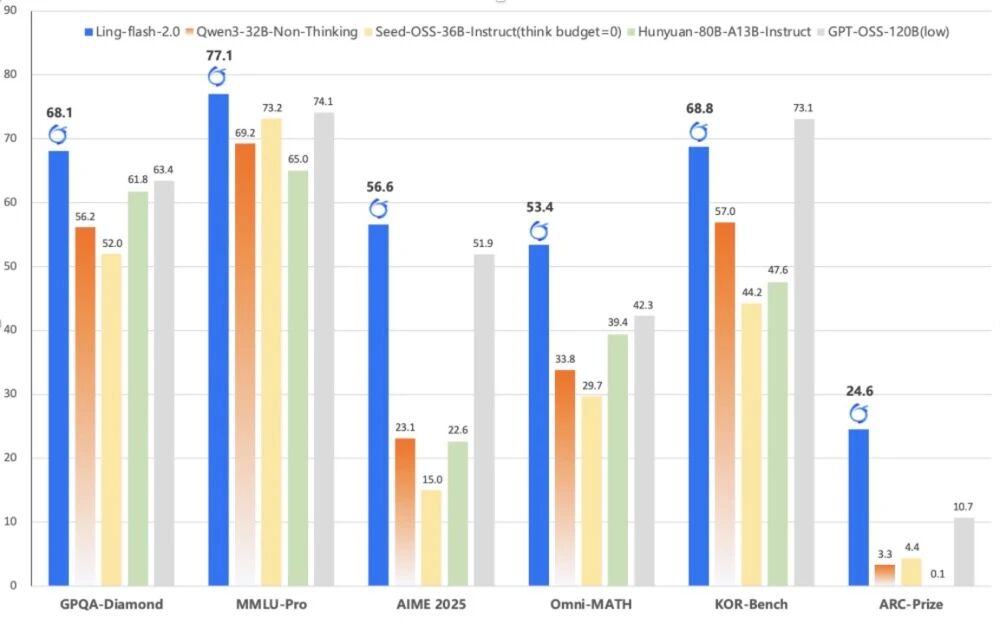
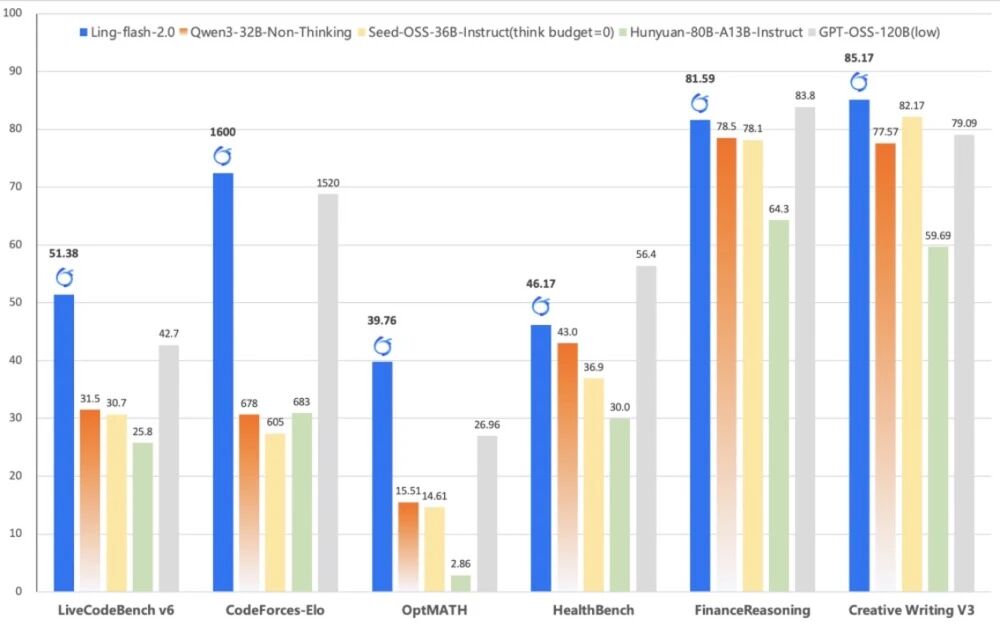
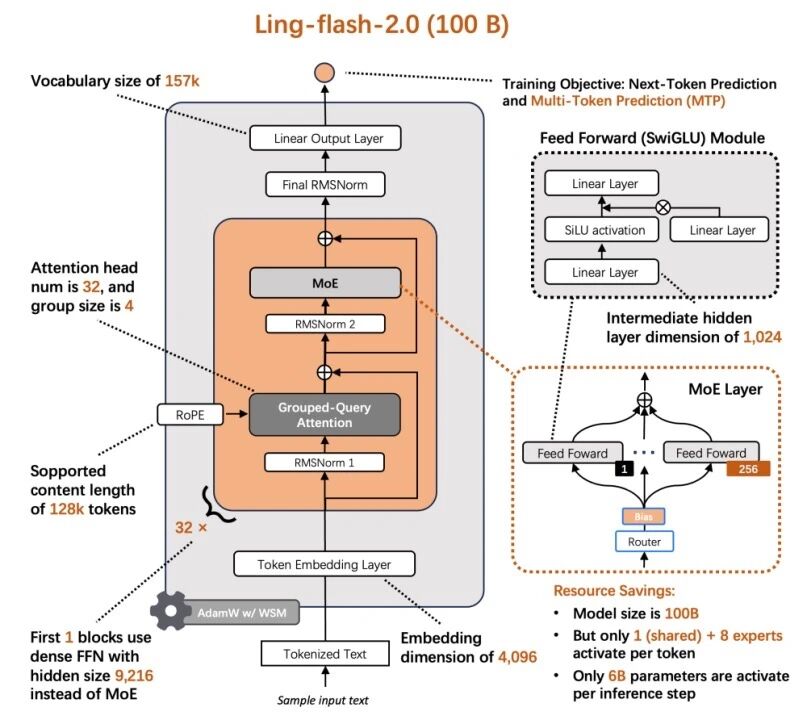

华为发布全球首个通算超节点
在华为全联接大会2025上,华为轮值董事长徐直军正式发布了全球首个通算超节点华为 Taishan 950 SuperPoD,计划2026年一季度上市。 徐直军称,其将能够彻底取代各种应用场景的大型机和小型机以及Exadata数据库一体机,将成为各类大型机、小型机的终结者。 徐直军指出:“算力过去是,未来也将继续是人工智能的关键,更是中国人工智能的关键”。他认为,超节点在物理上由多台机器组成,但逻辑上以一台机器学习、思考、推理。 此外,华为发布的最新超节点产品 Atlas 950 SuperPoD,算力规模8192卡,预计于2026年四季度上市。Atlas 960 SuperPoD 算力规模 15488 卡,预计 2027 年四季度上市。 基于超节点,华为同时发布了全球最强超节点集群,分别是Atlas 950 SuperCluster和 Atlas 960 SuperCluster,算力规模分别超过50万卡和达到百万卡。