2025 全球数字经济大会全球开源创新发展论坛邀您共话
2025 全球数字经济大会全球开源创新发展论坛邀您共话
昆仑万维宣布继续开源第二代奖励模型(Reward Model)Skywork-Reward-V2系列,共包含8个基于不同基座模型和不同大小的奖励模型,参数规模从6亿到80亿不等,其在七大主流奖励模型评测榜单中全面夺魁。在2024年9月,昆仑万维曾首次开源了Skywork-Reward系列模型及相关数据集。
公告称,在打造这一新一代奖励模型的过程中,昆仑万维方面构建了一个包含总共4000万对偏好对比的混合数据集Skywork-SynPref-40M。
为实现大规模、高效的数据筛选与过滤,特别设计了人机协同的两阶段流程,将人工标注的高质量与模型的规模化处理能力相结合。在这一流程中,人类提供经过严格验证的高质量标注,大型语言模型(LLMs)则根据人工指导进行自动整理和扩充。
基于上述优质的混合偏好数据开发了Skywork-Reward-V2系列,其展现了广泛的适用性,在多个能力维度上表现出色,包括对人类偏好的通用对齐、客观正确性、安全性、风格偏差的抵抗能力,以及best-of-N扩展能力。经实验验证,该系列模型在七个主流奖励模型评测基准上均获得最佳表现。

相比上一代Skywork-Reward,昆仑万维全新发布的Skywork-Reward-V2系列提供了基于Qwen3和LLaMA3系列模型训练的8个奖励模型,参数规模覆盖从6亿至80亿。

即便基于最小模型Skywork-Reward-V2-Qwen3-0.6B,其整体性能已几乎达到上一代最强模型Skywork-Reward-Gemma-2-27B-v0.2的平均水平。更进一步,Skywork-Reward-V2-Qwen3-1.7B在平均性能上已超越当前开源奖励模型的SOTA——INF-ORM-Llama3.1-70B。而最大规模的Skywork-Reward-V2-Llama-3.1-8B。
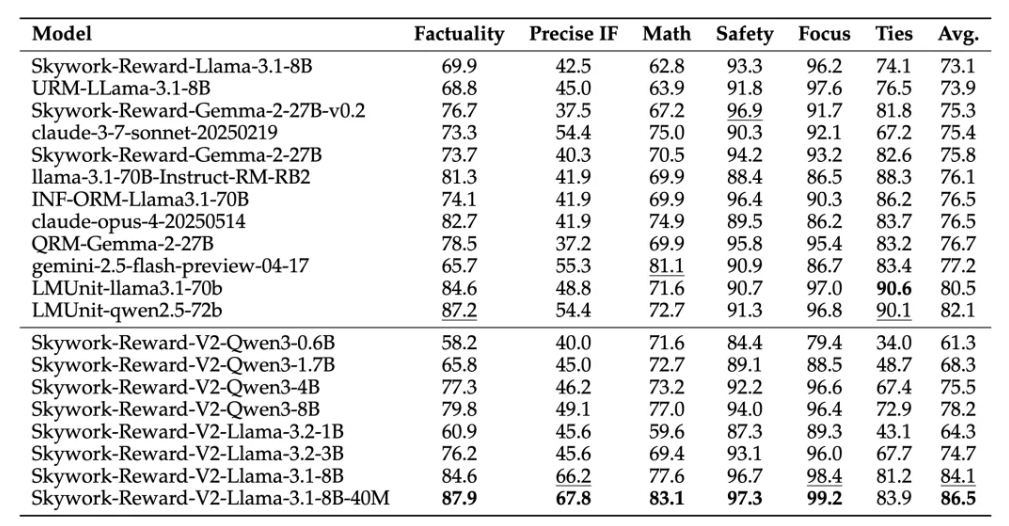
此外,Skywork-Reward-V2在多项高级能力评估中均取得领先成绩:包括Best-of-N(BoN)任务、偏见抵抗能力测试(RM-Bench)、复杂指令理解及真实性判断(RewardBench v2),展现了出色的泛化能力与实用性。
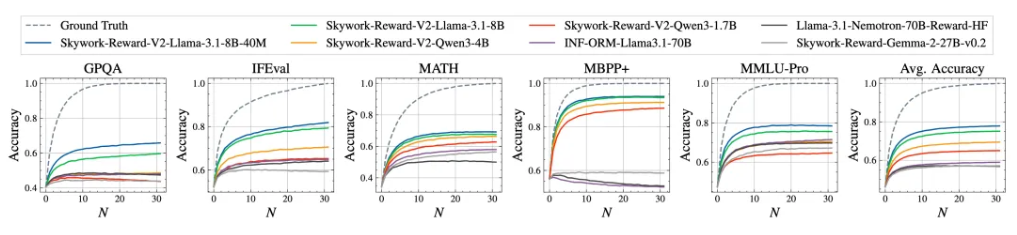
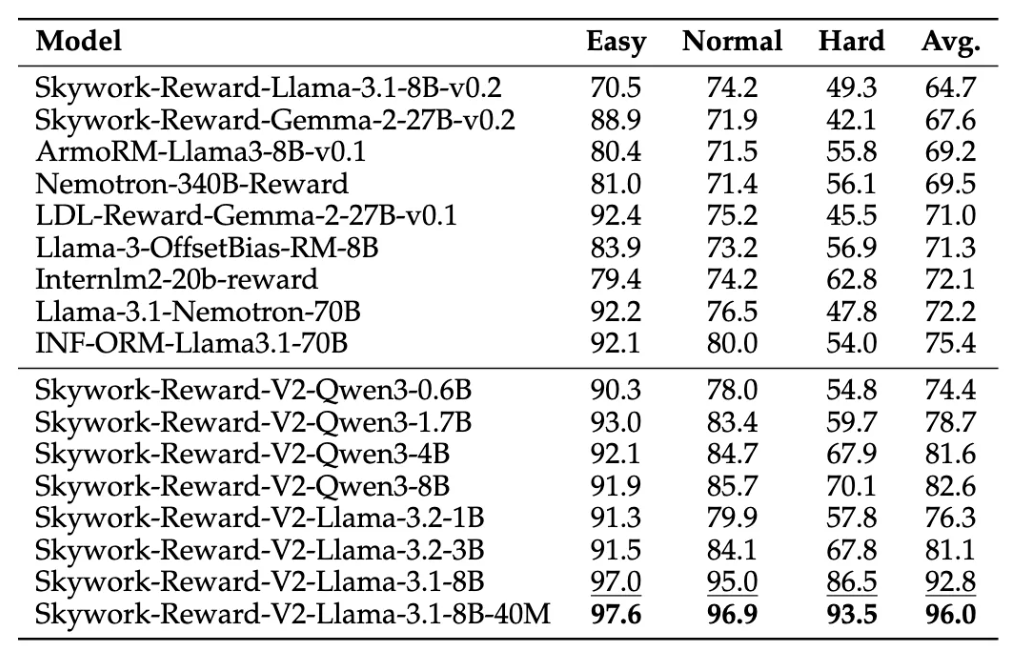
Skywork-Reward-V2系列模型专注于对偏好数据规模扩展的研究,昆仑万维方面表示,其团队也将研究辐射面陆续转向其他尚未被充分探索的领域,例如替代训练技术与建模目标。
更多详情可查看官方公告。

微信关注我们
转载内容版权归作者及来源网站所有!
低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
马里奥是站在游戏界顶峰的超人气多面角色。马里奥靠吃蘑菇成长,特征是大鼻子、头戴帽子、身穿背带裤,还留着胡子。与他的双胞胎兄弟路易基一起,长年担任任天堂的招牌角色。
为解决软件依赖安装时官方源访问速度慢的问题,腾讯云为一些软件搭建了缓存服务。您可以通过使用腾讯云软件源站来提升依赖包的安装速度。为了方便用户自由搭建服务架构,目前腾讯云软件源站支持公网访问和内网访问。
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Sublime Text具有漂亮的用户界面和强大的功能,例如代码缩略图,Python的插件,代码段等。还可自定义键绑定,菜单和工具栏。Sublime Text 的主要功能包括:拼写检查,书签,完整的 Python API , Goto 功能,即时项目切换,多选择,多窗口等等。Sublime Text 是一个跨平台的编辑器,同时支持Windows、Linux、Mac OS X等操作系统。
扫码在手机上查看文章
扫描二维码,手机阅读更方便
有任何问题或合作意向欢迎联系我们
Email: 99873273@qq.com
QQ: 99873273