关键词: 大数据、数据调度、工作流、批量停止
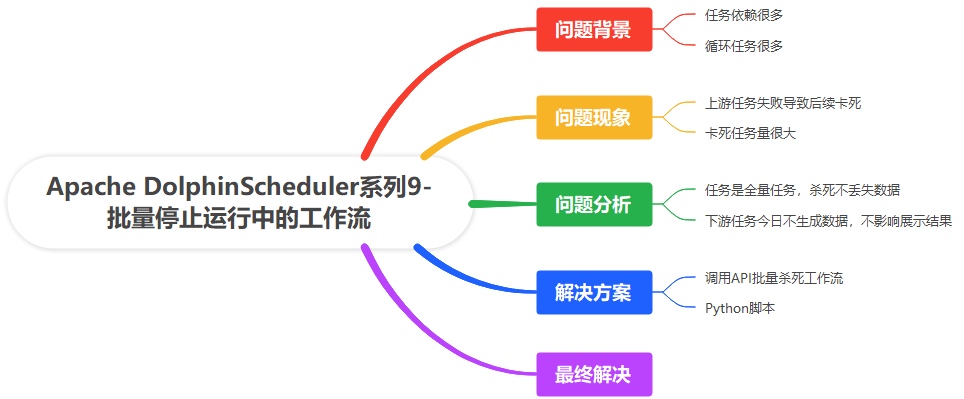
整体说明
在调研了 DolphinScheduler 之后,在项目上实际使用了一段时间,遇到了任务过多僵死的问题,解决思路分享如下。
![]()
问题背景
- 任务依赖很多:从下图可以看出,有些任务的后续依赖很多,一旦失败,后续任务都得等待。这样就很容易导致后续任务被堵死。
![]()
- 循环任务很多,有很多任务本身是循环调用的其他任务的任务,会不停生成任务,循环任务本身也是任务,这就有可能导致任务堵死。
![]()
问题现象
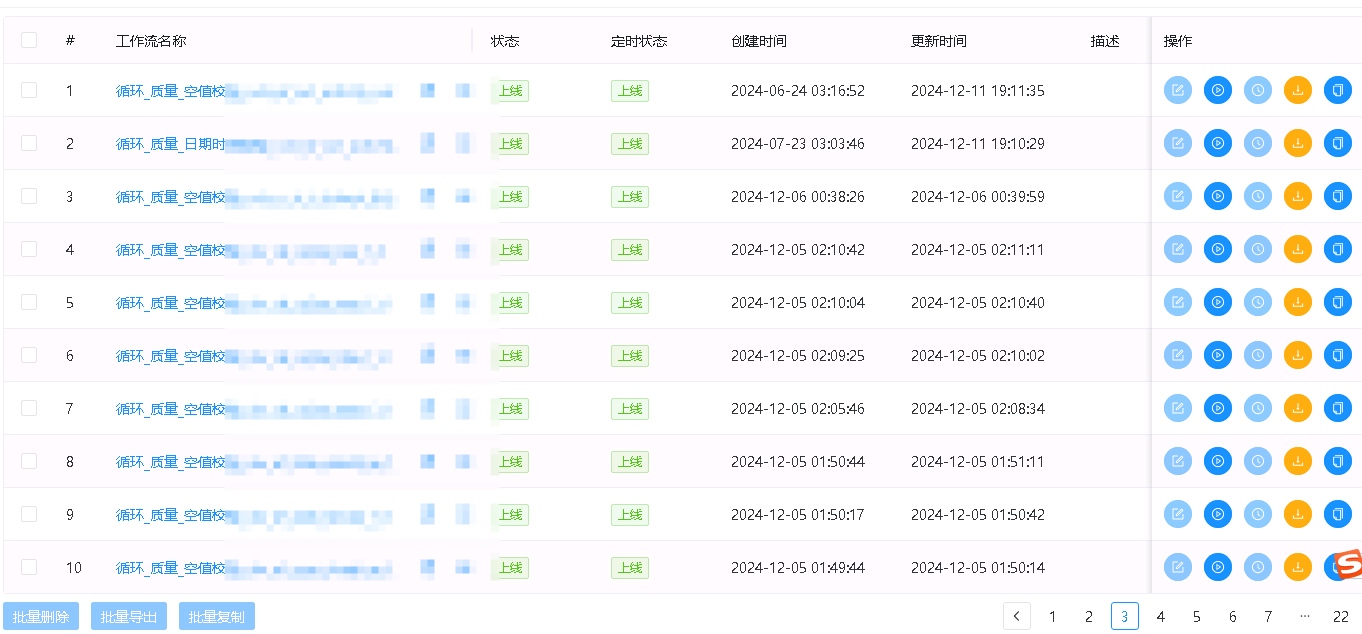
就是很多任务,都在运行中的状态,但是就是不执行,因为他们占用了各自任务组的上限,导致卡死。当任务积累到一定程度,手工去杀死,太慢了,而且真的很累。
问题分析
我们现在就是要杀死这些任务,但是有一些要注意的点:
- 任务是全量任务,杀死不丢失数据: 只有全量任务,今天才能随意的去杀死,如果是增量的,就需要手工单独处理
- 下游任务今日不生成数据,不影响展示结果:下游的任务,或者说给客户展示的数据,这种高风险数据,不会因为今天的任务被杀死,而影响展示效果,数据一天不更新,不影响最终结果
解决方案
- 调用API批量杀死工作流:DolphinScheduler 是自带了很多的 API 接口的,可以批量新建或者停止工作流
- Python脚本:所以写了个脚本来完成这个事
脚本名称:dolpschedule-kill.py
# -*- coding: utf-8 -*-
import requests
# 项目环境,没法安装 python3 ,所以这个是 python2.7 的代码
# 配置信息
BASE_URL = "http://XXX.XXX.XXX.XXX:12345/dolphinscheduler"
# 项目编码
# 查询后台数据库,或者页面F12 - 项目管理 - 项目列表 - 项目编码
PROJECT_CODE = "12194663850176"
# 1. 获取 Token
# 登录页面 - 安全中心 - 令牌管理 - 创建令牌
token = "6bff15e17667d95fdffceda08a19cc6c"
# 2. 获取正在运行任务列表
def get_running_tasks(token, pageNo=1, pageSize=10):
headers = {"token": token}
task_list_url = "{0}/projects/{1}/process-instances?pageNo={2}&pageSize={3}&stateType=RUNNING_EXECUTION".format(
BASE_URL, PROJECT_CODE, pageNo, pageSize)
resp = requests.get(task_list_url, headers=headers)
return [item['id'] for item in resp.json()['data']['totalList']]
# 3. 批量停止任务
def batch_stop_tasks(token, task_ids):
headers = {"token": token}
for task_id in task_ids:
stop_url = "{0}/projects/{1}/executors/execute?processInstanceId={2}&executeType=STOP".format(
BASE_URL, PROJECT_CODE, task_id)
resp = requests.post(stop_url, headers=headers)
print("Task {0} stopped: {1}".format(task_id, resp.status_code))
# 主流程
if __name__ == "__main__":
# 每次执行,杀死 100 个任务,可调整
running_tasks_ids = get_running_tasks(token, pageNo=1, pageSize=100)
print("Found {0} running tasks".format(len(running_tasks_ids)))
batch_stop_tasks(token, running_tasks_ids)
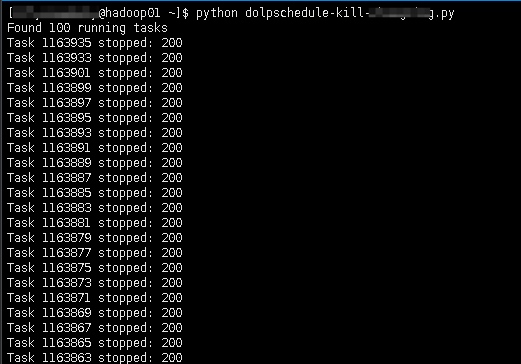
每个任务返回 200 ,说明执行任务成功
![]()
最终解决
最终,僵死的工作流全部被我杀死了,不过有时候会有一些僵死的任务实例(不是工作流)存在,这个没法用接口杀死。只能在后台修改,可以看我之前的文章 《DolphinScheduler 6 个高频 SQL 操作技巧》 解决无法被杀死的僵死任务实例。
原文链接:https://blog.csdn.net/pengpenhhh/article/details/149134569