工信部通报:29 款 APP 存在侵害用户权益行为
工信部发布“关于侵害用户权益行为的APP通报(2025年第5批,总第50批)”指出,近期,经组织第三方检测机构进行抽查,共发现29款APP存在侵害用户权益行为,现予以通报。上述APP应按有关规定进行整改,整改落实不到位的,将依法依规组织开展相关处置工作。 附件:工业和信息化部通报存在问题的APP名单
中文互联网基础语料3.0正式发布。这一新版本的数据量达到了惊人的120GB,旨在为大模型训练和人工智能的进一步发展提供可靠的数据支持。
中文互联网基础语料3.0的发布,是在中央网信办的指导下,由中国网络空间安全协会与国家互联网应急中心等单位协同合作的成果。
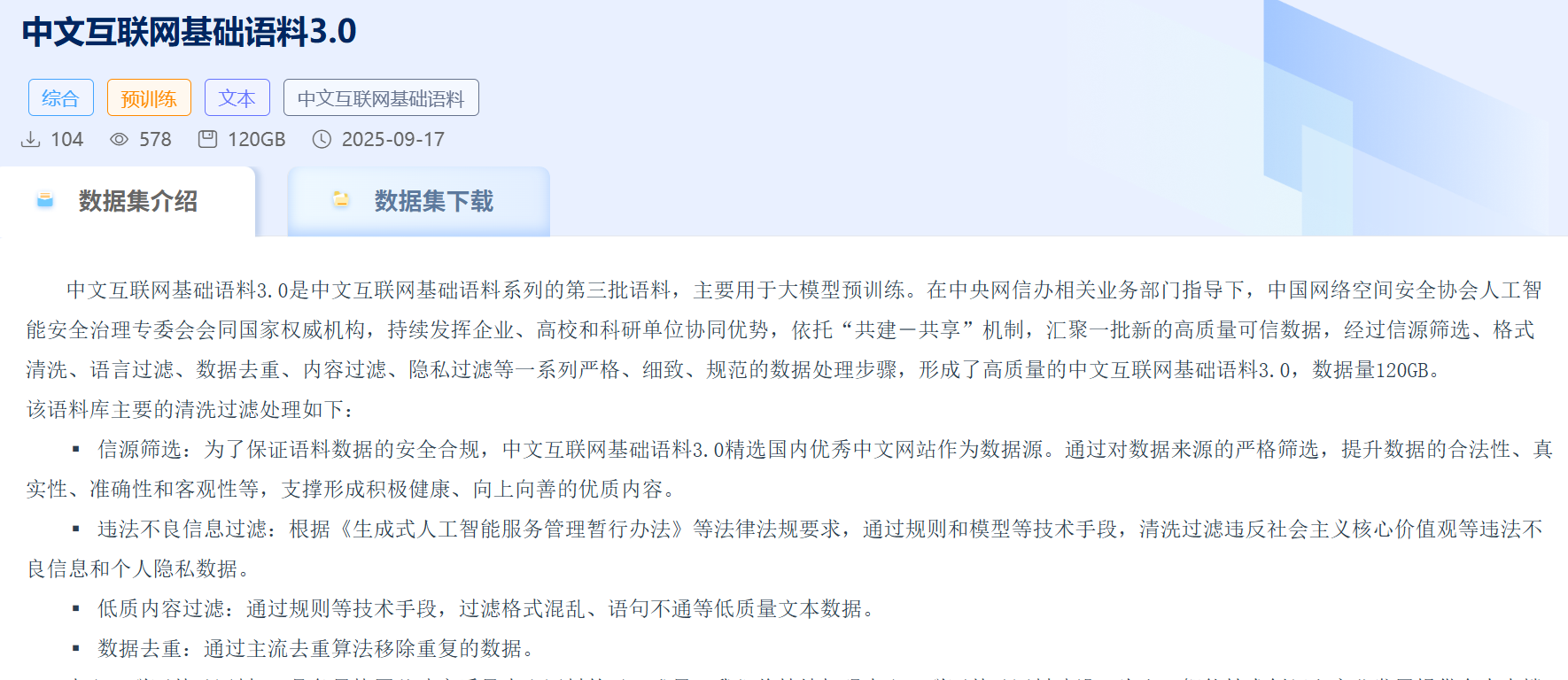
此次语料的开发与构建,得益于企业、高校和科研单位之间的紧密合作,充分利用了网安协会人工智能安全治理专委会建立的语料共建共享机制。与前两版相比,3.0版本在信源范围上进行了扩大,进一步提升了数据的质量。
在数据处理方面,语料3.0经过了严格的信源筛选、内容过滤和数据去重等一系列细致的加工处理措施。这些措施确保了发布的数据更加可信,有助于过滤掉违法和不良信息,为人工智能的研究和应用提供一个更为健康的环境。
用户可以通过登录中国网络空间安全协会网站,点击 “中文互联网语料资源平台” 链接,注册并认证后下载相关语料。该负责人表示,中文互联网基础语料3.0的推出标志着各界对高质量中文语料的共同努力与成果,未来还将继续加强中文互联网基础语料的建设,以支撑人工智能技术的创新与产业发展。

微信关注我们
转载内容版权归作者及来源网站所有!
低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Rocky Linux(中文名:洛基)是由Gregory Kurtzer于2020年12月发起的企业级Linux发行版,作为CentOS稳定版停止维护后与RHEL(Red Hat Enterprise Linux)完全兼容的开源替代方案,由社区拥有并管理,支持x86_64、aarch64等架构。其通过重新编译RHEL源代码提供长期稳定性,采用模块化包装和SELinux安全架构,默认包含GNOME桌面环境及XFS文件系统,支持十年生命周期更新。
Sublime Text具有漂亮的用户界面和强大的功能,例如代码缩略图,Python的插件,代码段等。还可自定义键绑定,菜单和工具栏。Sublime Text 的主要功能包括:拼写检查,书签,完整的 Python API , Goto 功能,即时项目切换,多选择,多窗口等等。Sublime Text 是一个跨平台的编辑器,同时支持Windows、Linux、Mac OS X等操作系统。
WebStorm 是jetbrains公司旗下一款JavaScript 开发工具。目前已经被广大中国JS开发者誉为“Web前端开发神器”、“最强大的HTML5编辑器”、“最智能的JavaScript IDE”等。与IntelliJ IDEA同源,继承了IntelliJ IDEA强大的JS部分的功能。
扫码在手机上查看文章
扫描二维码,手机阅读更方便
有任何问题或合作意向欢迎联系我们
Email: 99873273@qq.com
QQ: 99873273