TL;DR
代码量: DoytoQuery << SpringDataJPA/MyBatis-plus < jOOQ << SpringJdbc
查询性能:SpringJdbc > DoytoQuery > jOOQ >>> SpringDataJPA > MyBatis-plus
测试代码:https://github.com/f0rb/java-orm-comparison
介绍
本文基于几个常用的动态查询场景对比了基于对象查询映射(Object Query Mapping, OQM)方法的框架DoytoQuery与常用ORM框架(Spring Data JPA、Spring JDBC、jOOQ、MyBatis-plus)的代码量和查询性能。
实验设计
本实验旨在评估 DoytoQuery 与其他主流ORM框架在处理典型动态查询任务时的开发成本和运行效率。
实验对象
数据集来自Kaggle提供的工资数据 Data Science Salaries,共计 136,757 条记录。每条记录包含工作岗位、薪资、经验、工作类型、公司规模、工作地点等字段,适合构造多种复杂的动态查询场景。
对比框架
| 框架 |
简介 |
| DoytoQuery |
OQM框架,通过声明式查询模型自动构建SQL语句 |
| Spring Data JPA |
Hibernate 封装的高层 ORM 框架 |
| Spring JDBC |
基于 JDBC Template 的底层访问方式 |
| jOOQ |
提供类型安全 SQL 构造的 DSL 框架 |
| MyBatis-plus |
MyBatis 增强工具,自动封装 CRUD |
查询场景
为了覆盖不同类型的查询逻辑,设计了以下三个查询任务:
| 编号 |
描述 |
| T1 |
查询 2025 年薪资在 20,000 和 100,000 之间的记录 |
| URL |
/salary/?workYear=2025&salaryInUsdGt=20000&salaryInUsdLt=100000&pageSize=10 |
| SQL |
SELECT * FROM salary WHERE work_year = ? AND salary_in_usd < ? AND salary_in_usd > ? LIMIT 10 OFFSET 0 |
| T2 |
查询岗位为 "Researcher",薪资小于 30,000 或大于 300,000 的记录 |
| URL |
/salary/?jobTitle=Researcher&or.salaryInUsdLt=30000&or.salaryInUsdGt=300000&pageSize=10 |
| SQL |
SELECT * FROM salary WHERE job_title = ? AND (salary_in_usd < ? OR salary_in_usd > ?) |
| T3 |
查询 2025 年薪资高于 2023 年最大薪资的记录 |
| URL |
/salary/?workYear=2025&salaryInUsdGt0.workYear=2023 |
| SQL |
SELECT * FROM salary WHERE work_year = ? AND salary_in_usd > (SELECT max(salary_in_usd) FROM salary WHERE work_year = ?) |
查询对象统一建模
为了保证对比公平,所有框架均通过统一的查询对象 SalaryQuery 实现参数处理:
public class SalaryQuery extends PageQuery {
private Integer workYear;
private String jobTitle;
private Double salaryInUsdLt;
private Double salaryInUsdGt;
private SalaryQuery or;
private SalaryQuery salaryInUsdGt0;
}
评估指标
- 代码量(Code Size):统计方法代码行数与总体代码行数(LOC),评估代码维护成本。
- 性能(Performance):使用JMH测量每秒处理请求数量(ops/s),评估执行效率。
实验环境
-
硬件:
- CPU: Intel Core i5-13600KF
- 内存: 16GB DDR5
- 存储: 1TB SSD
- GPU: NVIDIA RTX 2060 Super
-
软件:
- 操作系统: Windows 11 Pro
- 数据库: MySQL 8.3.0
- JDK: Amazon Corretto 17.0.5
- Benchmark 工具: JMH 1.37
- 框架版本:Spring Boot 3.5.0、Spring Web 6.2.7 等
-
Benchmark 配置:
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.SECONDS)
@State(Scope.Benchmark)
@Fork(value = 2, jvmArgs = {"-Xms256M", "-Xmx2G", "-XX:+UseG1GC"})
@Threads(8)
@Warmup(iterations = 8, time = 1)
@Measurement(iterations = 3, time = 3)
public class ORMBenchmark { /*...*/ }
实验结果
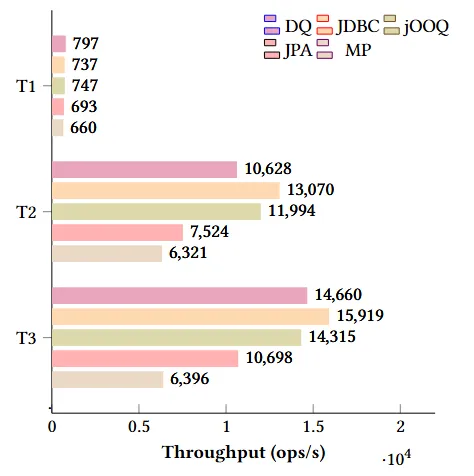
DQ: DoytoQuery JDBC: Spring JDBC JPA: Spring Data JPA MP: MyBatis-Plus
代码量对比
![各框架方法代码量与总代码量对比]()
分析:
- DoytoQuery 基于声明式查询模型,无需编写动态查询构建方法,总代码量远低于其他框架。
- ORM框架都需要通过指令式编程构建SQL语句,构建动态查询的代码量相近。
这里仅对比了查询代码。如果需要实现完整的增删查改接口,Spring JDBC 需要自行拼接SQL语句,代码量最高;Spring Data JPA,jOOQ,MyBatis-Plus都封装了基本的增删查改语句构建,代码量次之;DoytoQuery实现了SQL语句的完全自动化构建,代码量最少。
总体来看,DoytoQuery在代码复用与简洁性上优于传统ORM框架。
性能对比
![各框架在 T1~T3 中的吞吐量(ops/s)]()
分析:
- Spring JDBC由于采用字符串拼接SQL,性能最佳。
- DoytoQuery与jOOQ性能其次。
- Spring Data JPA 和MyBatis-Plus的表现最弱。
总结
实验表明,OQM方法通过声明式查询模型自动构建SQL语句,在代码量上远低于ORM框架。同时,其运行性能接近Spring JDBC,并优于其他ORM框架,验证了OQM方法在实际应用中的可行性与优势。