
蚂蚁百灵大模型团队开源 MoE 大模型 Ling-flash-2.0
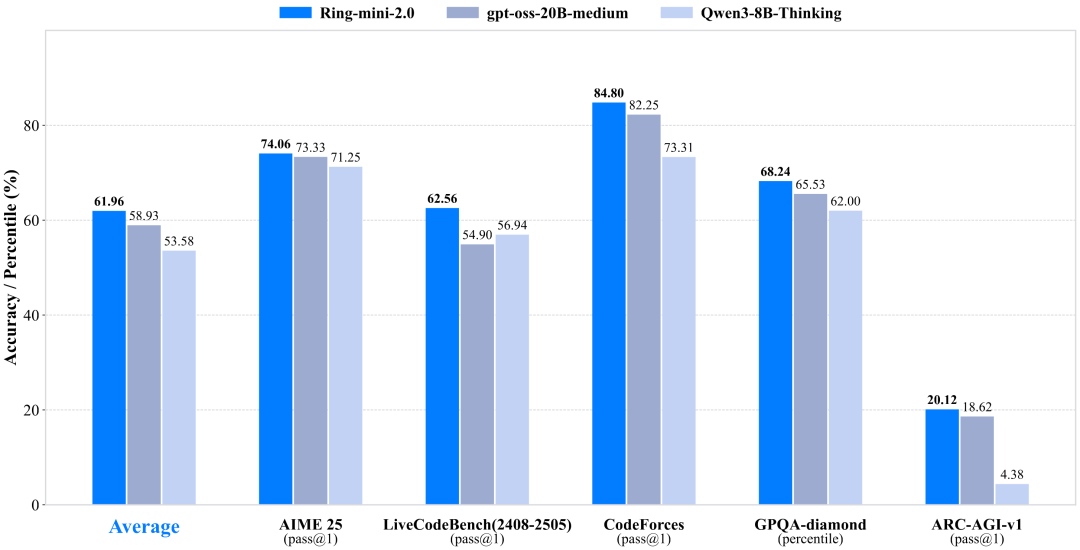
蚂蚁百灵大模型团队正式开源其最新 MoE 大模型 ——Ling-flash-2.0。 作为 Ling 2.0 架构系列的第三款模型,Ling-flash-2.0 以总参数 100B、激活仅 6.1B(non-embedding 激活 4.8B)的轻量级配置,在多个权威评测中展现出媲美甚至超越 40B 级别 Dense 模型和更大 MoE 模型的卓越性能。 据介绍,Ling-flash-2.0 在仅激活 6.1B 参数的前提下,实现了对 40B Dense 模型的性能超越,用最小激活参数,撬动最大任务性能。 为此,团队在多个维度上 “做减法” 也 “做加法”: 1/32 激活比例:每次推理仅激活 6.1B 参数,计算量远低于同性能 Dense 模型 专家粒度调优:细化专家分工,减少冗余激活 共享专家机制:提升通用知识复用率 sigmoid 路由 + aux-loss free 策略:实现专家负载均衡,避免传统 MoE 的训练震荡 MTP 层、QK-Norm、half-RoPE:在建模目标、注意力机制、位置编码等细节上实现经验最优 最终结果是:6.1B 激活参数,带来约 40B Dense...