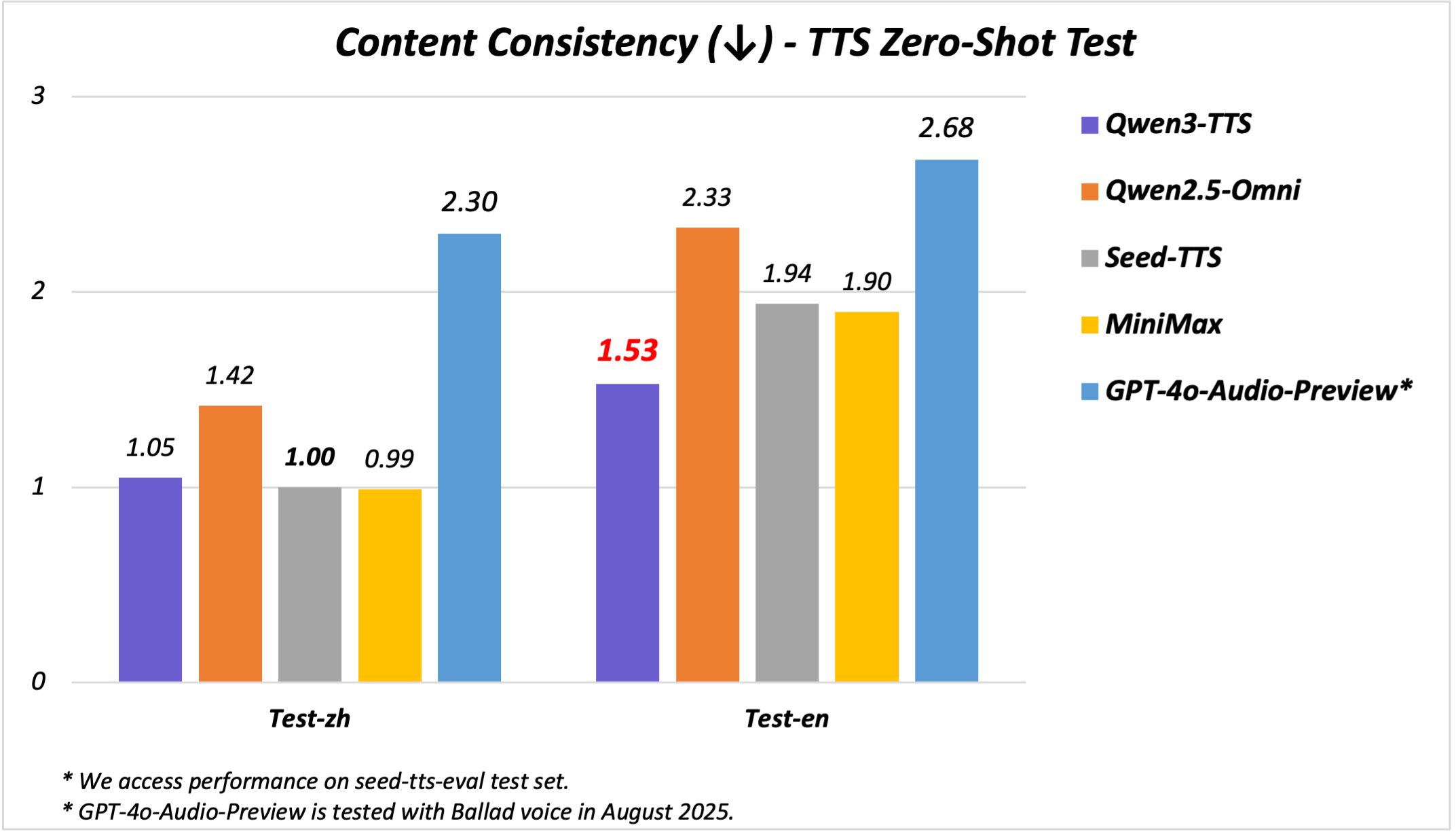
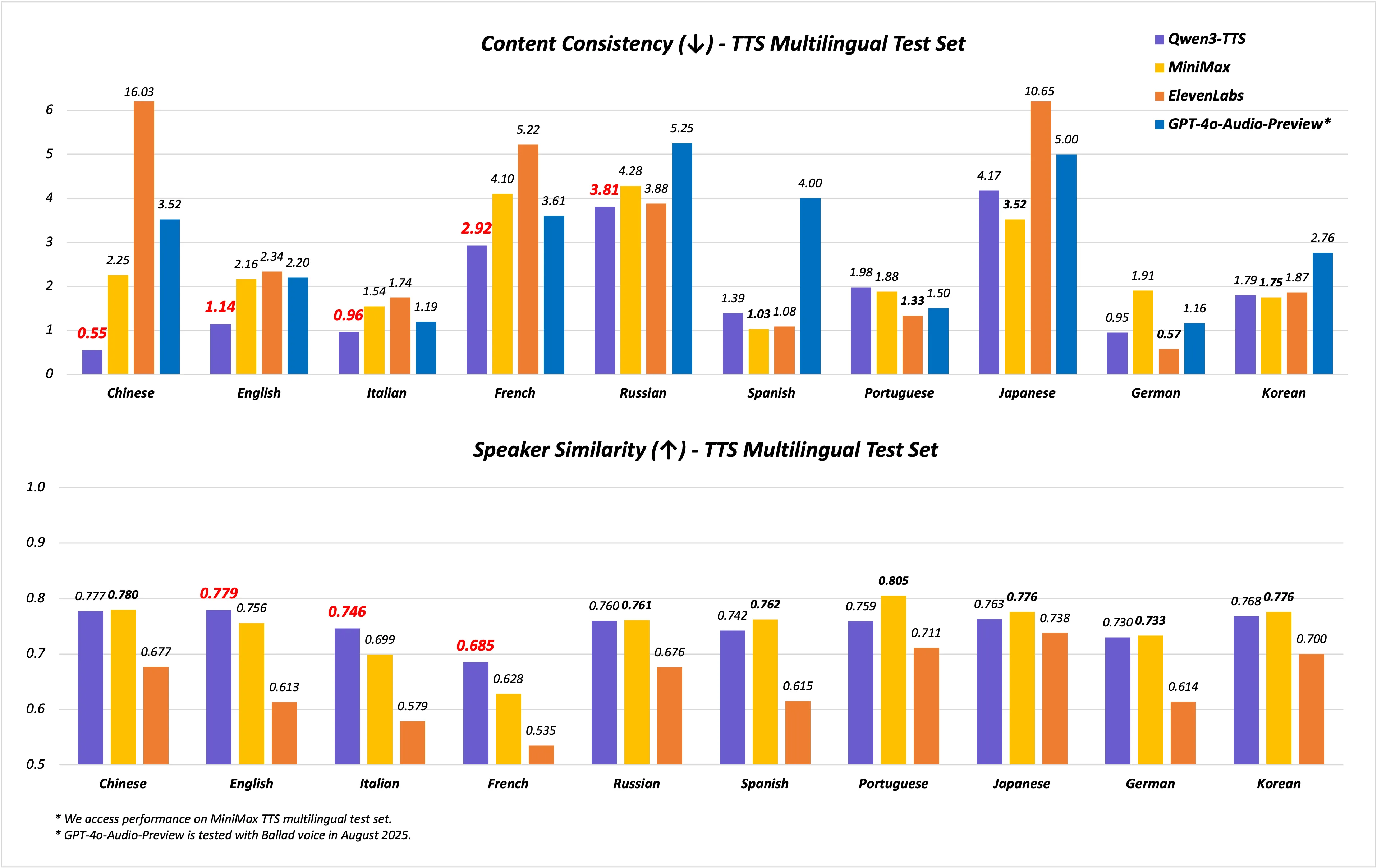
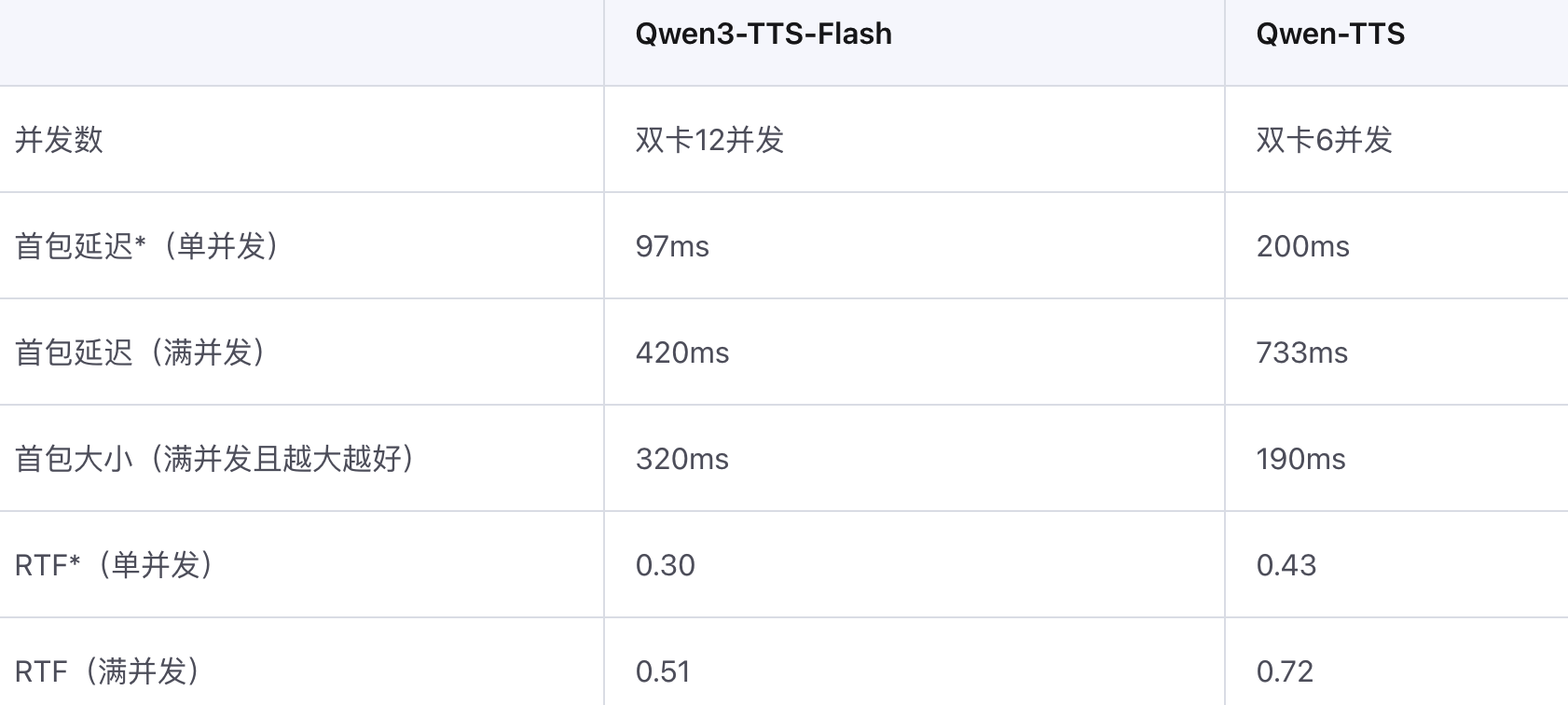
百度智能云千帆宣布开源发布全新视觉理解模型——Qianfan-VL。该系列包含3B、8B和70B三个尺寸版本,是面向企业级多模态应用场景,进行了深度优化的视觉理解大模型。 公告称,Qianfan-VL不仅具备出色的基础通用能力,还针对产业落地中的高频需求,如OCR和教育垂直场景做了专项强化,使其在实际应用中表现更加卓越。即日起至10月10日,企业用户和开发者可在百度智能云千帆平台免费体验8B、70B模型。 Qianfan-VL 系列模型基于开源模型进行开发,并在百度自研昆仑芯P800上完成全流程计算任务。具备三大特点: 多尺寸模型满足不同场景需求:提供3B、8B、70B三种规格的模型,让不同规模的企业和开发者都能找到合适的解决方案。 提供思考推理能力:8B和70B模型支持通过特殊token激活思维链能力,覆盖复杂图表理解、视觉推理、数学解题等多种场景。 OCR与文档理解能力增强:主打OCR全场景识别和复杂版面文档理解两大特色能力,在多项基准测试中表现优异,为企业级应用提供高精度的视觉理解解决方案。 一些测评结果如下: 更多详情可查看官方公告。